 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Inter- and Intra-frame Representations for Non-Lambertian Photometric Stereo
Dec 30, 2020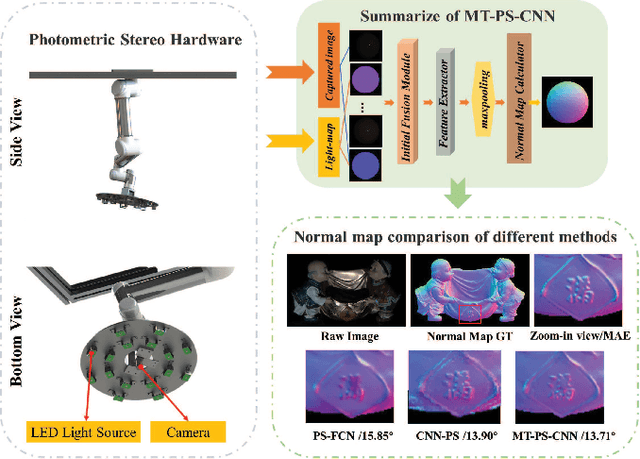

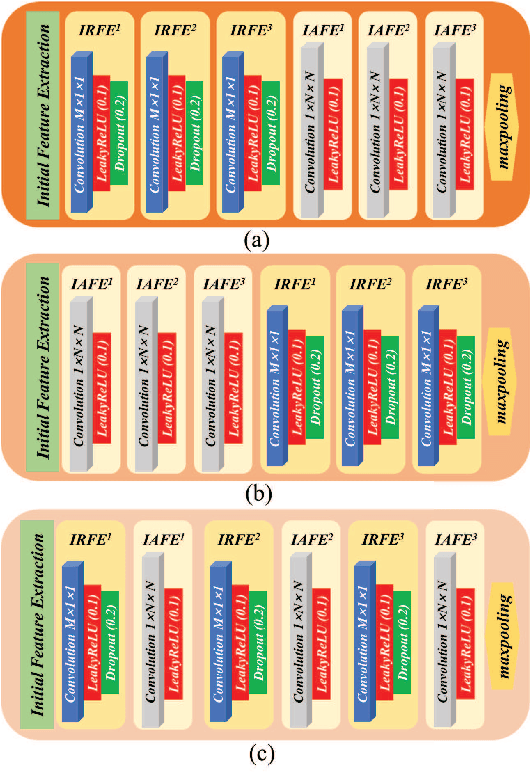
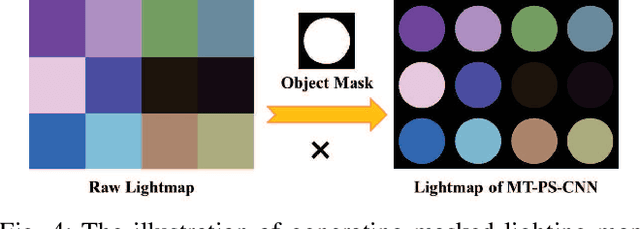
In this paper, we build a two-stage Convolutional Neural Network (CNN) architecture to construct inter- and intra-frame representations based on an arbitrary number of images captured under different light directions, performing accurate normal estimation of non-Lambertian objects. We experimentally investigate numerous network design alternatives for identifying the optimal scheme to deploy inter-frame and intra-frame feature extraction modules for the photometric stereo problem. Moreover, we propose to utilize the easily obtained object mask for eliminating adverse interference from invalid background regions in intra-frame spatial convolutions, thus effectively improve the accuracy of normal estimation for surfaces made of dark materials or with cast shadows. Experimental results demonstrate that proposed masked two-stage photometric stereo CNN model (MT-PS-CNN) performs favorably against state-of-the-art photometric stereo techniques in terms of both accuracy and efficiency. In addition, the proposed method is capable of predicting accurate and rich surface normal details for non-Lambertian objects of complex geometry and performs stably given inputs captured in both sparse and dense lighting distributions.
Boosting Image Super-Resolution Via Fusion of Complementary Information Captured by Multi-Modal Sensors
Dec 07, 2020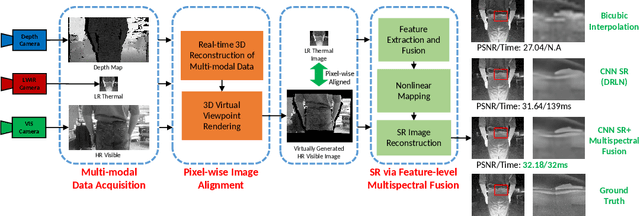

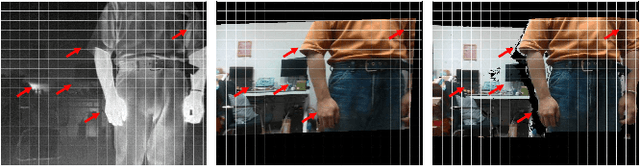
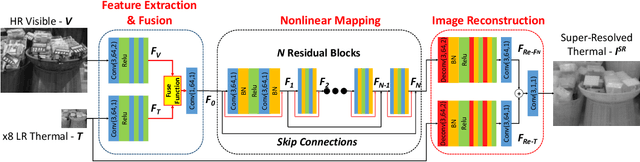
Image Super-Resolution (SR) provides a promising technique to enhance the image quality of low-resolution optical sensors, facilitating better-performing target detection and autonomous navigation in a wide range of robotics applications. It is noted that the state-of-the-art SR methods are typically trained and tested using single-channel inputs, neglecting the fact that the cost of capturing high-resolution images in different spectral domains varies significantly. In this paper, we attempt to leverage complementary information from a low-cost channel (visible/depth) to boost image quality of an expensive channel (thermal) using fewer parameters. To this end, we first present an effective method to virtually generate pixel-wise aligned visible and thermal images based on real-time 3D reconstruction of multi-modal data captured at various viewpoints. Then, we design a feature-level multispectral fusion residual network model to perform high-accuracy SR of thermal images by adaptively integrating co-occurrence features presented in multispectral images. Experimental results demonstrate that this new approach can effectively alleviate the ill-posed inverse problem of image SR by taking into account complementary information from an additional low-cost channel, significantly outperforming state-of-the-art SR approaches in terms of both accuracy and efficiency.
NTIRE 2020 Challenge on Real Image Denoising: Dataset, Methods and Results
May 08, 2020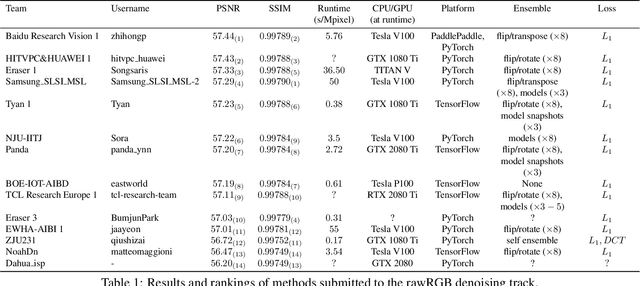
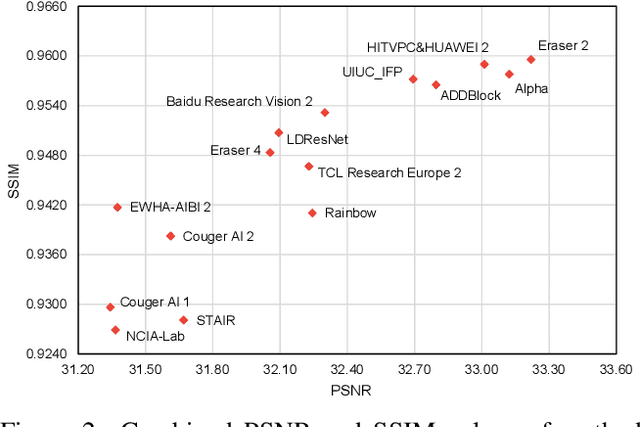
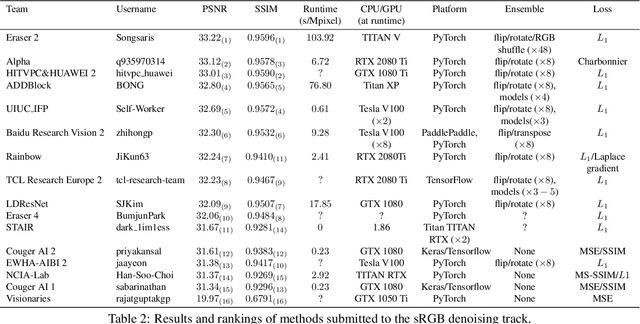
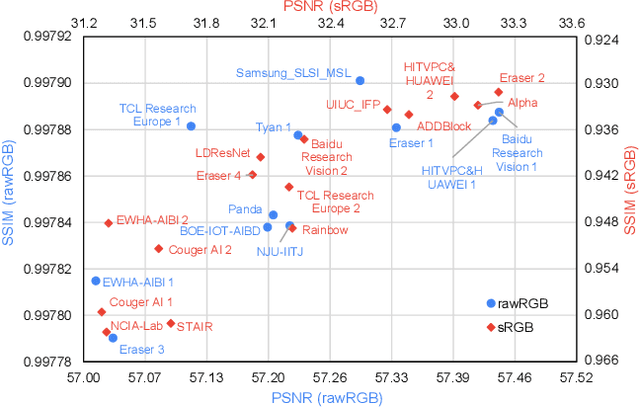
This paper reviews the NTIRE 2020 challenge on real image denoising with focus on the newly introduced dataset, the proposed methods and their results. The challenge is a new version of the previous NTIRE 2019 challenge on real image denoising that was based on the SIDD benchmark. This challenge is based on a newly collected validation and testing image datasets, and hence, named SIDD+. This challenge has two tracks for quantitatively evaluating image denoising performance in (1) the Bayer-pattern rawRGB and (2) the standard RGB (sRGB) color spaces. Each track ~250 registered participants. A total of 22 teams, proposing 24 methods, competed in the final phase of the challenge. The proposed methods by the participating teams represent the current state-of-the-art performance in image denoising targeting real noisy images. The newly collected SIDD+ datasets are publicly available at: https://bit.ly/siddplus_data.
Deep Neural Network for Fast and Accurate Single Image Super-Resolution via Channel-Attention-based Fusion of Orientation-aware Features
Dec 09, 2019


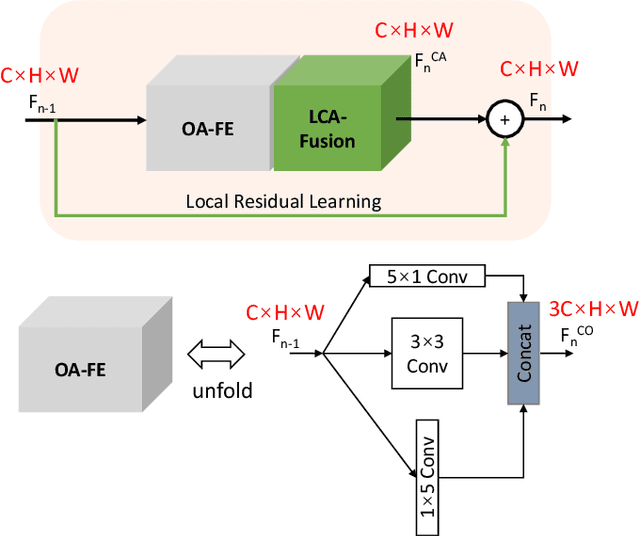
Recently, Convolutional Neural Networks (CNNs) have been successfully adopted to solve the ill-posed single image super-resolution (SISR) problem. A commonly used strategy to boost the performance of CNN-based SISR models is deploying very deep networks, which inevitably incurs many obvious drawbacks (e.g., a large number of network parameters, heavy computational loads, and difficult model training). In this paper, we aim to build more accurate and faster SISR models via developing better-performing feature extraction and fusion techniques. Firstly, we proposed a novel Orientation-Aware feature extraction and fusion Module (OAM), which contains a mixture of 1D and 2D convolutional kernels (i.e., 5 x 1, 1 x 5, and 3 x 3) for extracting orientation-aware features. Secondly, we adopt the channel attention mechanism as an effective technique to adaptively fuse features extracted in different directions and in hierarchically stacked convolutional stages. Based on these two important improvements, we present a compact but powerful CNN-based model for high-quality SISR via Channel Attention-based fusion of Orientation-Aware features (SISR-CA-OA). Extensive experimental results verify the superiority of the proposed SISR-CA-OA model, performing favorably against the state-of-the-art SISR models in terms of both restoration accuracy and computational efficiency. The source codes will be made publicly available.
Unsupervised Domain Adaptation for Multispectral Pedestrian Detection
Apr 07, 2019
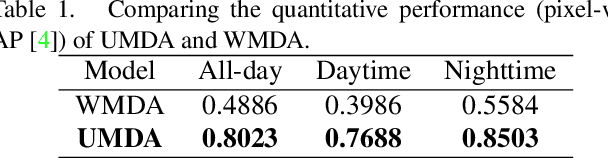
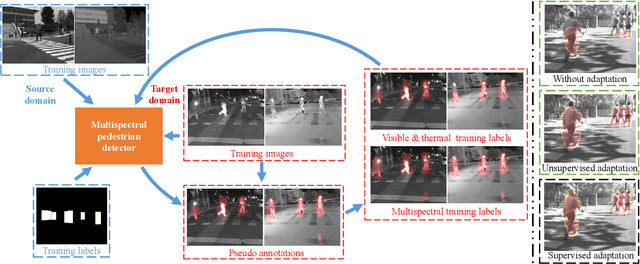

Multimodal information (e.g., visible and thermal) can generate robust pedestrian detections to facilitate around-the-clock computer vision applications, such as autonomous driving and video surveillance. However, it still remains a crucial challenge to train a reliable detector working well in different multispectral pedestrian datasets without manual annotations. In this paper, we propose a novel unsupervised domain adaptation framework for multispectral pedestrian detection, by iteratively generating pseudo annotations and updating the parameters of our designed multispectral pedestrian detector on target domain. Pseudo annotations are generated using the detector trained on source domain, and then updated by fixing the parameters of detector and minimizing the cross entropy loss without back-propagation. Training labels are generated using the pseudo annotations by considering the characteristics of similarity and complementarity between well-aligned visible and infrared image pairs. The parameters of detector are updated using the generated labels by minimizing our defined multi-detection loss function with back-propagation. The optimal parameters of detector can be obtained after iteratively updating the pseudo annotations and parameters. Experimental results show that our proposed unsupervised multimodal domain adaptation method achieves significantly higher detection performance than the approach without domain adaptation, and is competitive with the supervised multispectral pedestrian detectors.
Box-level Segmentation Supervised Deep Neural Networks for Accurate and Real-time Multispectral Pedestrian Detection
Feb 14, 2019



Effective fusion of complementary information captured by multi-modal sensors (visible and infrared cameras) enables robust pedestrian detection under various surveillance situations (e.g. daytime and nighttime). In this paper, we present a novel box-level segmentation supervised learning framework for accurate and real-time multispectral pedestrian detection by incorporating features extracted in visible and infrared channels. Specifically, our method takes pairs of aligned visible and infrared images with easily obtained bounding box annotations as input and estimates accurate prediction maps to highlight the existence of pedestrians. It offers two major advantages over the existing anchor box based multispectral detection methods. Firstly, it overcomes the hyperparameter setting problem occurred during the training phase of anchor box based detectors and can obtain more accurate detection results, especially for small and occluded pedestrian instances. Secondly, it is capable of generating accurate detection results using small-size input images, leading to improvement of computational efficiency for real-time autonomous driving applications. Experimental results on KAIST multispectral dataset show that our proposed method outperforms state-of-the-art approaches in terms of both accuracy and speed.
Fusion of Multispectral Data Through Illumination-aware Deep Neural Networks for Pedestrian Detection
Feb 27, 2018

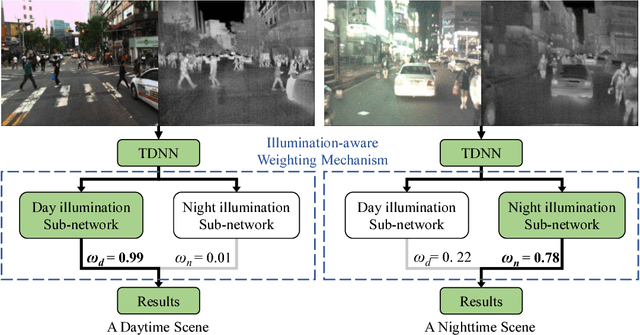
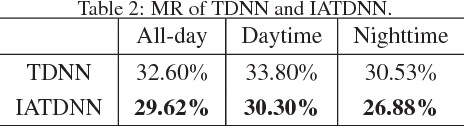
Multispectral pedestrian detection has received extensive attention in recent years as a promising solution to facilitate robust human target detection for around-the-clock applications (e.g. security surveillance and autonomous driving). In this paper, we demonstrate illumination information encoded in multispectral images can be utilized to significantly boost performance of pedestrian detection. A novel illumination-aware weighting mechanism is present to accurately depict illumination condition of a scene. Such illumination information is incorporated into two-stream deep convolutional neural networks to learn multispectral human-related features under different illumination conditions (daytime and nighttime). Moreover, we utilized illumination information together with multispectral data to generate more accurate semantic segmentation which are used to boost pedestrian detection accuracy. Putting all of the pieces together, we present a powerful framework for multispectral pedestrian detection based on multi-task learning of illumination-aware pedestrian detection and semantic segmentation. Our proposed method is trained end-to-end using a well-designed multi-task loss function and outperforms state-of-the-art approaches on KAIST multispectral pedestrian dataset.