 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking the Forgery Detection Potential of Vanilla MLLMs: A Novel Training-Free Pipeline
Nov 18, 2025With the rapid advancement of artificial intelligence-generated content (AIGC) technologies, including multimodal large language models (MLLMs) and diffusion models, image generation and manipulation have become remarkably effortless. Existing image forgery detection and localization (IFDL) methods often struggle to generalize across diverse datasets and offer limited interpretability. Nowadays, MLLMs demonstrate strong generalization potential across diverse vision-language tasks, and some studies introduce this capability to IFDL via large-scale training. However, such approaches cost considerable computational resources, while failing to reveal the inherent generalization potential of vanilla MLLMs to address this problem. Inspired by this observation, we propose Foresee, a training-free MLLM-based pipeline tailored for image forgery analysis. It eliminates the need for additional training and enables a lightweight inference process, while surpassing existing MLLM-based methods in both tamper localization accuracy and the richness of textual explanations. Foresee employs a type-prior-driven strategy and utilizes a Flexible Feature Detector (FFD) module to specifically handle copy-move manipulations, thereby effectively unleashing the potential of vanilla MLLMs in the forensic domain. Extensive experiments demonstrate that our approach simultaneously achieves superior localization accuracy and provides more comprehensive textual explanations. Moreover, Foresee exhibits stronger generalization capability, outperforming existing IFDL methods across various tampering types, including copy-move, splicing, removal, local enhancement, deepfake, and AIGC-based editing. The code will be released in the final version.
MediRound: Multi-Round Entity-Level Reasoning Segmentation in Medical Images
Nov 15, 2025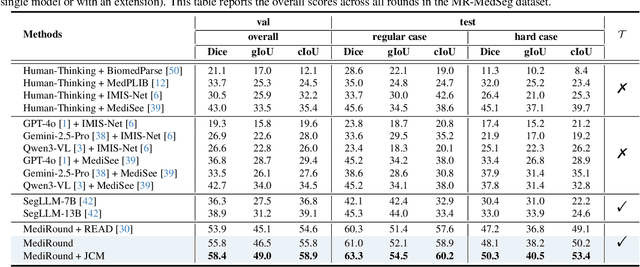
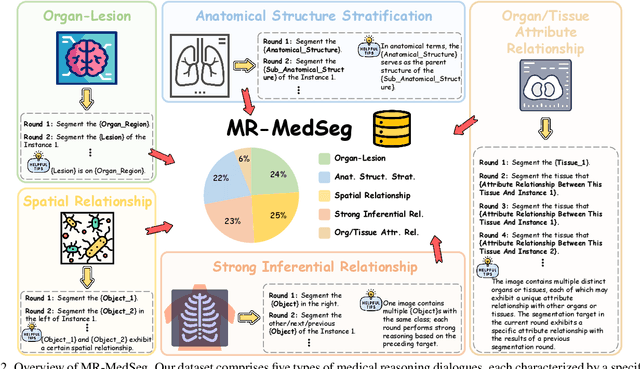
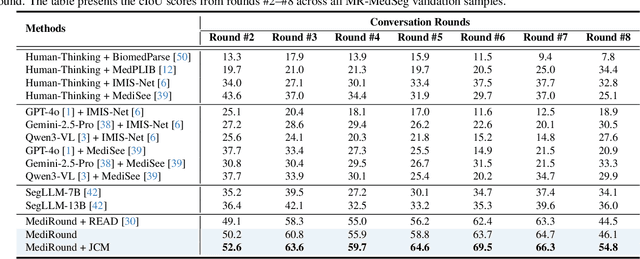
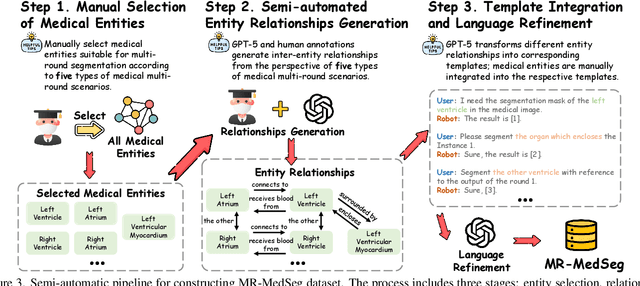
Despite the progress in medical image segmentation, most existing methods remain task-specific and lack interactivity. Although recent text-prompt-based segmentation approaches enhance user-driven and reasoning-based segmentation, they remain confined to single-round dialogues and fail to perform multi-round reasoning. In this work, we introduce Multi-Round Entity-Level Medical Reasoning Segmentation (MEMR-Seg), a new task that requires generating segmentation masks through multi-round queries with entity-level reasoning. To support this task, we construct MR-MedSeg, a large-scale dataset of 177K multi-round medical segmentation dialogues, featuring entity-based reasoning across rounds. Furthermore, we propose MediRound, an effective baseline model designed for multi-round medical reasoning segmentation. To mitigate the inherent error propagation in the chain-like pipeline of multi-round segmentation, we introduce a lightweight yet effective Judgment & Correction Mechanism during model inference. Experimental results demonstrate that our method effectively addresses the MEMR-Seg task and outperforms conventional medical referring segmentation methods.
MediSee: Reasoning-based Pixel-level Perception in Medical Images
Apr 15, 2025Despite remarkable advancements in pixel-level medical image perception, existing methods are either limited to specific tasks or heavily rely on accurate bounding boxes or text labels as input prompts. However, the medical knowledge required for input is a huge obstacle for general public, which greatly reduces the universality of these methods. Compared with these domain-specialized auxiliary information, general users tend to rely on oral queries that require logical reasoning. In this paper, we introduce a novel medical vision task: Medical Reasoning Segmentation and Detection (MedSD), which aims to comprehend implicit queries about medical images and generate the corresponding segmentation mask and bounding box for the target object. To accomplish this task, we first introduce a Multi-perspective, Logic-driven Medical Reasoning Segmentation and Detection (MLMR-SD) dataset, which encompasses a substantial collection of medical entity targets along with their corresponding reasoning. Furthermore, we propose MediSee, an effective baseline model designed for medical reasoning segmentation and detection. The experimental results indicate that the proposed method can effectively address MedSD with implicit colloquial queries and outperform traditional medical referring segmentation methods.
Improving Skeleton-based Action Recognition with Interactive Object Information
Jan 09, 2025Human skeleton information is important in skeleton-based action recognition, which provides a simple and efficient way to describe human pose. However, existing skeleton-based methods focus more on the skeleton, ignoring the objects interacting with humans, resulting in poor performance in recognizing actions that involve object interactions. We propose a new action recognition framework introducing object nodes to supplement absent interactive object information. We also propose Spatial Temporal Variable Graph Convolutional Networks (ST-VGCN) to effectively model the Variable Graph (VG) containing object nodes. Specifically, in order to validate the role of interactive object information, by leveraging a simple self-training approach, we establish a new dataset, JXGC 24, and an extended dataset, NTU RGB+D+Object 60, including more than 2 million additional object nodes. At the same time, we designe the Variable Graph construction method to accommodate a variable number of nodes for graph structure. Additionally, we are the first to explore the overfitting issue introduced by incorporating additional object information, and we propose a VG-based data augmentation method to address this issue, called Random Node Attack. Finally, regarding the network structure, we introduce two fusion modules, CAF and WNPool, along with a novel Node Balance Loss, to enhance the comprehensive performance by effectively fusing and balancing skeleton and object node information. Our method surpasses the previous state-of-the-art on multiple skeleton-based action recognition benchmarks. The accuracy of our method on NTU RGB+D 60 cross-subject split is 96.7\%, and on cross-view split, it is 99.2\%.
Envisioning Class Entity Reasoning by Large Language Models for Few-shot Learning
Aug 22, 2024



Few-shot learning (FSL) aims to recognize new concepts using a limited number of visual samples. Existing approaches attempt to incorporate semantic information into the limited visual data for category understanding. However, these methods often enrich class-level feature representations with abstract category names, failing to capture the nuanced features essential for effective generalization. To address this issue, we propose a novel framework for FSL, which incorporates both the abstract class semantics and the concrete class entities extracted from Large Language Models (LLMs), to enhance the representation of the class prototypes. Specifically, our framework composes a Semantic-guided Visual Pattern Extraction (SVPE) module and a Prototype-Calibration (PC) module, where the SVPE meticulously extracts semantic-aware visual patterns across diverse scales, while the PC module seamlessly integrates these patterns to refine the visual prototype, enhancing its representativeness. Extensive experiments on four few-shot classification benchmarks and the BSCD-FSL cross-domain benchmarks showcase remarkable advancements over the current state-of-the-art methods. Notably, for the challenging one-shot setting, our approach, utilizing the ResNet-12 backbone, achieves an impressive average improvement of 1.95% over the second-best competitor.
CM-UNet: Hybrid CNN-Mamba UNet for Remote Sensing Image Semantic Segmentation
May 17, 2024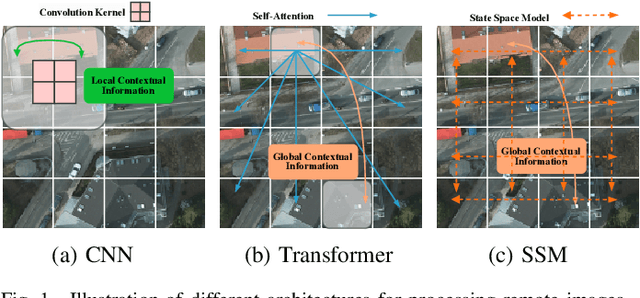
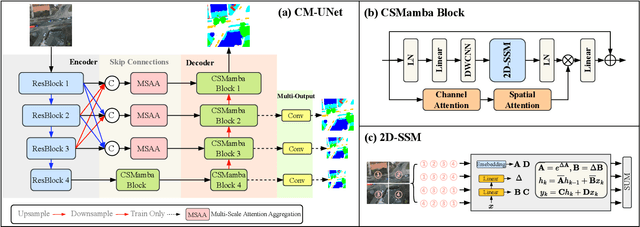
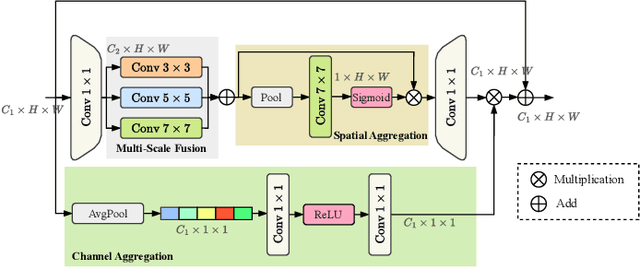
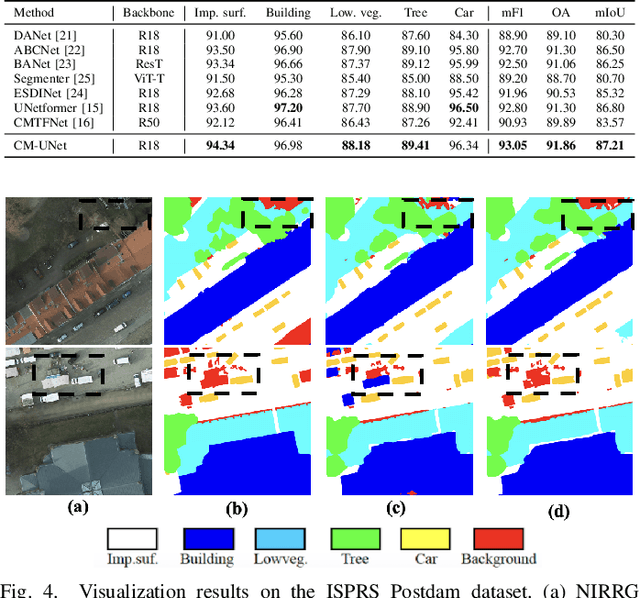
Due to the large-scale image size and object variations, current CNN-based and Transformer-based approaches for remote sensing image semantic segmentation are suboptimal for capturing the long-range dependency or limited to the complex computational complexity. In this paper, we propose CM-UNet, comprising a CNN-based encoder for extracting local image features and a Mamba-based decoder for aggregating and integrating global information, facilitating efficient semantic segmentation of remote sensing images. Specifically, a CSMamba block is introduced to build the core segmentation decoder, which employs channel and spatial attention as the gate activation condition of the vanilla Mamba to enhance the feature interaction and global-local information fusion. Moreover, to further refine the output features from the CNN encoder, a Multi-Scale Attention Aggregation (MSAA) module is employed to merge the different scale features. By integrating the CSMamba block and MSAA module, CM-UNet effectively captures the long-range dependencies and multi-scale global contextual information of large-scale remote-sensing images. Experimental results obtained on three benchmarks indicate that the proposed CM-UNet outperforms existing methods in various performance metrics. The codes are available at https://github.com/XiaoBuL/CM-UNet.
SYNC-CLIP: Synthetic Data Make CLIP Generalize Better in Data-Limited Scenarios
Dec 06, 2023Prompt learning is a powerful technique for transferring Vision-Language Models (VLMs) such as CLIP to downstream tasks. However, the prompt-based methods that are fine-tuned solely with base classes may struggle to generalize to novel classes in open-vocabulary scenarios, especially when data are limited. To address this issue, we propose an innovative approach called SYNC-CLIP that leverages SYNthetiC data for enhancing the generalization capability of CLIP. Based on the observation of the distribution shift between the real and synthetic samples, we treat real and synthetic samples as distinct domains and propose to optimize separate domain prompts to capture domain-specific information, along with the shared visual prompts to preserve the semantic consistency between two domains. By aligning the cross-domain features, the synthetic data from novel classes can provide implicit guidance to rebalance the decision boundaries. Experimental results on three model generalization tasks demonstrate that our method performs very competitively across various benchmarks. Notably, SYNC-CLIP outperforms the state-of-the-art competitor PromptSRC by an average improvement of 3.0% on novel classes across 11 datasets in open-vocabulary scenarios.
Prompt-based test-time real image dehazing: a novel pipeline
Oct 08, 2023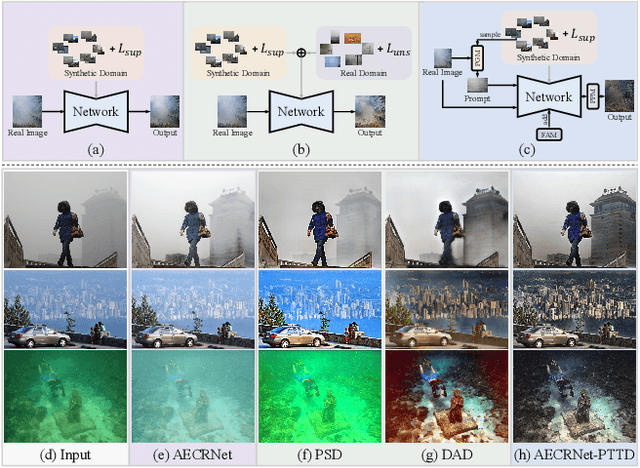
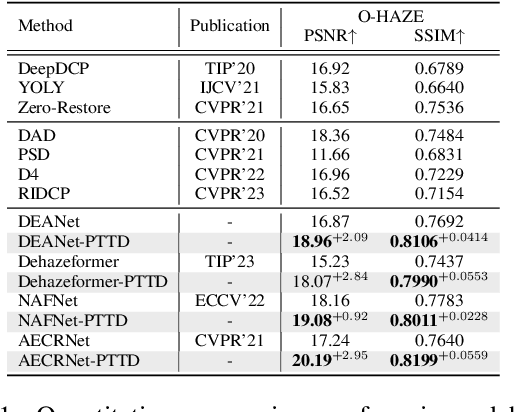

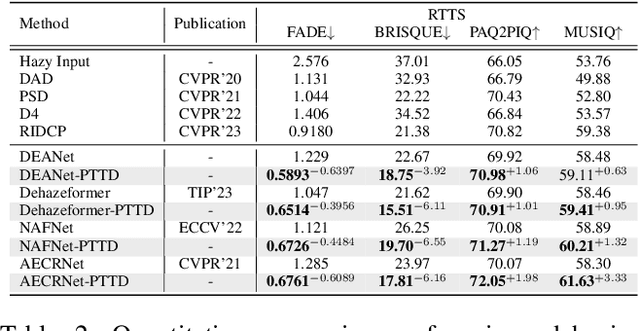
Existing methods attempt to improve models' generalization ability on real-world hazy images by exploring well-designed training schemes (e.g., cycleGAN, prior loss). However, most of them need very complicated training procedures to achieve satisfactory results. In this work, we present a totally novel testing pipeline called Prompt-based Test-Time Dehazing (PTTD) to help generate visually pleasing results of real-captured hazy images during the inference phase. We experimentally find that given a dehazing model trained on synthetic data, by fine-tuning the statistics (i.e., mean and standard deviation) of encoding features, PTTD is able to narrow the domain gap, boosting the performance of real image dehazing. Accordingly, we first apply a prompt generation module (PGM) to generate a visual prompt, which is the source of appropriate statistical perturbations for mean and standard deviation. And then, we employ the feature adaptation module (FAM) into the existing dehazing models for adjusting the original statistics with the guidance of the generated prompt. Note that, PTTD is model-agnostic and can be equipped with various state-of-the-art dehazing models trained on synthetic hazy-clean pairs. Extensive experimental results demonstrate that our PTTD is flexible meanwhile achieves superior performance against state-of-the-art dehazing methods in real-world scenarios. The source code of our PTTD will be made available at https://github.com/cecret3350/PTTD-Dehazing.
Accurate and lightweight dehazing via multi-receptive-field non-local network and novel contrastive regularization
Sep 28, 2023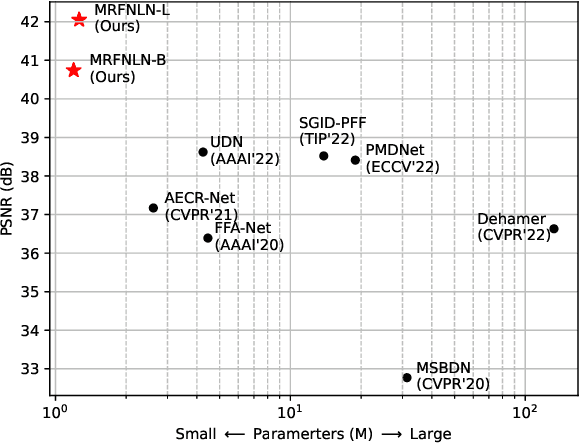
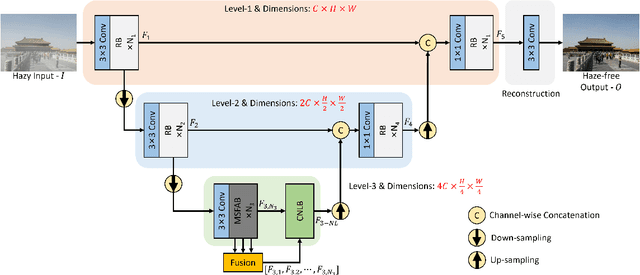
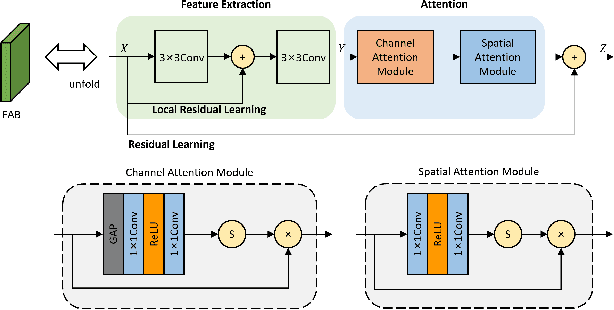
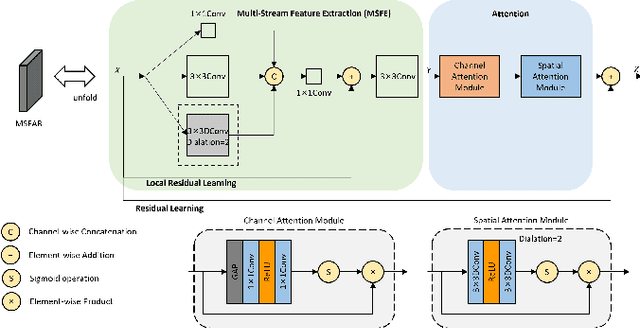
Recently, deep learning-based methods have dominated image dehazing domain. Although very competitive dehazing performance has been achieved with sophisticated models, effective solutions for extracting useful features are still under-explored. In addition, non-local network, which has made a breakthrough in many vision tasks, has not been appropriately applied to image dehazing. Thus, a multi-receptive-field non-local network (MRFNLN) consisting of the multi-stream feature attention block (MSFAB) and cross non-local block (CNLB) is presented in this paper. We start with extracting richer features for dehazing. Specifically, we design a multi-stream feature extraction (MSFE) sub-block, which contains three parallel convolutions with different receptive fields (i.e., $1\times 1$, $3\times 3$, $5\times 5$) for extracting multi-scale features. Following MSFE, we employ an attention sub-block to make the model adaptively focus on important channels/regions. The MSFE and attention sub-blocks constitute our MSFAB. Then, we design a cross non-local block (CNLB), which can capture long-range dependencies beyond the query. Instead of the same input source of query branch, the key and value branches are enhanced by fusing more preceding features. CNLB is computation-friendly by leveraging a spatial pyramid down-sampling (SPDS) strategy to reduce the computation and memory consumption without sacrificing the performance. Last but not least, a novel detail-focused contrastive regularization (DFCR) is presented by emphasizing the low-level details and ignoring the high-level semantic information in the representation space. Comprehensive experimental results demonstrate that the proposed MRFNLN model outperforms recent state-of-the-art dehazing methods with less than 1.5 Million parameters.