 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeapVAD: A Leap in Autonomous Driving via Cognitive Perception and Dual-Process Thinking
Jan 14, 2025While autonomous driving technology has made remarkable strides, data-driven approaches still struggle with complex scenarios due to their limited reasoning capabilities. Meanwhile, knowledge-driven autonomous driving systems have evolved considerably with the popularization of visual language models. In this paper, we propose LeapVAD, a novel method based on cognitive perception and dual-process thinking. Our approach implements a human-attentional mechanism to identify and focus on critical traffic elements that influence driving decisions. By characterizing these objects through comprehensive attributes - including appearance, motion patterns, and associated risks - LeapVAD achieves more effective environmental representation and streamlines the decision-making process. Furthermore, LeapVAD incorporates an innovative dual-process decision-making module miming the human-driving learning process. The system consists of an Analytic Process (System-II) that accumulates driving experience through logical reasoning and a Heuristic Process (System-I) that refines this knowledge via fine-tuning and few-shot learning. LeapVAD also includes reflective mechanisms and a growing memory bank, enabling it to learn from past mistakes and continuously improve its performance in a closed-loop environment. To enhance efficiency, we develop a scene encoder network that generates compact scene representations for rapid retrieval of relevant driving experiences. Extensive evaluations conducted on two leading autonomous driving simulators, CARLA and DriveArena, demonstrate that LeapVAD achieves superior performance compared to camera-only approaches despite limited training data. Comprehensive ablation studies further emphasize its effectiveness in continuous learning and domain adaptation. Project page: https://pjlab-adg.github.io/LeapVAD/.
DreamForge: Motion-Aware Autoregressive Video Generation for Multi-View Driving Scenes
Sep 06, 2024



Recent advances in diffusion models have significantly enhanced the cotrollable generation of streetscapes for and facilitated downstream perception and planning tasks. However, challenges such as maintaining temporal coherence, generating long videos, and accurately modeling driving scenes persist. Accordingly, we propose DreamForge, an advanced diffusion-based autoregressive video generation model designed for the long-term generation of 3D-controllable and extensible video. In terms of controllability, our DreamForge supports flexible conditions such as text descriptions, camera poses, 3D bounding boxes, and road layouts, while also providing perspective guidance to produce driving scenes that are both geometrically and contextually accurate. For consistency, we ensure inter-view consistency through cross-view attention and temporal coherence via an autoregressive architecture enhanced with motion cues. Codes will be available at https://github.com/PJLab-ADG/DriveArena.
DriveArena: A Closed-loop Generative Simulation Platform for Autonomous Driving
Aug 01, 2024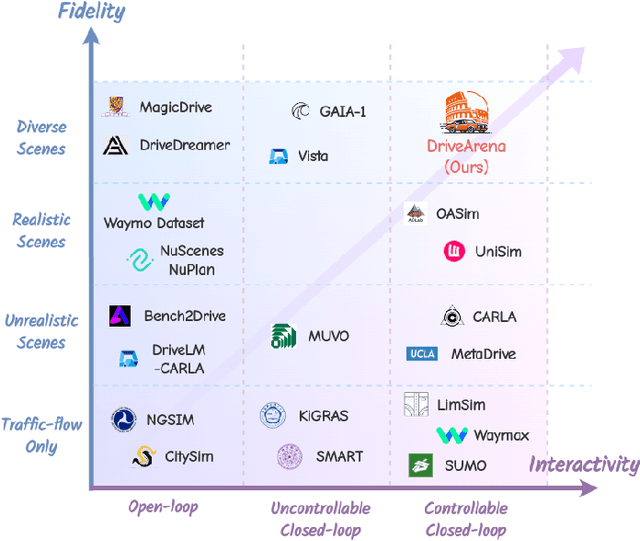

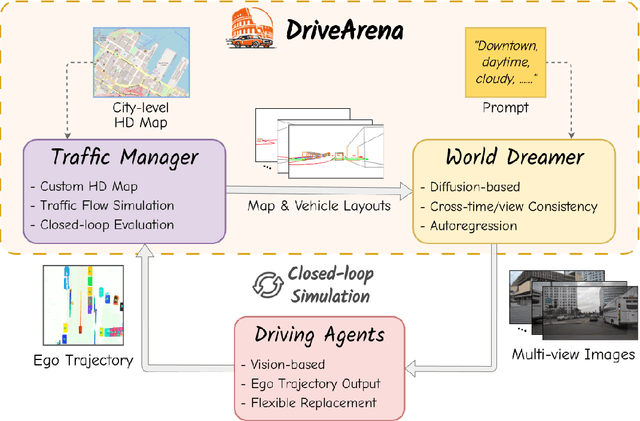

This paper presented DriveArena, the first high-fidelity closed-loop simulation system designed for driving agents navigating in real scenarios. DriveArena features a flexible, modular architecture, allowing for the seamless interchange of its core components: Traffic Manager, a traffic simulator capable of generating realistic traffic flow on any worldwide street map, and World Dreamer, a high-fidelity conditional generative model with infinite autoregression. This powerful synergy empowers any driving agent capable of processing real-world images to navigate in DriveArena's simulated environment. The agent perceives its surroundings through images generated by World Dreamer and output trajectories. These trajectories are fed into Traffic Manager, achieving realistic interactions with other vehicles and producing a new scene layout. Finally, the latest scene layout is relayed back into World Dreamer, perpetuating the simulation cycle. This iterative process fosters closed-loop exploration within a highly realistic environment, providing a valuable platform for developing and evaluating driving agents across diverse and challenging scenarios. DriveArena signifies a substantial leap forward in leveraging generative image data for the driving simulation platform, opening insights for closed-loop autonomous driving. Code will be available soon on GitHub: https://github.com/PJLab-ADG/DriveArena