 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Dense Evidence Refinement for Video Relational Reasoning for VRR-QA Challenge
May 31, 2026VRR-QA evaluates whether video-language systems can infer spatial, temporal, viewpoint, depth, and visibility relations that are not always resolved by a single frame. We present an inference-only system built around adaptive test-time computation. The system first answers each question with a direct video-language model pass, then uses multiple lightweight views to find unstable questions. Only these difficult questions are routed to a high-budget dense evidence module that constructs timestamped frame observations, relation-specific probes, candidate verification, and conservative temporal aggregation. This design separates two problems that are often confused in video question answering: finding plausible alternative answers and deciding when a current answer should actually be changed. On the test split, the final system obtains 90.07 average accuracy and 87.81 macro average accuracy. The report focuses on the final test system and the implementation settings required to reproduce the adaptive dense verifier.
Temporal Evidence Routing with Structured Visual Evidence for TimeLogicQA
May 31, 2026TimeLogicQA evaluates whether video question answering systems can reason over temporal relations such as event existence, ordering, persistence, boundary conditions, and overlap. We address this task with a visual evidence routing pipeline that separates perception from symbolic temporal reasoning. The system first parses each question into event targets, answer mode, candidate options, and temporal operators. It then routes videos according to duration and operator difficulty, using ordered full-frame evidence for short clips and event-focused candidate windows for long videos. A multimodal large language model produces structured visual evidence for the relevant events, while programmatic verifiers recover dense action intervals and a deterministic reducer applies operator-specific temporal rules to produce the final answer. Conservative fusion accepts an answer only when the visual evidence, temporal program, and confidence checks agree, reducing noisy answer flips. On the official test evaluation, our final system achieves an AvgAcc of 81.8.
Dual-Route Top-K Retrieval with 1v1 VLM Reranking for the CoVR-R
May 31, 2026We describe \emph{Dual-Route Top-K Retrieval with 1v1 VLM Reranking} for the CoVR-R challenge. The method treats composed video retrieval as two coupled problems: finding a sufficiently complete top-k candidate set, and then safely deciding whether any candidate should replace a strong current top-1. We first improve the reasoning/text seed with a VLM slot selector over existing candidates, without introducing DFN visual retrieval. We then add a visual route from contact-sheet embeddings using DFN-H/DFN-L. The routes are merged into a top-10 candidate set, after which a VLM final reranker performs conservative 1v1 comparisons between the current top-1 and each challenger. On the hidden test split, the final system reaches 95.28 R@1, 97.47 R@5, 98.48 R@10, and 99.66 R@50. The main lesson is that CoVR-R benefits more from recall-selection decoupling than from broad text reranking or direct multi-candidate VLM classification.
GEditBench v2: A Human-Aligned Benchmark for General Image Editing
Mar 30, 2026Recent advances in image editing have enabled models to handle complex instructions with impressive realism. However, existing evaluation frameworks lag behind: current benchmarks suffer from narrow task coverage, while standard metrics fail to adequately capture visual consistency, i.e., the preservation of identity, structure and semantic coherence between edited and original images. To address these limitations, we introduce GEditBench v2, a comprehensive benchmark with 1,200 real-world user queries spanning 23 tasks, including a dedicated open-set category for unconstrained, out-of-distribution editing instructions beyond predefined tasks. Furthermore, we propose PVC-Judge, an open-source pairwise assessment model for visual consistency, trained via two novel region-decoupled preference data synthesis pipelines. Besides, we construct VCReward-Bench using expert-annotated preference pairs to assess the alignment of PVC-Judge with human judgments on visual consistency evaluation. Experiments show that our PVC-Judge achieves state-of-the-art evaluation performance among open-source models and even surpasses GPT-5.1 on average. Finally, by benchmarking 16 frontier editing models, we show that GEditBench v2 enables more human-aligned evaluation, revealing critical limitations of current models, and providing a reliable foundation for advancing precise image editing.
CoT Vectors: Transferring and Probing the Reasoning Mechanisms of LLMs
Oct 01, 2025Chain-of-Thought (CoT) prompting has emerged as a powerful approach to enhancing the reasoning capabilities of Large Language Models (LLMs). However, existing implementations, such as in-context learning and fine-tuning, remain costly and inefficient. To improve CoT reasoning at a lower cost, and inspired by the task vector paradigm, we introduce CoT Vectors, compact representations that encode task-general, multi-step reasoning knowledge. Through experiments with Extracted CoT Vectors, we observe pronounced layer-wise instability, manifesting as a U-shaped performance curve that reflects a systematic three-stage reasoning process in LLMs. To address this limitation, we propose Learnable CoT Vectors, optimized under a teacher-student framework to provide more stable and robust guidance. Extensive evaluations across diverse benchmarks and models demonstrate that CoT Vectors not only outperform existing baselines but also achieve performance comparable to parameter-efficient fine-tuning methods, while requiring fewer trainable parameters. Moreover, by treating CoT Vectors as a probe, we uncover how their effectiveness varies due to latent space structure, information density, acquisition mechanisms, and pre-training differences, offering new insights into the functional organization of multi-step reasoning in LLMs. The source code will be released.
SoccerNet 2025 Challenges Results
Aug 26, 2025The SoccerNet 2025 Challenges mark the fifth annual edition of the SoccerNet open benchmarking effort, dedicated to advancing computer vision research in football video understanding. This year's challenges span four vision-based tasks: (1) Team Ball Action Spotting, focused on detecting ball-related actions in football broadcasts and assigning actions to teams; (2) Monocular Depth Estimation, targeting the recovery of scene geometry from single-camera broadcast clips through relative depth estimation for each pixel; (3) Multi-View Foul Recognition, requiring the analysis of multiple synchronized camera views to classify fouls and their severity; and (4) Game State Reconstruction, aimed at localizing and identifying all players from a broadcast video to reconstruct the game state on a 2D top-view of the field. Across all tasks, participants were provided with large-scale annotated datasets, unified evaluation protocols, and strong baselines as starting points. This report presents the results of each challenge, highlights the top-performing solutions, and provides insights into the progress made by the community. The SoccerNet Challenges continue to serve as a driving force for reproducible, open research at the intersection of computer vision, artificial intelligence, and sports. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
On the Generalization of SFT: A Reinforcement Learning Perspective with Reward Rectification
Aug 07, 2025We present a simple yet theoretically motivated improvement to Supervised Fine-Tuning (SFT) for the Large Language Model (LLM), addressing its limited generalization compared to reinforcement learning (RL). Through mathematical analysis, we reveal that standard SFT gradients implicitly encode a problematic reward structure that may severely restrict the generalization capabilities of model. To rectify this, we propose Dynamic Fine-Tuning (DFT), stabilizing gradient updates for each token by dynamically rescaling the objective function with the probability of this token. Remarkably, this single-line code change significantly outperforms standard SFT across multiple challenging benchmarks and base models, demonstrating greatly improved generalization. Additionally, our approach shows competitive results in offline RL settings, offering an effective yet simpler alternative. This work bridges theoretical insight and practical solutions, substantially advancing SFT performance. The code will be available at https://github.com/yongliang-wu/DFT.
KRIS-Bench: Benchmarking Next-Level Intelligent Image Editing Models
May 22, 2025Recent advances in multi-modal generative models have enabled significant progress in instruction-based image editing. However, while these models produce visually plausible outputs, their capacity for knowledge-based reasoning editing tasks remains under-explored. In this paper, we introduce KRIS-Bench (Knowledge-based Reasoning in Image-editing Systems Benchmark), a diagnostic benchmark designed to assess models through a cognitively informed lens. Drawing from educational theory, KRIS-Bench categorizes editing tasks across three foundational knowledge types: Factual, Conceptual, and Procedural. Based on this taxonomy, we design 22 representative tasks spanning 7 reasoning dimensions and release 1,267 high-quality annotated editing instances. To support fine-grained evaluation, we propose a comprehensive protocol that incorporates a novel Knowledge Plausibility metric, enhanced by knowledge hints and calibrated through human studies. Empirical results on 10 state-of-the-art models reveal significant gaps in reasoning performance, highlighting the need for knowledge-centric benchmarks to advance the development of intelligent image editing systems.
VEU-Bench: Towards Comprehensive Understanding of Video Editing
Apr 24, 2025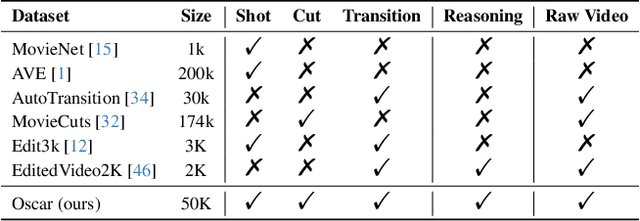
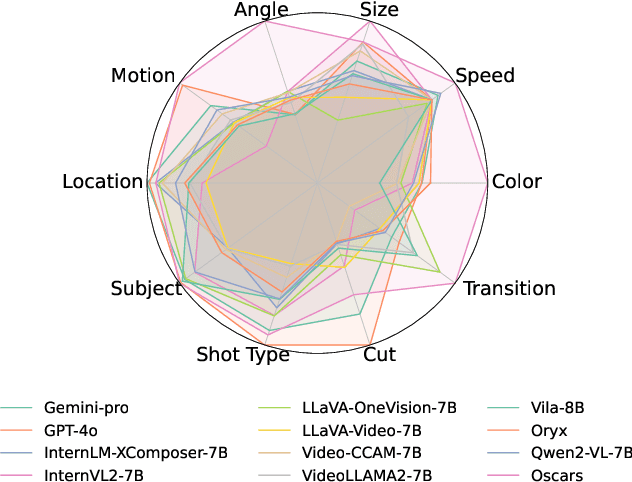
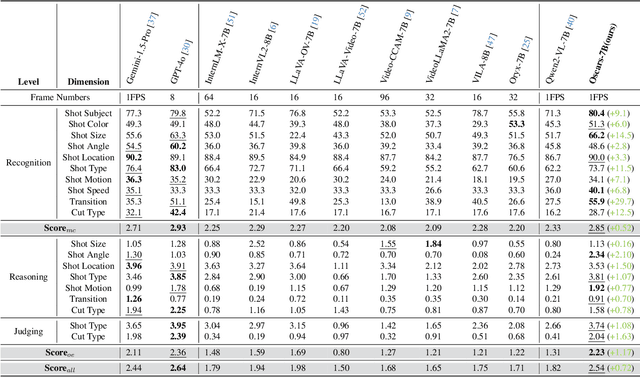
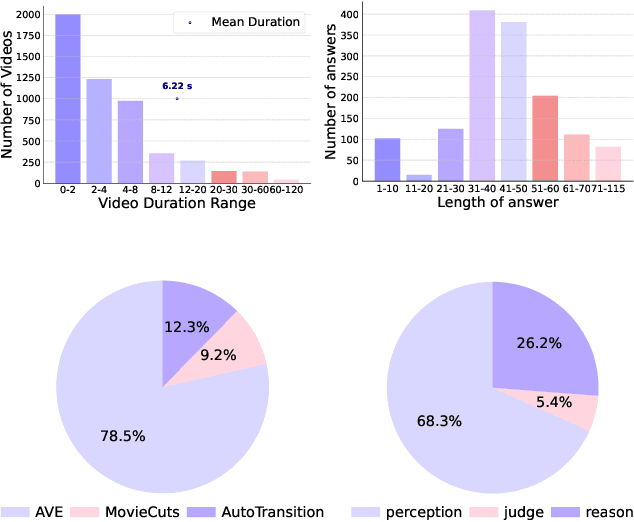
Widely shared videos on the internet are often edited. Recently, although Video Large Language Models (Vid-LLMs) have made great progress in general video understanding tasks, their capabilities in video editing understanding (VEU) tasks remain unexplored. To address this gap, in this paper, we introduce VEU-Bench (Video Editing Understanding Benchmark), a comprehensive benchmark that categorizes video editing components across various dimensions, from intra-frame features like shot size to inter-shot attributes such as cut types and transitions. Unlike previous video editing understanding benchmarks that focus mainly on editing element classification, VEU-Bench encompasses 19 fine-grained tasks across three stages: recognition, reasoning, and judging. To enhance the annotation of VEU automatically, we built an annotation pipeline integrated with an ontology-based knowledge base. Through extensive experiments with 11 state-of-the-art Vid-LLMs, our findings reveal that current Vid-LLMs face significant challenges in VEU tasks, with some performing worse than random choice. To alleviate this issue, we develop Oscars, a VEU expert model fine-tuned on the curated VEU-Bench dataset. It outperforms existing open-source Vid-LLMs on VEU-Bench by over 28.3% in accuracy and achieves performance comparable to commercial models like GPT-4o. We also demonstrate that incorporating VEU data significantly enhances the performance of Vid-LLMs on general video understanding benchmarks, with an average improvement of 8.3% across nine reasoning tasks.
Video Repurposing from User Generated Content: A Large-scale Dataset and Benchmark
Dec 12, 2024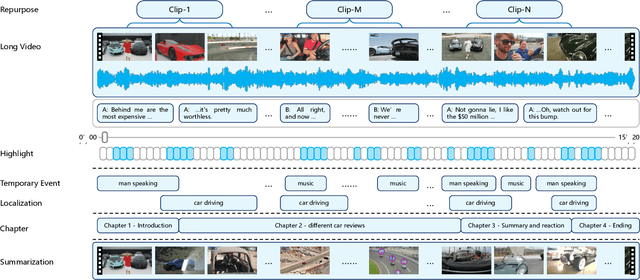
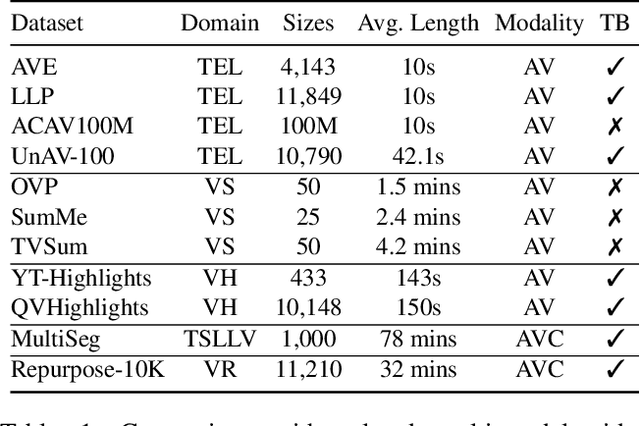
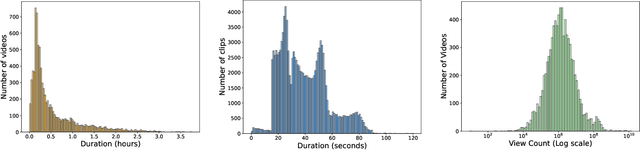
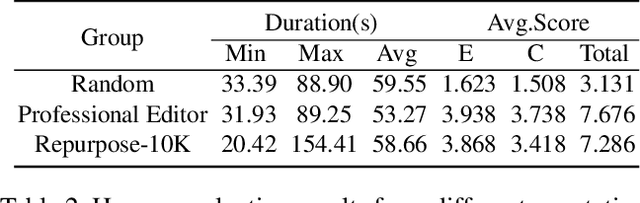
The demand for producing short-form videos for sharing on social media platforms has experienced significant growth in recent times. Despite notable advancements in the fields of video summarization and highlight detection, which can create partially usable short films from raw videos, these approaches are often domain-specific and require an in-depth understanding of real-world video content. To tackle this predicament, we propose Repurpose-10K, an extensive dataset comprising over 10,000 videos with more than 120,000 annotated clips aimed at resolving the video long-to-short task. Recognizing the inherent constraints posed by untrained human annotators, which can result in inaccurate annotations for repurposed videos, we propose a two-stage solution to obtain annotations from real-world user-generated content. Furthermore, we offer a baseline model to address this challenging task by integrating audio, visual, and caption aspects through a cross-modal fusion and alignment framework. We aspire for our work to ignite groundbreaking research in the lesser-explored realms of video repurposing. The code and data will be available at https://github.com/yongliang-wu/Repurpose.