 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-LMM Post-Training: A Deep Dive into Video Reasoning with Large Multimodal Models
Oct 06, 2025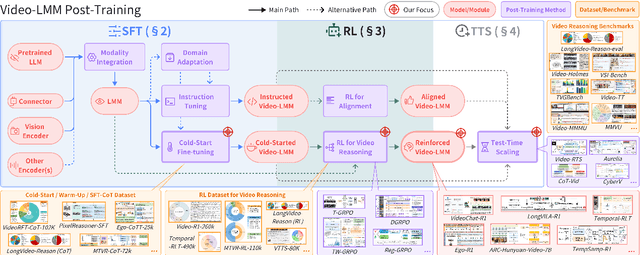
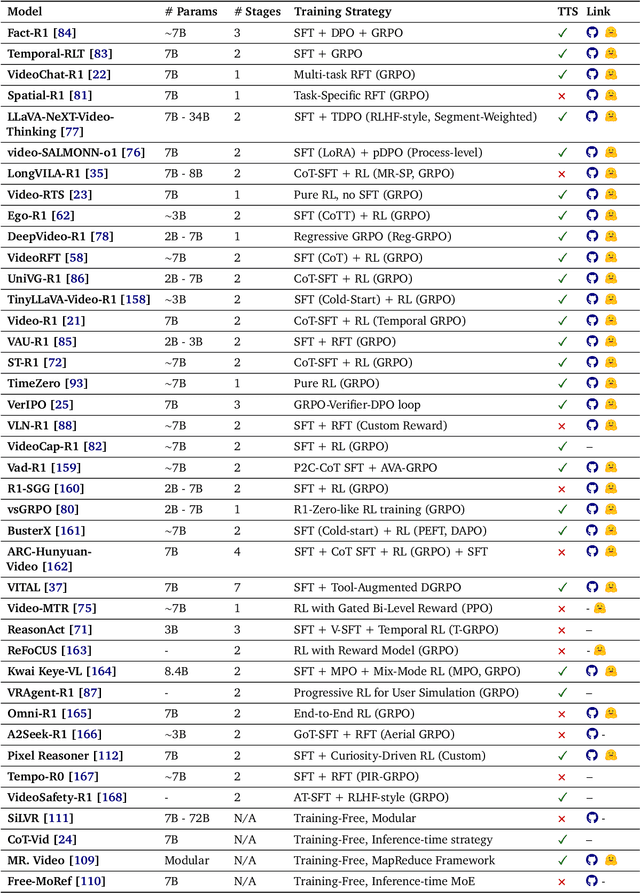
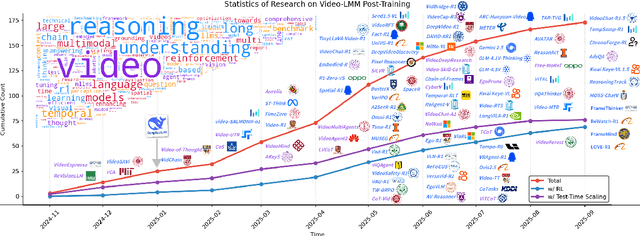
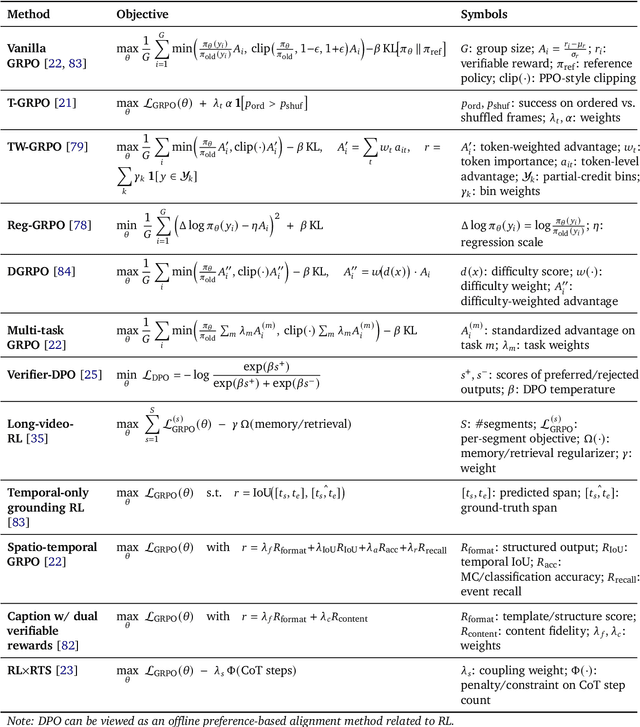
Video understanding represents the most challenging frontier in computer vision, requiring models to reason about complex spatiotemporal relationships, long-term dependencies, and multimodal evidence. The recent emergence of Video-Large Multimodal Models (Video-LMMs), which integrate visual encoders with powerful decoder-based language models, has demonstrated remarkable capabilities in video understanding tasks. However, the critical phase that transforms these models from basic perception systems into sophisticated reasoning engines, post-training, remains fragmented across the literature. This survey provides the first comprehensive examination of post-training methodologies for Video-LMMs, encompassing three fundamental pillars: supervised fine-tuning (SFT) with chain-of-thought, reinforcement learning (RL) from verifiable objectives, and test-time scaling (TTS) through enhanced inference computation. We present a structured taxonomy that clarifies the roles, interconnections, and video-specific adaptations of these techniques, addressing unique challenges such as temporal localization, spatiotemporal grounding, long video efficiency, and multimodal evidence integration. Through systematic analysis of representative methods, we synthesize key design principles, insights, and evaluation protocols while identifying critical open challenges in reward design, scalability, and cost-performance optimization. We further curate essential benchmarks, datasets, and metrics to facilitate rigorous assessment of post-training effectiveness. This survey aims to provide researchers and practitioners with a unified framework for advancing Video-LMM capabilities. Additional resources and updates are maintained at: https://github.com/yunlong10/Awesome-Video-LMM-Post-Training
SoccerNet 2025 Challenges Results
Aug 26, 2025The SoccerNet 2025 Challenges mark the fifth annual edition of the SoccerNet open benchmarking effort, dedicated to advancing computer vision research in football video understanding. This year's challenges span four vision-based tasks: (1) Team Ball Action Spotting, focused on detecting ball-related actions in football broadcasts and assigning actions to teams; (2) Monocular Depth Estimation, targeting the recovery of scene geometry from single-camera broadcast clips through relative depth estimation for each pixel; (3) Multi-View Foul Recognition, requiring the analysis of multiple synchronized camera views to classify fouls and their severity; and (4) Game State Reconstruction, aimed at localizing and identifying all players from a broadcast video to reconstruct the game state on a 2D top-view of the field. Across all tasks, participants were provided with large-scale annotated datasets, unified evaluation protocols, and strong baselines as starting points. This report presents the results of each challenge, highlights the top-performing solutions, and provides insights into the progress made by the community. The SoccerNet Challenges continue to serve as a driving force for reproducible, open research at the intersection of computer vision, artificial intelligence, and sports. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
CAMA: Enhancing Multimodal In-Context Learning with Context-Aware Modulated Attention
May 21, 2025Multimodal in-context learning (ICL) enables large vision-language models (LVLMs) to efficiently adapt to novel tasks, supporting a wide array of real-world applications. However, multimodal ICL remains unstable, and current research largely focuses on optimizing sequence configuration while overlooking the internal mechanisms of LVLMs. In this work, we first provide a theoretical analysis of attentional dynamics in multimodal ICL and identify three core limitations of standard attention that ICL impair performance. To address these challenges, we propose Context-Aware Modulated Attention (CAMA), a simple yet effective plug-and-play method for directly calibrating LVLM attention logits. CAMA is training-free and can be seamlessly applied to various open-source LVLMs. We evaluate CAMA on four LVLMs across six benchmarks, demonstrating its effectiveness and generality. CAMA opens new opportunities for deeper exploration and targeted utilization of LVLM attention dynamics to advance multimodal reasoning.
VEU-Bench: Towards Comprehensive Understanding of Video Editing
Apr 24, 2025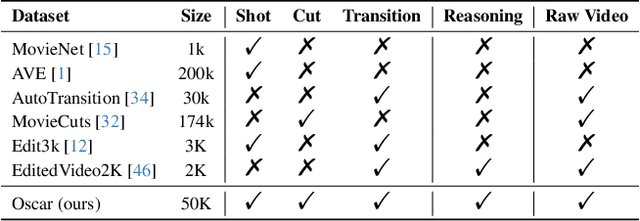
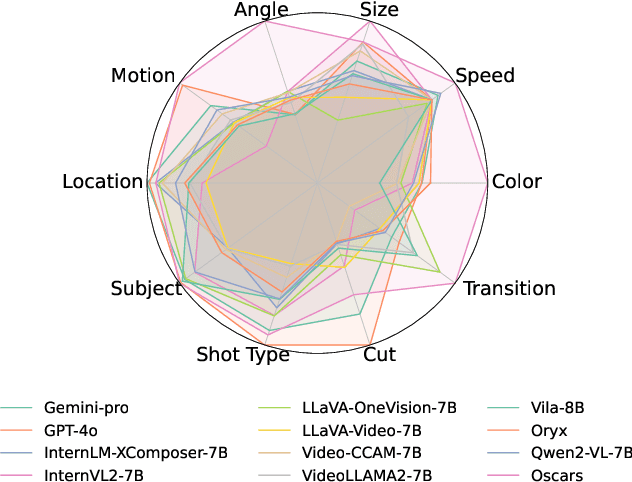
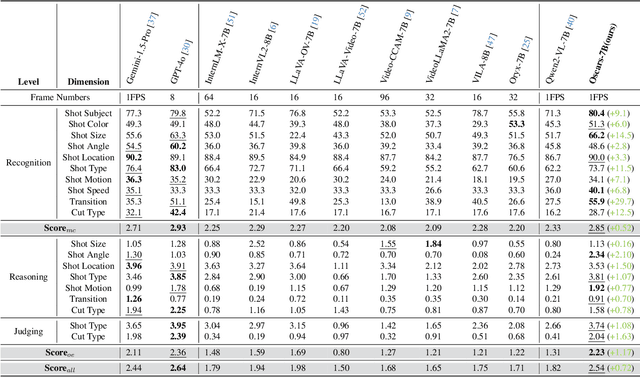
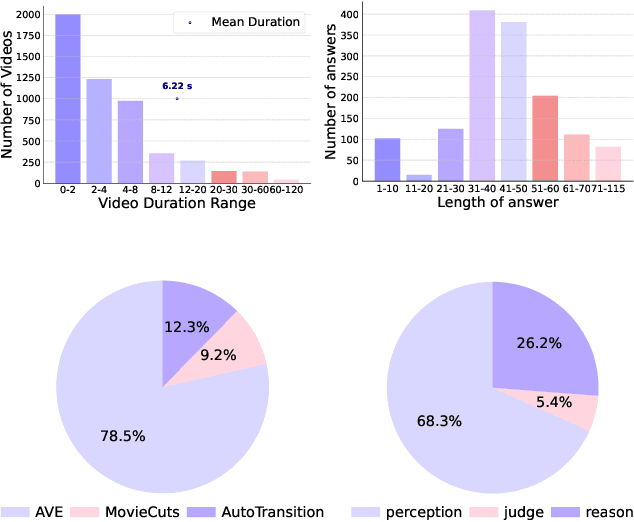
Widely shared videos on the internet are often edited. Recently, although Video Large Language Models (Vid-LLMs) have made great progress in general video understanding tasks, their capabilities in video editing understanding (VEU) tasks remain unexplored. To address this gap, in this paper, we introduce VEU-Bench (Video Editing Understanding Benchmark), a comprehensive benchmark that categorizes video editing components across various dimensions, from intra-frame features like shot size to inter-shot attributes such as cut types and transitions. Unlike previous video editing understanding benchmarks that focus mainly on editing element classification, VEU-Bench encompasses 19 fine-grained tasks across three stages: recognition, reasoning, and judging. To enhance the annotation of VEU automatically, we built an annotation pipeline integrated with an ontology-based knowledge base. Through extensive experiments with 11 state-of-the-art Vid-LLMs, our findings reveal that current Vid-LLMs face significant challenges in VEU tasks, with some performing worse than random choice. To alleviate this issue, we develop Oscars, a VEU expert model fine-tuned on the curated VEU-Bench dataset. It outperforms existing open-source Vid-LLMs on VEU-Bench by over 28.3% in accuracy and achieves performance comparable to commercial models like GPT-4o. We also demonstrate that incorporating VEU data significantly enhances the performance of Vid-LLMs on general video understanding benchmarks, with an average improvement of 8.3% across nine reasoning tasks.
Video Repurposing from User Generated Content: A Large-scale Dataset and Benchmark
Dec 12, 2024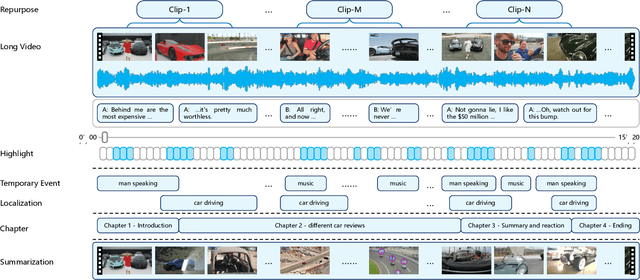
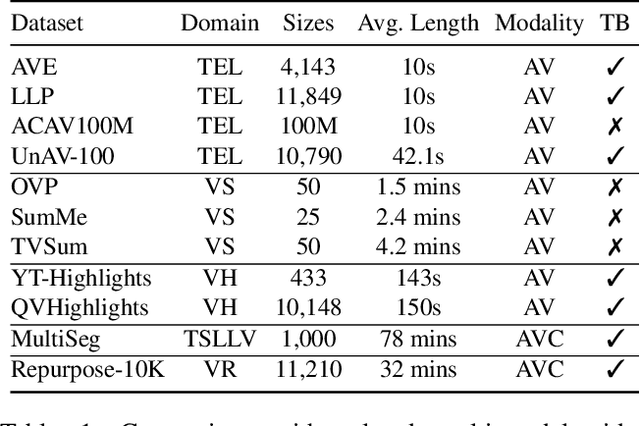
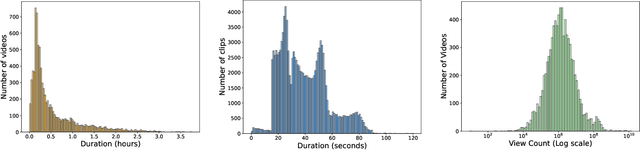
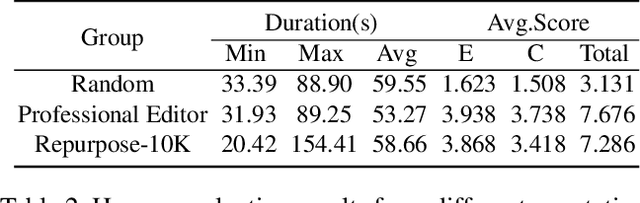
The demand for producing short-form videos for sharing on social media platforms has experienced significant growth in recent times. Despite notable advancements in the fields of video summarization and highlight detection, which can create partially usable short films from raw videos, these approaches are often domain-specific and require an in-depth understanding of real-world video content. To tackle this predicament, we propose Repurpose-10K, an extensive dataset comprising over 10,000 videos with more than 120,000 annotated clips aimed at resolving the video long-to-short task. Recognizing the inherent constraints posed by untrained human annotators, which can result in inaccurate annotations for repurposed videos, we propose a two-stage solution to obtain annotations from real-world user-generated content. Furthermore, we offer a baseline model to address this challenging task by integrating audio, visual, and caption aspects through a cross-modal fusion and alignment framework. We aspire for our work to ignite groundbreaking research in the lesser-explored realms of video repurposing. The code and data will be available at https://github.com/yongliang-wu/Repurpose.
Envisioning Class Entity Reasoning by Large Language Models for Few-shot Learning
Aug 22, 2024



Few-shot learning (FSL) aims to recognize new concepts using a limited number of visual samples. Existing approaches attempt to incorporate semantic information into the limited visual data for category understanding. However, these methods often enrich class-level feature representations with abstract category names, failing to capture the nuanced features essential for effective generalization. To address this issue, we propose a novel framework for FSL, which incorporates both the abstract class semantics and the concrete class entities extracted from Large Language Models (LLMs), to enhance the representation of the class prototypes. Specifically, our framework composes a Semantic-guided Visual Pattern Extraction (SVPE) module and a Prototype-Calibration (PC) module, where the SVPE meticulously extracts semantic-aware visual patterns across diverse scales, while the PC module seamlessly integrates these patterns to refine the visual prototype, enhancing its representativeness. Extensive experiments on four few-shot classification benchmarks and the BSCD-FSL cross-domain benchmarks showcase remarkable advancements over the current state-of-the-art methods. Notably, for the challenging one-shot setting, our approach, utilizing the ResNet-12 backbone, achieves an impressive average improvement of 1.95% over the second-best competitor.
Frame Order Matters: A Temporal Sequence-Aware Model for Few-Shot Action Recognition
Aug 22, 2024In this paper, we propose a novel Temporal Sequence-Aware Model (TSAM) for few-shot action recognition (FSAR), which incorporates a sequential perceiver adapter into the pre-training framework, to integrate both the spatial information and the sequential temporal dynamics into the feature embeddings. Different from the existing fine-tuning approaches that capture temporal information by exploring the relationships among all the frames, our perceiver-based adapter recurrently captures the sequential dynamics alongside the timeline, which could perceive the order change. To obtain the discriminative representations for each class, we extend a textual corpus for each class derived from the large language models (LLMs) and enrich the visual prototypes by integrating the contextual semantic information. Besides, We introduce an unbalanced optimal transport strategy for feature matching that mitigates the impact of class-unrelated features, thereby facilitating more effective decision-making. Experimental results on five FSAR datasets demonstrate that our method set a new benchmark, beating the second-best competitors with large margins.
OmniCLIP: Adapting CLIP for Video Recognition with Spatial-Temporal Omni-Scale Feature Learning
Aug 12, 2024Recent Vision-Language Models (VLMs) \textit{e.g.} CLIP have made great progress in video recognition. Despite the improvement brought by the strong visual backbone in extracting spatial features, CLIP still falls short in capturing and integrating spatial-temporal features which is essential for video recognition. In this paper, we propose OmniCLIP, a framework that adapts CLIP for video recognition by focusing on learning comprehensive features encompassing spatial, temporal, and dynamic spatial-temporal scales, which we refer to as omni-scale features. This is achieved through the design of spatial-temporal blocks that include parallel temporal adapters (PTA), enabling efficient temporal modeling. Additionally, we introduce a self-prompt generator (SPG) module to capture dynamic object spatial features. The synergy between PTA and SPG allows OmniCLIP to discern varying spatial information across frames and assess object scales over time. We have conducted extensive experiments in supervised video recognition, few-shot video recognition, and zero-shot recognition tasks. The results demonstrate the effectiveness of our method, especially with OmniCLIP achieving a top-1 accuracy of 74.30\% on HMDB51 in a 16-shot setting, surpassing the recent MotionPrompt approach even with full training data. The code is available at \url{https://github.com/XiaoBuL/OmniCLIP}.
Fully Fine-tuned CLIP Models are Efficient Few-Shot Learners
Jul 04, 2024Prompt tuning, which involves training a small set of parameters, effectively enhances the pre-trained Vision-Language Models (VLMs) to downstream tasks. However, they often come at the cost of flexibility and adaptability when the tuned models are applied to different datasets or domains. In this paper, we explore capturing the task-specific information via meticulous refinement of entire VLMs, with minimal parameter adjustments. When fine-tuning the entire VLMs for specific tasks under limited supervision, overfitting and catastrophic forgetting become the defacto factors. To mitigate these issues, we propose a framework named CLIP-CITE via designing a discriminative visual-text task, further aligning the visual-text semantics in a supervision manner, and integrating knowledge distillation techniques to preserve the gained knowledge. Extensive experimental results under few-shot learning, base-to-new generalization, domain generalization, and cross-domain generalization settings, demonstrate that our method effectively enhances the performance on specific tasks under limited supervision while preserving the versatility of the VLMs on other datasets.
Zero-Shot Long-Form Video Understanding through Screenplay
Jun 25, 2024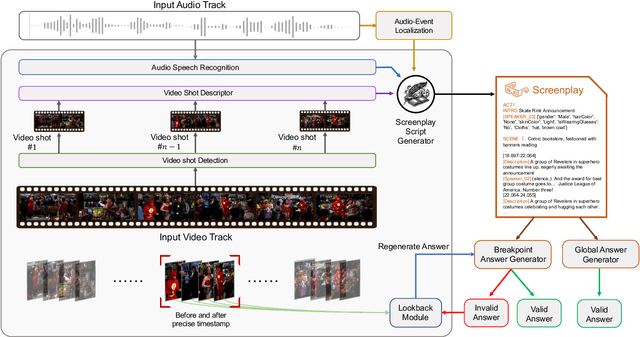
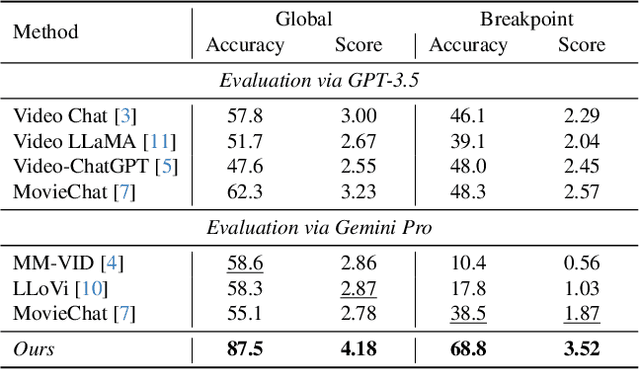
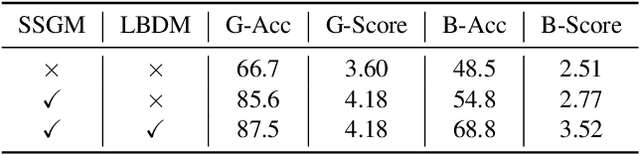

The Long-form Video Question-Answering task requires the comprehension and analysis of extended video content to respond accurately to questions by utilizing both temporal and contextual information. In this paper, we present MM-Screenplayer, an advanced video understanding system with multi-modal perception capabilities that can convert any video into textual screenplay representations. Unlike previous storytelling methods, we organize video content into scenes as the basic unit, rather than just visually continuous shots. Additionally, we developed a ``Look Back'' strategy to reassess and validate uncertain information, particularly targeting breakpoint mode. MM-Screenplayer achieved highest score in the CVPR'2024 LOng-form VidEo Understanding (LOVEU) Track 1 Challenge, with a global accuracy of 87.5% and a breakpoint accuracy of 68.8%.