 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBFLA: Block-Filtered Long-Context Attention Mechanism
May 12, 2026This paper proposes Block-Filtered Long-Context Attention (BFLA), a training-free sparse prefill attention mechanism for long-context inference. BFLA adopts a two-stage design. In Stage 1, query and key sequences are compressed into coarse blocks, and lightweight block-level softmax mass estimation is performed to construct an input-dependent block importance mask. In Stage 2, the coarse mask is expanded to the Triton attention-tile grid. Several tile-level rescue strategies are applied to reduce information loss, where a fused sparse prefill kernel skips unimportant KV tiles while preserving exact token-level attention inside every retained tile. BFLA requires no retraining, calibration, preprocessing, or model modification and can be plugged into existing vLLM-style paged-attention workloads. Experiments on Gemma 4, Llama 3.1, Qwen 3.5, and Qwen 3.6 series models show that BFLA substantially accelerates long-context prefilling with minimal accuracy degradation compared to dense Triton FlashAttention. Project website: https://github.com/Alicewithrabbit/BFLA.
SoccerNet 2025 Challenges Results
Aug 26, 2025The SoccerNet 2025 Challenges mark the fifth annual edition of the SoccerNet open benchmarking effort, dedicated to advancing computer vision research in football video understanding. This year's challenges span four vision-based tasks: (1) Team Ball Action Spotting, focused on detecting ball-related actions in football broadcasts and assigning actions to teams; (2) Monocular Depth Estimation, targeting the recovery of scene geometry from single-camera broadcast clips through relative depth estimation for each pixel; (3) Multi-View Foul Recognition, requiring the analysis of multiple synchronized camera views to classify fouls and their severity; and (4) Game State Reconstruction, aimed at localizing and identifying all players from a broadcast video to reconstruct the game state on a 2D top-view of the field. Across all tasks, participants were provided with large-scale annotated datasets, unified evaluation protocols, and strong baselines as starting points. This report presents the results of each challenge, highlights the top-performing solutions, and provides insights into the progress made by the community. The SoccerNet Challenges continue to serve as a driving force for reproducible, open research at the intersection of computer vision, artificial intelligence, and sports. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
VEU-Bench: Towards Comprehensive Understanding of Video Editing
Apr 24, 2025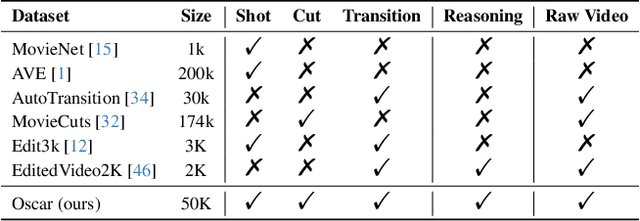
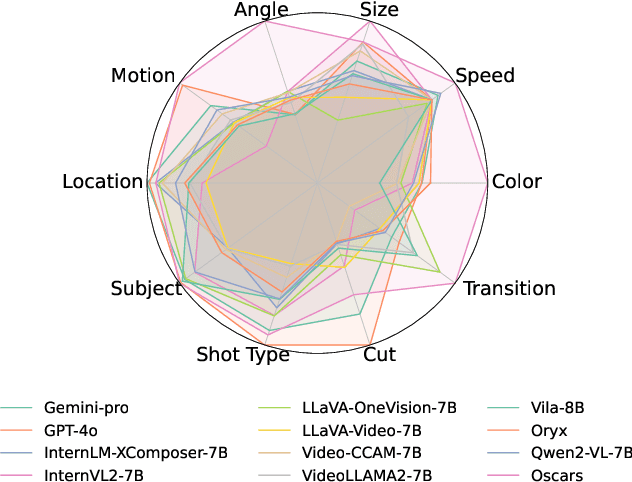
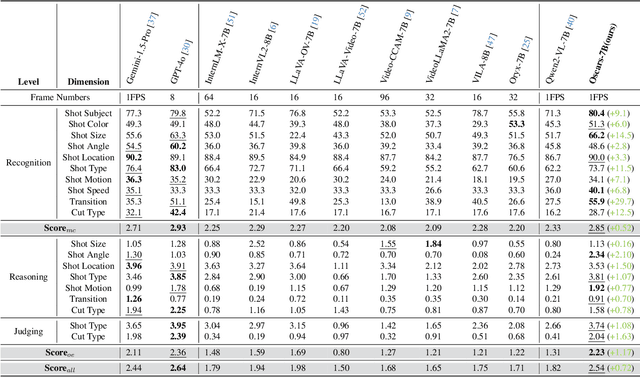
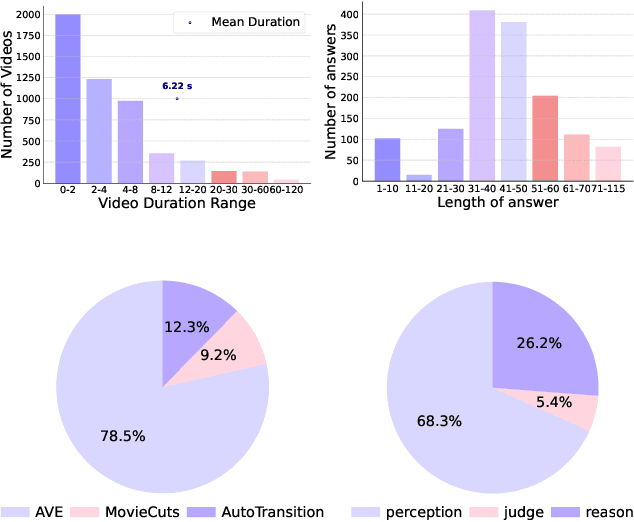
Widely shared videos on the internet are often edited. Recently, although Video Large Language Models (Vid-LLMs) have made great progress in general video understanding tasks, their capabilities in video editing understanding (VEU) tasks remain unexplored. To address this gap, in this paper, we introduce VEU-Bench (Video Editing Understanding Benchmark), a comprehensive benchmark that categorizes video editing components across various dimensions, from intra-frame features like shot size to inter-shot attributes such as cut types and transitions. Unlike previous video editing understanding benchmarks that focus mainly on editing element classification, VEU-Bench encompasses 19 fine-grained tasks across three stages: recognition, reasoning, and judging. To enhance the annotation of VEU automatically, we built an annotation pipeline integrated with an ontology-based knowledge base. Through extensive experiments with 11 state-of-the-art Vid-LLMs, our findings reveal that current Vid-LLMs face significant challenges in VEU tasks, with some performing worse than random choice. To alleviate this issue, we develop Oscars, a VEU expert model fine-tuned on the curated VEU-Bench dataset. It outperforms existing open-source Vid-LLMs on VEU-Bench by over 28.3% in accuracy and achieves performance comparable to commercial models like GPT-4o. We also demonstrate that incorporating VEU data significantly enhances the performance of Vid-LLMs on general video understanding benchmarks, with an average improvement of 8.3% across nine reasoning tasks.
Video Repurposing from User Generated Content: A Large-scale Dataset and Benchmark
Dec 12, 2024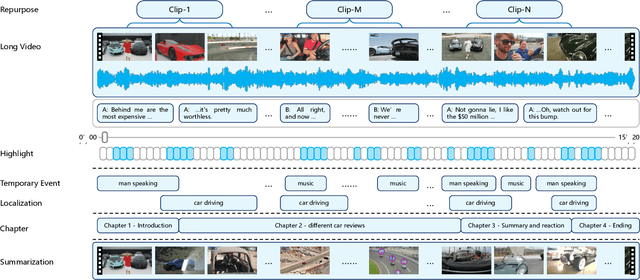
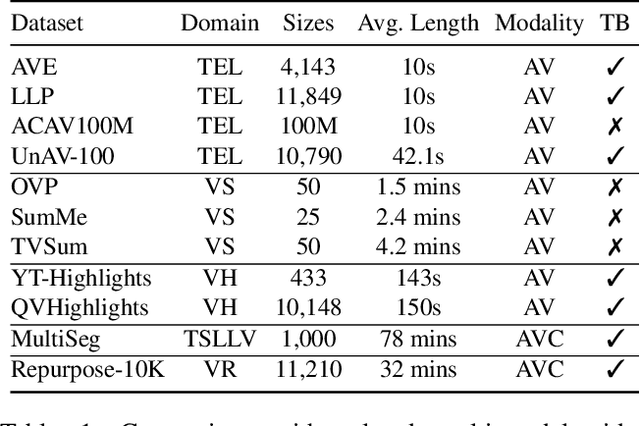
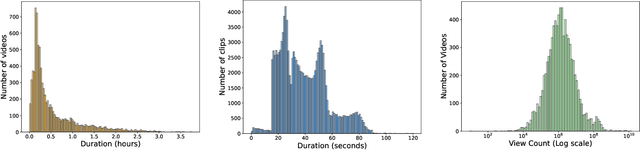
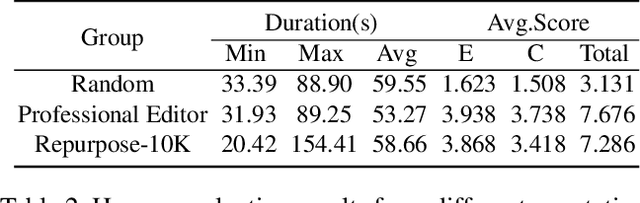
The demand for producing short-form videos for sharing on social media platforms has experienced significant growth in recent times. Despite notable advancements in the fields of video summarization and highlight detection, which can create partially usable short films from raw videos, these approaches are often domain-specific and require an in-depth understanding of real-world video content. To tackle this predicament, we propose Repurpose-10K, an extensive dataset comprising over 10,000 videos with more than 120,000 annotated clips aimed at resolving the video long-to-short task. Recognizing the inherent constraints posed by untrained human annotators, which can result in inaccurate annotations for repurposed videos, we propose a two-stage solution to obtain annotations from real-world user-generated content. Furthermore, we offer a baseline model to address this challenging task by integrating audio, visual, and caption aspects through a cross-modal fusion and alignment framework. We aspire for our work to ignite groundbreaking research in the lesser-explored realms of video repurposing. The code and data will be available at https://github.com/yongliang-wu/Repurpose.
Zero-Shot Long-Form Video Understanding through Screenplay
Jun 25, 2024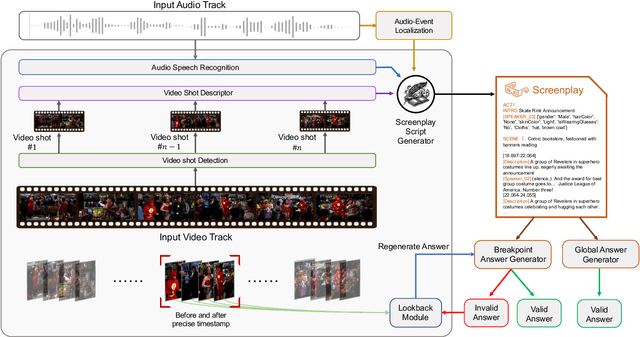
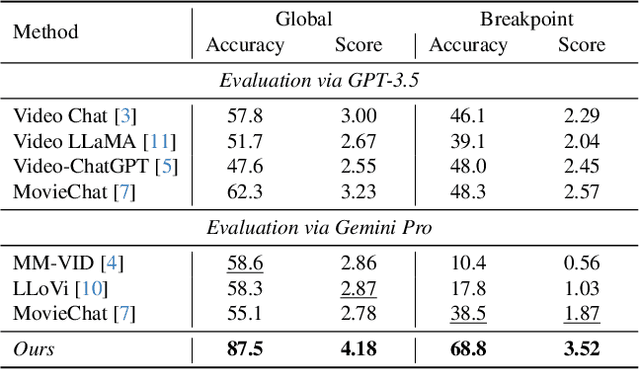
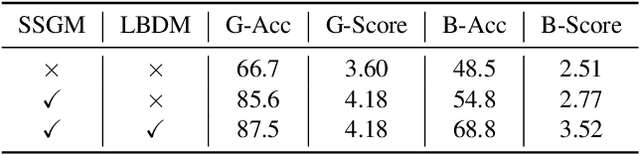

The Long-form Video Question-Answering task requires the comprehension and analysis of extended video content to respond accurately to questions by utilizing both temporal and contextual information. In this paper, we present MM-Screenplayer, an advanced video understanding system with multi-modal perception capabilities that can convert any video into textual screenplay representations. Unlike previous storytelling methods, we organize video content into scenes as the basic unit, rather than just visually continuous shots. Additionally, we developed a ``Look Back'' strategy to reassess and validate uncertain information, particularly targeting breakpoint mode. MM-Screenplayer achieved highest score in the CVPR'2024 LOng-form VidEo Understanding (LOVEU) Track 1 Challenge, with a global accuracy of 87.5% and a breakpoint accuracy of 68.8%.
Reframe Anything: LLM Agent for Open World Video Reframing
Mar 10, 2024



The proliferation of mobile devices and social media has revolutionized content dissemination, with short-form video becoming increasingly prevalent. This shift has introduced the challenge of video reframing to fit various screen aspect ratios, a process that highlights the most compelling parts of a video. Traditionally, video reframing is a manual, time-consuming task requiring professional expertise, which incurs high production costs. A potential solution is to adopt some machine learning models, such as video salient object detection, to automate the process. However, these methods often lack generalizability due to their reliance on specific training data. The advent of powerful large language models (LLMs) open new avenues for AI capabilities. Building on this, we introduce Reframe Any Video Agent (RAVA), a LLM-based agent that leverages visual foundation models and human instructions to restructure visual content for video reframing. RAVA operates in three stages: perception, where it interprets user instructions and video content; planning, where it determines aspect ratios and reframing strategies; and execution, where it invokes the editing tools to produce the final video. Our experiments validate the effectiveness of RAVA in video salient object detection and real-world reframing tasks, demonstrating its potential as a tool for AI-powered video editing.