 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Skeleton-based Action Recognition with Interactive Object Information
Jan 09, 2025Human skeleton information is important in skeleton-based action recognition, which provides a simple and efficient way to describe human pose. However, existing skeleton-based methods focus more on the skeleton, ignoring the objects interacting with humans, resulting in poor performance in recognizing actions that involve object interactions. We propose a new action recognition framework introducing object nodes to supplement absent interactive object information. We also propose Spatial Temporal Variable Graph Convolutional Networks (ST-VGCN) to effectively model the Variable Graph (VG) containing object nodes. Specifically, in order to validate the role of interactive object information, by leveraging a simple self-training approach, we establish a new dataset, JXGC 24, and an extended dataset, NTU RGB+D+Object 60, including more than 2 million additional object nodes. At the same time, we designe the Variable Graph construction method to accommodate a variable number of nodes for graph structure. Additionally, we are the first to explore the overfitting issue introduced by incorporating additional object information, and we propose a VG-based data augmentation method to address this issue, called Random Node Attack. Finally, regarding the network structure, we introduce two fusion modules, CAF and WNPool, along with a novel Node Balance Loss, to enhance the comprehensive performance by effectively fusing and balancing skeleton and object node information. Our method surpasses the previous state-of-the-art on multiple skeleton-based action recognition benchmarks. The accuracy of our method on NTU RGB+D 60 cross-subject split is 96.7\%, and on cross-view split, it is 99.2\%.
ALL-IN-ONE: Multi-Task Learning BERT models for Evaluating Peer Assessments
Oct 08, 2021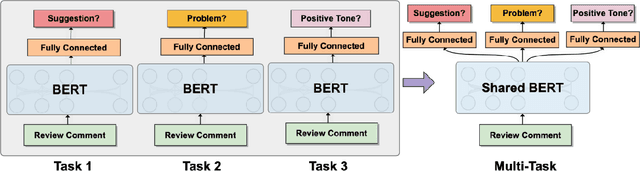
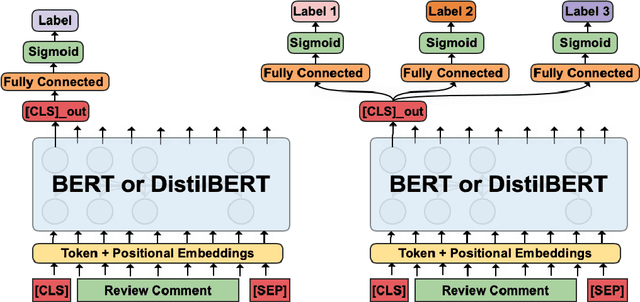
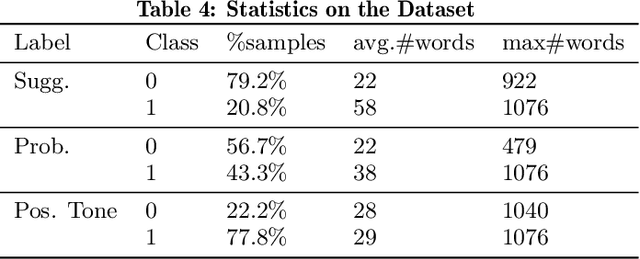
Peer assessment has been widely applied across diverse academic fields over the last few decades and has demonstrated its effectiveness. However, the advantages of peer assessment can only be achieved with high-quality peer reviews. Previous studies have found that high-quality review comments usually comprise several features (e.g., contain suggestions, mention problems, use a positive tone). Thus, researchers have attempted to evaluate peer-review comments by detecting different features using various machine learning and deep learning models. However, there is no single study that investigates using a multi-task learning (MTL) model to detect multiple features simultaneously. This paper presents two MTL models for evaluating peer-review comments by leveraging the state-of-the-art pre-trained language representation models BERT and DistilBERT. Our results demonstrate that BERT-based models significantly outperform previous GloVe-based methods by around 6% in F1-score on tasks of detecting a single feature, and MTL further improves performance while reducing model size.