 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking the Forgery Detection Potential of Vanilla MLLMs: A Novel Training-Free Pipeline
Nov 18, 2025With the rapid advancement of artificial intelligence-generated content (AIGC) technologies, including multimodal large language models (MLLMs) and diffusion models, image generation and manipulation have become remarkably effortless. Existing image forgery detection and localization (IFDL) methods often struggle to generalize across diverse datasets and offer limited interpretability. Nowadays, MLLMs demonstrate strong generalization potential across diverse vision-language tasks, and some studies introduce this capability to IFDL via large-scale training. However, such approaches cost considerable computational resources, while failing to reveal the inherent generalization potential of vanilla MLLMs to address this problem. Inspired by this observation, we propose Foresee, a training-free MLLM-based pipeline tailored for image forgery analysis. It eliminates the need for additional training and enables a lightweight inference process, while surpassing existing MLLM-based methods in both tamper localization accuracy and the richness of textual explanations. Foresee employs a type-prior-driven strategy and utilizes a Flexible Feature Detector (FFD) module to specifically handle copy-move manipulations, thereby effectively unleashing the potential of vanilla MLLMs in the forensic domain. Extensive experiments demonstrate that our approach simultaneously achieves superior localization accuracy and provides more comprehensive textual explanations. Moreover, Foresee exhibits stronger generalization capability, outperforming existing IFDL methods across various tampering types, including copy-move, splicing, removal, local enhancement, deepfake, and AIGC-based editing. The code will be released in the final version.
MediRound: Multi-Round Entity-Level Reasoning Segmentation in Medical Images
Nov 15, 2025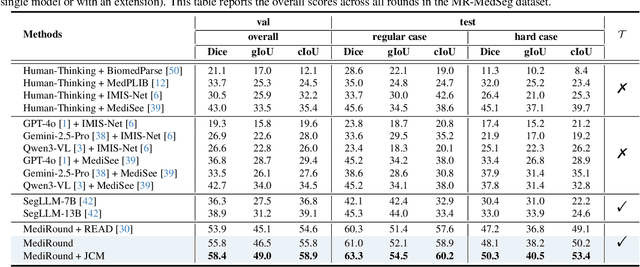
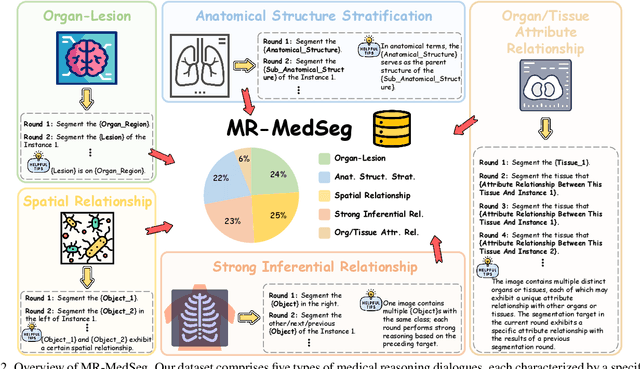
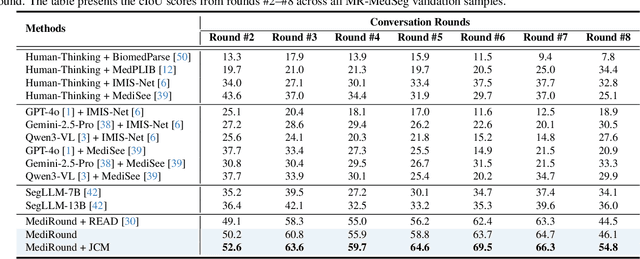
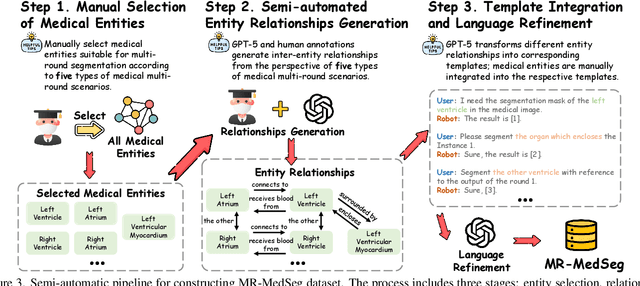
Despite the progress in medical image segmentation, most existing methods remain task-specific and lack interactivity. Although recent text-prompt-based segmentation approaches enhance user-driven and reasoning-based segmentation, they remain confined to single-round dialogues and fail to perform multi-round reasoning. In this work, we introduce Multi-Round Entity-Level Medical Reasoning Segmentation (MEMR-Seg), a new task that requires generating segmentation masks through multi-round queries with entity-level reasoning. To support this task, we construct MR-MedSeg, a large-scale dataset of 177K multi-round medical segmentation dialogues, featuring entity-based reasoning across rounds. Furthermore, we propose MediRound, an effective baseline model designed for multi-round medical reasoning segmentation. To mitigate the inherent error propagation in the chain-like pipeline of multi-round segmentation, we introduce a lightweight yet effective Judgment & Correction Mechanism during model inference. Experimental results demonstrate that our method effectively addresses the MEMR-Seg task and outperforms conventional medical referring segmentation methods.
MediSee: Reasoning-based Pixel-level Perception in Medical Images
Apr 15, 2025Despite remarkable advancements in pixel-level medical image perception, existing methods are either limited to specific tasks or heavily rely on accurate bounding boxes or text labels as input prompts. However, the medical knowledge required for input is a huge obstacle for general public, which greatly reduces the universality of these methods. Compared with these domain-specialized auxiliary information, general users tend to rely on oral queries that require logical reasoning. In this paper, we introduce a novel medical vision task: Medical Reasoning Segmentation and Detection (MedSD), which aims to comprehend implicit queries about medical images and generate the corresponding segmentation mask and bounding box for the target object. To accomplish this task, we first introduce a Multi-perspective, Logic-driven Medical Reasoning Segmentation and Detection (MLMR-SD) dataset, which encompasses a substantial collection of medical entity targets along with their corresponding reasoning. Furthermore, we propose MediSee, an effective baseline model designed for medical reasoning segmentation and detection. The experimental results indicate that the proposed method can effectively address MedSD with implicit colloquial queries and outperform traditional medical referring segmentation methods.