 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Representation Learning with Laplacian Pyramid Auto-encoders
May 12, 2018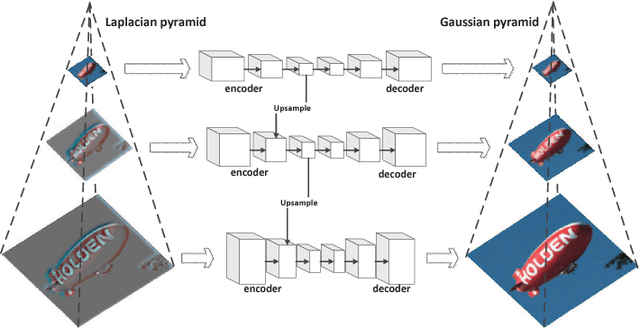
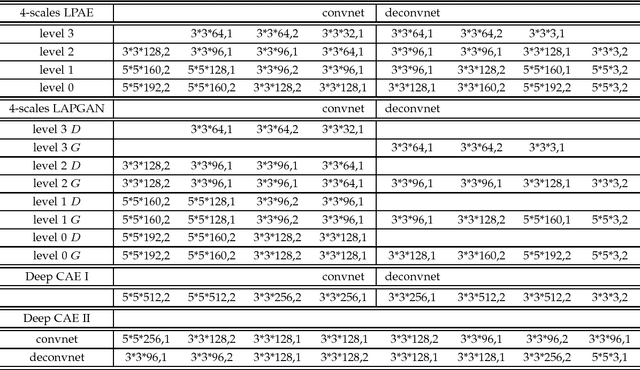
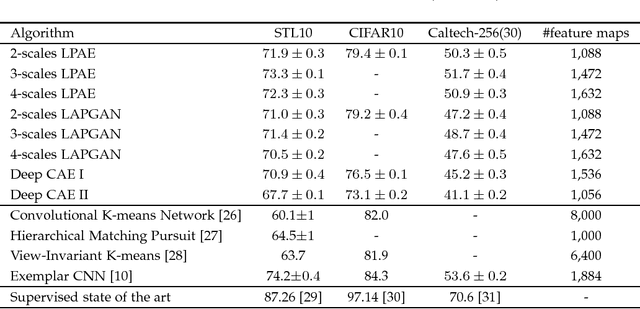

Scale-space representation has been popular in computer vision community due to its theoretical foundation. The motivation for generating a scale-space representation of a given data set originates from the basic observation that real-world objects are composed of different structures at different scales. Hence, it's reasonable to consider learning features with image pyramids generated by smoothing and down-sampling operations. In this paper we propose Laplacian pyramid auto-encoders, a straightforward modification of the deep convolutional auto-encoder architecture, for unsupervised representation learning. The method uses multiple encoding-decoding sub-networks within a Laplacian pyramid framework to reconstruct the original image and the low pass filtered images. The last layer of each encoding sub-network also connects to an encoding layer of the sub-network in the next level, which aims to reverse the process of Laplacian pyramid generation. Experimental results showed that Laplacian pyramid benefited the classification and reconstruction performance of deep auto-encoder approaches, and batch normalization is critical to get deep auto-encoders approaches to begin learning.