 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Long-Form Video Understanding through Screenplay
Paper and Code
Jun 25, 2024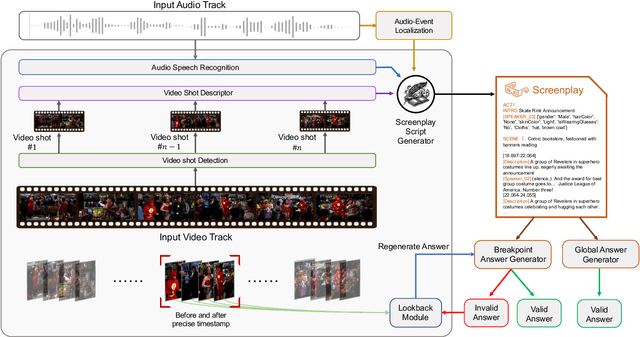
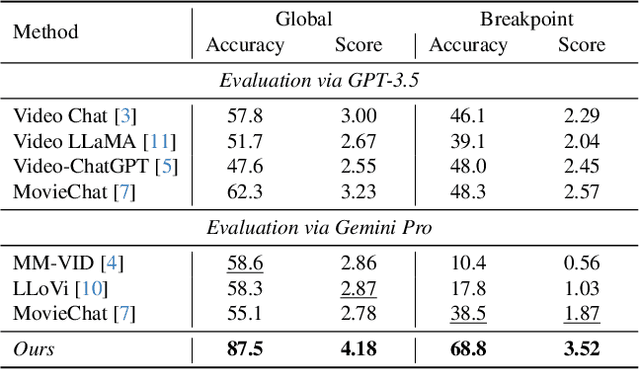
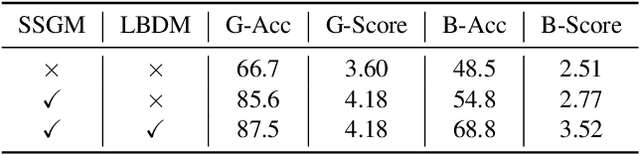

The Long-form Video Question-Answering task requires the comprehension and analysis of extended video content to respond accurately to questions by utilizing both temporal and contextual information. In this paper, we present MM-Screenplayer, an advanced video understanding system with multi-modal perception capabilities that can convert any video into textual screenplay representations. Unlike previous storytelling methods, we organize video content into scenes as the basic unit, rather than just visually continuous shots. Additionally, we developed a ``Look Back'' strategy to reassess and validate uncertain information, particularly targeting breakpoint mode. MM-Screenplayer achieved highest score in the CVPR'2024 LOng-form VidEo Understanding (LOVEU) Track 1 Challenge, with a global accuracy of 87.5% and a breakpoint accuracy of 68.8%.