 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt-based test-time real image dehazing: a novel pipeline
Oct 08, 2023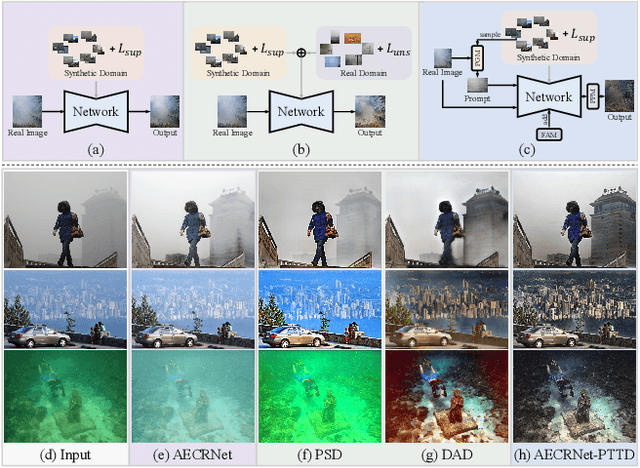
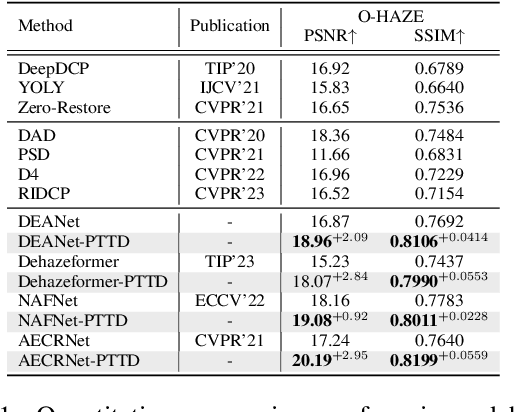

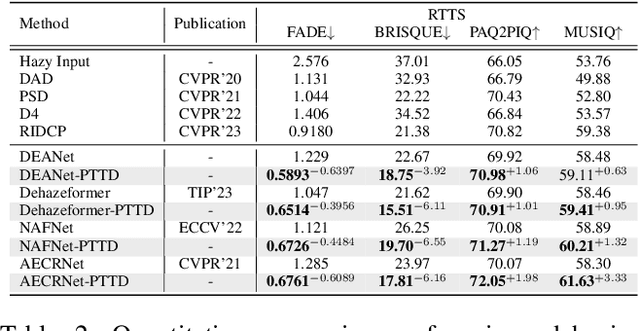
Existing methods attempt to improve models' generalization ability on real-world hazy images by exploring well-designed training schemes (e.g., cycleGAN, prior loss). However, most of them need very complicated training procedures to achieve satisfactory results. In this work, we present a totally novel testing pipeline called Prompt-based Test-Time Dehazing (PTTD) to help generate visually pleasing results of real-captured hazy images during the inference phase. We experimentally find that given a dehazing model trained on synthetic data, by fine-tuning the statistics (i.e., mean and standard deviation) of encoding features, PTTD is able to narrow the domain gap, boosting the performance of real image dehazing. Accordingly, we first apply a prompt generation module (PGM) to generate a visual prompt, which is the source of appropriate statistical perturbations for mean and standard deviation. And then, we employ the feature adaptation module (FAM) into the existing dehazing models for adjusting the original statistics with the guidance of the generated prompt. Note that, PTTD is model-agnostic and can be equipped with various state-of-the-art dehazing models trained on synthetic hazy-clean pairs. Extensive experimental results demonstrate that our PTTD is flexible meanwhile achieves superior performance against state-of-the-art dehazing methods in real-world scenarios. The source code of our PTTD will be made available at https://github.com/cecret3350/PTTD-Dehazing.
Accurate and lightweight dehazing via multi-receptive-field non-local network and novel contrastive regularization
Sep 28, 2023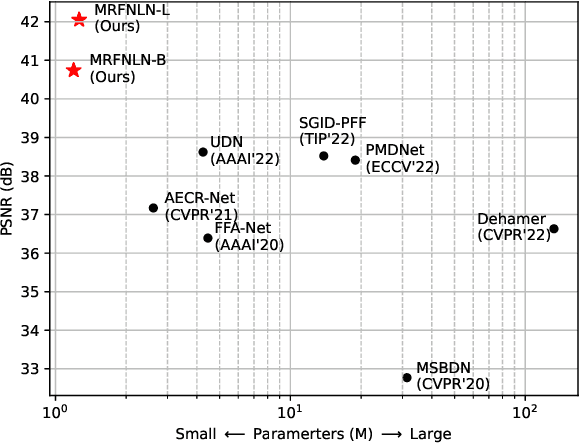
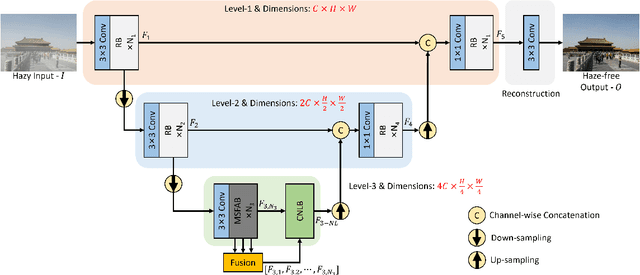
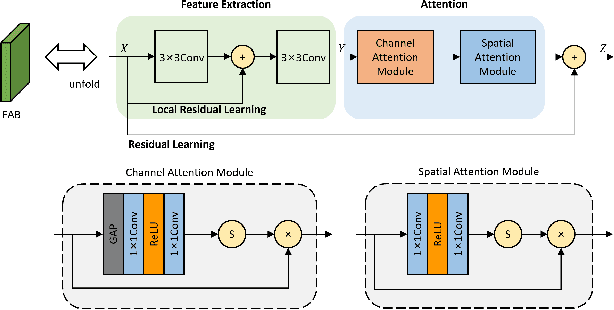
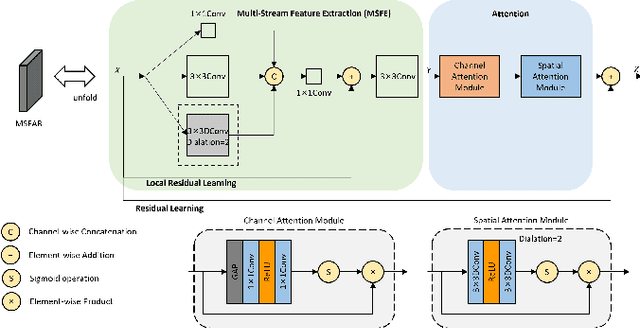
Recently, deep learning-based methods have dominated image dehazing domain. Although very competitive dehazing performance has been achieved with sophisticated models, effective solutions for extracting useful features are still under-explored. In addition, non-local network, which has made a breakthrough in many vision tasks, has not been appropriately applied to image dehazing. Thus, a multi-receptive-field non-local network (MRFNLN) consisting of the multi-stream feature attention block (MSFAB) and cross non-local block (CNLB) is presented in this paper. We start with extracting richer features for dehazing. Specifically, we design a multi-stream feature extraction (MSFE) sub-block, which contains three parallel convolutions with different receptive fields (i.e., $1\times 1$, $3\times 3$, $5\times 5$) for extracting multi-scale features. Following MSFE, we employ an attention sub-block to make the model adaptively focus on important channels/regions. The MSFE and attention sub-blocks constitute our MSFAB. Then, we design a cross non-local block (CNLB), which can capture long-range dependencies beyond the query. Instead of the same input source of query branch, the key and value branches are enhanced by fusing more preceding features. CNLB is computation-friendly by leveraging a spatial pyramid down-sampling (SPDS) strategy to reduce the computation and memory consumption without sacrificing the performance. Last but not least, a novel detail-focused contrastive regularization (DFCR) is presented by emphasizing the low-level details and ignoring the high-level semantic information in the representation space. Comprehensive experimental results demonstrate that the proposed MRFNLN model outperforms recent state-of-the-art dehazing methods with less than 1.5 Million parameters.
DEA-Net: Single image dehazing based on detail-enhanced convolution and content-guided attention
Jan 12, 2023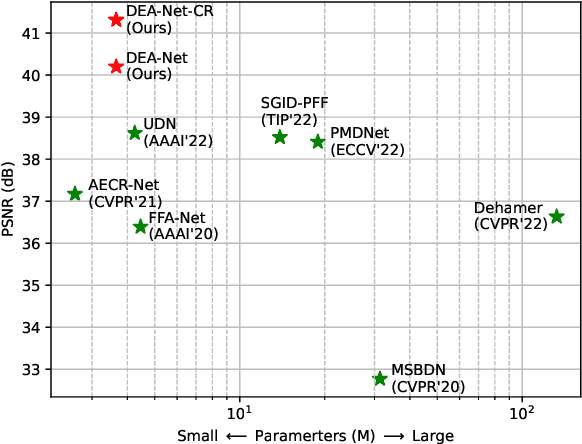


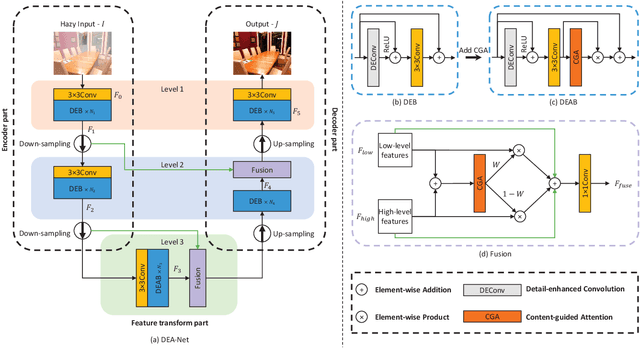
Single image dehazing is a challenging ill-posed problem which estimates latent haze-free images from observed hazy images. Some existing deep learning based methods are devoted to improving the model performance via increasing the depth or width of convolution. The learning ability of convolutional neural network (CNN) structure is still under-explored. In this paper, a detail-enhanced attention block (DEAB) consisting of the detail-enhanced convolution (DEConv) and the content-guided attention (CGA) is proposed to boost the feature learning for improving the dehazing performance. Specifically, the DEConv integrates prior information into normal convolution layer to enhance the representation and generalization capacity. Then by using the re-parameterization technique, DEConv is equivalently converted into a vanilla convolution with NO extra parameters and computational cost. By assigning unique spatial importance map (SIM) to every channel, CGA can attend more useful information encoded in features. In addition, a CGA-based mixup fusion scheme is presented to effectively fuse the features and aid the gradient flow. By combining above mentioned components, we propose our detail-enhanced attention network (DEA-Net) for recovering high-quality haze-free images. Extensive experimental results demonstrate the effectiveness of our DEA-Net, outperforming the state-of-the-art (SOTA) methods by boosting the PSNR index over 41 dB with only 3.653 M parameters. The source code of our DEA-Net will be made available at https://github.com/cecret3350/DEA-Net.
Learning Inter- and Intra-frame Representations for Non-Lambertian Photometric Stereo
Dec 30, 2020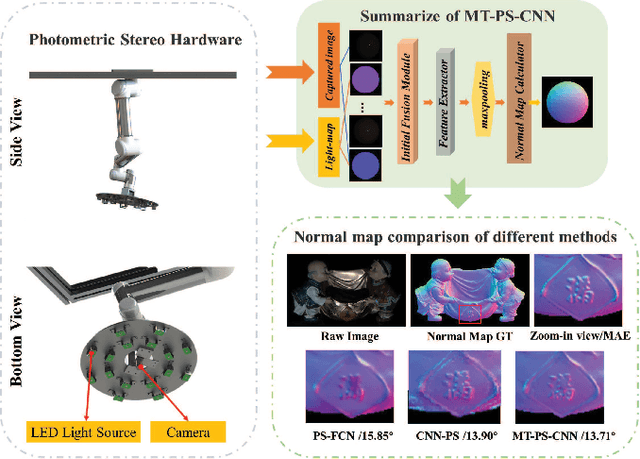

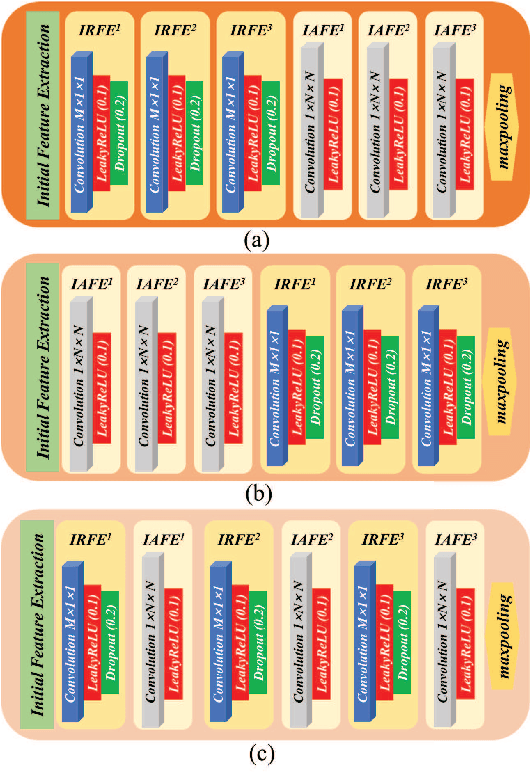
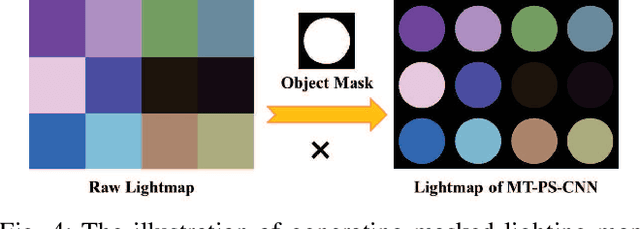
In this paper, we build a two-stage Convolutional Neural Network (CNN) architecture to construct inter- and intra-frame representations based on an arbitrary number of images captured under different light directions, performing accurate normal estimation of non-Lambertian objects. We experimentally investigate numerous network design alternatives for identifying the optimal scheme to deploy inter-frame and intra-frame feature extraction modules for the photometric stereo problem. Moreover, we propose to utilize the easily obtained object mask for eliminating adverse interference from invalid background regions in intra-frame spatial convolutions, thus effectively improve the accuracy of normal estimation for surfaces made of dark materials or with cast shadows. Experimental results demonstrate that proposed masked two-stage photometric stereo CNN model (MT-PS-CNN) performs favorably against state-of-the-art photometric stereo techniques in terms of both accuracy and efficiency. In addition, the proposed method is capable of predicting accurate and rich surface normal details for non-Lambertian objects of complex geometry and performs stably given inputs captured in both sparse and dense lighting distributions.
Deep Neural Network for Fast and Accurate Single Image Super-Resolution via Channel-Attention-based Fusion of Orientation-aware Features
Dec 09, 2019


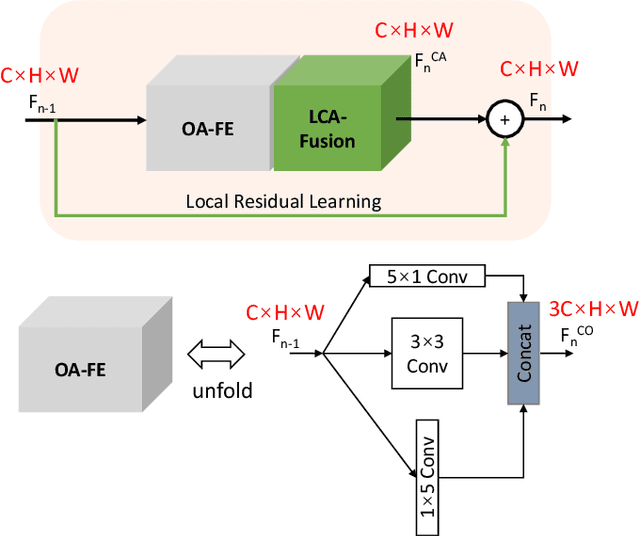
Recently, Convolutional Neural Networks (CNNs) have been successfully adopted to solve the ill-posed single image super-resolution (SISR) problem. A commonly used strategy to boost the performance of CNN-based SISR models is deploying very deep networks, which inevitably incurs many obvious drawbacks (e.g., a large number of network parameters, heavy computational loads, and difficult model training). In this paper, we aim to build more accurate and faster SISR models via developing better-performing feature extraction and fusion techniques. Firstly, we proposed a novel Orientation-Aware feature extraction and fusion Module (OAM), which contains a mixture of 1D and 2D convolutional kernels (i.e., 5 x 1, 1 x 5, and 3 x 3) for extracting orientation-aware features. Secondly, we adopt the channel attention mechanism as an effective technique to adaptively fuse features extracted in different directions and in hierarchically stacked convolutional stages. Based on these two important improvements, we present a compact but powerful CNN-based model for high-quality SISR via Channel Attention-based fusion of Orientation-Aware features (SISR-CA-OA). Extensive experimental results verify the superiority of the proposed SISR-CA-OA model, performing favorably against the state-of-the-art SISR models in terms of both restoration accuracy and computational efficiency. The source codes will be made publicly available.