 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAInsteinBench: Benchmarking Coding Agents on Scientific Repositories
Dec 24, 2025We introduce AInsteinBench, a large-scale benchmark for evaluating whether large language model (LLM) agents can operate as scientific computing development agents within real research software ecosystems. Unlike existing scientific reasoning benchmarks which focus on conceptual knowledge, or software engineering benchmarks that emphasize generic feature implementation and issue resolving, AInsteinBench evaluates models in end-to-end scientific development settings grounded in production-grade scientific repositories. The benchmark consists of tasks derived from maintainer-authored pull requests across six widely used scientific codebases, spanning quantum chemistry, quantum computing, molecular dynamics, numerical relativity, fluid dynamics, and cheminformatics. All benchmark tasks are carefully curated through multi-stage filtering and expert review to ensure scientific challenge, adequate test coverage, and well-calibrated difficulty. By leveraging evaluation in executable environments, scientifically meaningful failure modes, and test-driven verification, AInsteinBench measures a model's ability to move beyond surface-level code generation toward the core competencies required for computational scientific research.
OmniVLM: A Token-Compressed, Sub-Billion-Parameter Vision-Language Model for Efficient On-Device Inference
Dec 16, 2024We present OmniVLM, a sub-billion-parameter vision-language model for efficient on-device inference. OmniVLM introduces a token compression mechanism that reduces visual token sequence length from 729 to 81 tokens, significantly reducing computational overhead while preserving visual-semantic fidelity. Through a multi-stage training pipeline of pretraining, supervised fine-tuning, and minimal-edit Direct Preference Optimization (DPO), OmniVLM matches the performance of larger models. On multiple benchmarks including ScienceQA, POPE, and MMMU, OmniVLM outperforms existing baselines like nanoLLAVA within a 968M-parameter footprint. Empirical results on the same laptop demonstrate 9.1x faster time-to-first-token (0.75s vs 6.82s) and 1.5x higher decoding speed (29.41 vs 19.20 tokens/s) compared to nanoLLAVA, enabling efficient deployment on edge devices. The model weights can be accessed on huggingface: \url{https://huggingface.co/NexaAIDev/OmniVLM-968M}, and the inference examples can be find in Appendix B.
Visual Object Tracking across Diverse Data Modalities: A Review
Dec 13, 2024



Visual Object Tracking (VOT) is an attractive and significant research area in computer vision, which aims to recognize and track specific targets in video sequences where the target objects are arbitrary and class-agnostic. The VOT technology could be applied in various scenarios, processing data of diverse modalities such as RGB, thermal infrared and point cloud. Besides, since no one sensor could handle all the dynamic and varying environments, multi-modal VOT is also investigated. This paper presents a comprehensive survey of the recent progress of both single-modal and multi-modal VOT, especially the deep learning methods. Specifically, we first review three types of mainstream single-modal VOT, including RGB, thermal infrared and point cloud tracking. In particular, we conclude four widely-used single-modal frameworks, abstracting their schemas and categorizing the existing inheritors. Then we summarize four kinds of multi-modal VOT, including RGB-Depth, RGB-Thermal, RGB-LiDAR and RGB-Language. Moreover, the comparison results in plenty of VOT benchmarks of the discussed modalities are presented. Finally, we provide recommendations and insightful observations, inspiring the future development of this fast-growing literature.
Squid: Long Context as a New Modality for Energy-Efficient On-Device Language Models
Sep 03, 2024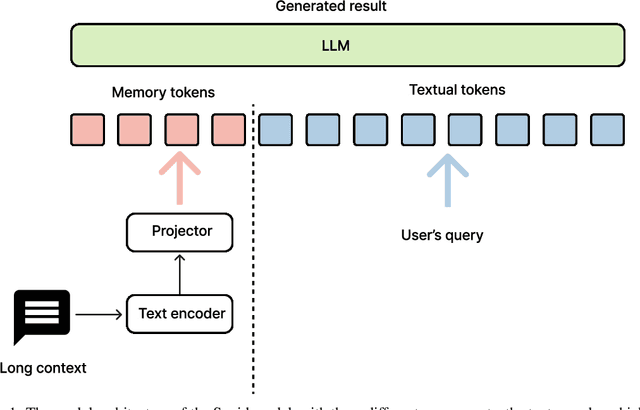
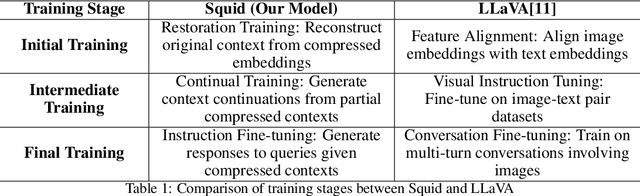

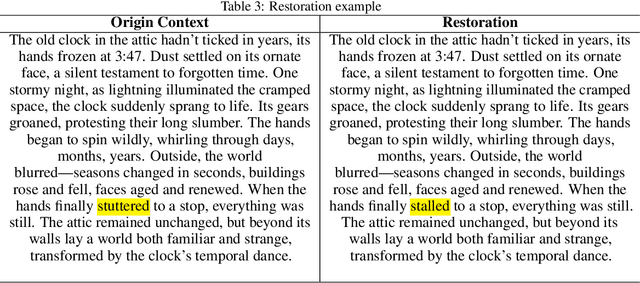
This paper presents Dolphin, a novel decoder-decoder architecture for energy-efficient processing of long contexts in language models. Our approach addresses the significant energy consumption and latency challenges inherent in on-device models. Dolphin employs a compact 0.5B parameter decoder to distill extensive contextual information into a memory embedding, substantially reducing the input length for the primary 7B parameter decoder model. Inspired by vision-language models, we repurpose the image embedding projector to encode long textual contexts, effectively treating extended context as a distinct modality. This innovative method enables processing of substantially longer contexts without the typical computational overhead associated with extended input sequences. Empirical evaluations demonstrate a 10-fold improvement in energy efficiency and a 5-fold reduction in latency compared to conventional full-length context processing methods without losing quality of the response. Our work contributes to the development of more sustainable and scalable language models for on-device applications, addressing the critical need for energy-efficient and responsive AI technologies in resource-constrained environments while maintaining the accuracy to understand long contexts. This research has implications for the broader field of natural language processing, particularly in the domain of efficient model design for resource-limited settings. By enabling more sophisticated AI capabilities on edge devices, Dolphin paves the way for advanced language processing in a wide range of applications where computational resources are at a premium. The Dolphin model is publicly available at https://huggingface.co/NexaAIDev/Dolphin.
SDSTrack: Self-Distillation Symmetric Adapter Learning for Multi-Modal Visual Object Tracking
Mar 28, 2024


Multimodal Visual Object Tracking (VOT) has recently gained significant attention due to its robustness. Early research focused on fully fine-tuning RGB-based trackers, which was inefficient and lacked generalized representation due to the scarcity of multimodal data. Therefore, recent studies have utilized prompt tuning to transfer pre-trained RGB-based trackers to multimodal data. However, the modality gap limits pre-trained knowledge recall, and the dominance of the RGB modality persists, preventing the full utilization of information from other modalities. To address these issues, we propose a novel symmetric multimodal tracking framework called SDSTrack. We introduce lightweight adaptation for efficient fine-tuning, which directly transfers the feature extraction ability from RGB to other domains with a small number of trainable parameters and integrates multimodal features in a balanced, symmetric manner. Furthermore, we design a complementary masked patch distillation strategy to enhance the robustness of trackers in complex environments, such as extreme weather, poor imaging, and sensor failure. Extensive experiments demonstrate that SDSTrack outperforms state-of-the-art methods in various multimodal tracking scenarios, including RGB+Depth, RGB+Thermal, and RGB+Event tracking, and exhibits impressive results in extreme conditions. Our source code is available at https://github.com/hoqolo/SDSTrack.