 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeETCHR: Editing To Clarify and Harness Reasoning
May 22, 2026Multimodal Large Language Models have advanced visual reasoning, yet a purely textual chain of thought remains a bottleneck for questions that require fine-grained focus or view transformations. The ''think with images'' paradigm narrows this gap, but existing approaches are either constrained by fixed predefined toolkits or produce noisy intermediate images from unified multimodal methods. We pursue a third option: using a dedicated image editing model and decouple it with an understanding model. However, off-the-shelf image editors fail as reasoning assistants with two complementary gaps: a language-side gap, where editors trained as passive instruction-followers cannot map an abstract question to an appropriate visual transformation, and a generation-side gap, where edit correctness degrades as reasoning depth grows. Guided by this analysis, we introduce ETCHR (Editing To Clarify and Harness Reasoning), a question-conditioned, reasoning-aware image editor decoupled from the downstream understanding model and trained with a two-stage recipe targeted at the two gaps: Reasoning Imitation via supervised fine-tuning on edit trajectories, followed by Reasoning Enhancement with VLM-derived rewards for edit correctness and downstream reasoning accuracy. Since the editor is decoupled, ETCHR plugs into different open- and closed-source MLLMs in a training-free manner. Across five task families (fine-grained perception, chart understanding, logic reasoning, jigsaw restoration, and 3D understanding), ETCHR raises average Pass@1 from 55.95 to 60.77 (+4.82) with Qwen3-VL-8B, from 65.08 to 70.55 (+5.47) with Gemini-3.1-Flash-Lite, and from 76.55 to 81.16 (+4.61) with the 1T-parameter MoE model Kimi K2.5.
Memento-Skills: Let Agents Design Agents
Mar 19, 2026We introduce \emph{Memento-Skills}, a generalist, continually-learnable LLM agent system that functions as an \emph{agent-designing agent}: it autonomously constructs, adapts, and improves task-specific agents through experience. The system is built on a memory-based reinforcement learning framework with \emph{stateful prompts}, where reusable skills (stored as structured markdown files) serve as persistent, evolving memory. These skills encode both behaviour and context, enabling the agent to carry forward knowledge across interactions. Starting from simple elementary skills (like Web search and terminal operations), the agent continually improves via the \emph{Read--Write Reflective Learning} mechanism introduced in \emph{Memento~2}~\cite{wang2025memento2}. In the \emph{read} phase, a behaviour-trainable skill router selects the most relevant skill conditioned on the current stateful prompt; in the \emph{write} phase, the agent updates and expands its skill library based on new experience. This closed-loop design enables \emph{continual learning without updating LLM parameters}, as all adaptation is realised through the evolution of externalised skills and prompts. Unlike prior approaches that rely on human-designed agents, Memento-Skills enables a generalist agent to \emph{design agents end-to-end} for new tasks. Through iterative skill generation and refinement, the system progressively improves its own capabilities. Experiments on the \emph{General AI Assistants} benchmark and \emph{Humanity's Last Exam} demonstrate sustained gains, achieving 26.2\% and 116.2\% relative improvements in overall accuracy, respectively. Code is available at https://github.com/Memento-Teams/Memento-Skills.
Visual Self-Refine: A Pixel-Guided Paradigm for Accurate Chart Parsing
Feb 18, 2026While Large Vision-Language Models (LVLMs) have demonstrated remarkable capabilities for reasoning and self-correction at the textual level, these strengths provide minimal benefits for complex tasks centered on visual perception, such as Chart Parsing. Existing models often struggle with visually dense charts, leading to errors like data omission, misalignment, and hallucination. Inspired by the human strategy of using a finger as a ``visual anchor'' to ensure accuracy when reading complex charts, we propose a new paradigm named Visual Self-Refine (VSR). The core idea of VSR is to enable a model to generate pixel-level localization outputs, visualize them, and then feed these visualizations back to itself, allowing it to intuitively inspect and correct its own potential visual perception errors. We instantiate the VSR paradigm in the domain of Chart Parsing by proposing ChartVSR. This model decomposes the parsing process into two stages: a Refine Stage, where it iteratively uses visual feedback to ensure the accuracy of all data points' Pixel-level Localizations, and a Decode Stage, where it uses these verified localizations as precise visual anchors to parse the final structured data. To address the limitations of existing benchmarks, we also construct ChartP-Bench, a new and highly challenging benchmark for chart parsing. Our work also highlights VSR as a general-purpose visual feedback mechanism, offering a promising new direction for enhancing accuracy on a wide range of vision-centric tasks.
Beyond Fixed: Variable-Length Denoising for Diffusion Large Language Models
Aug 01, 2025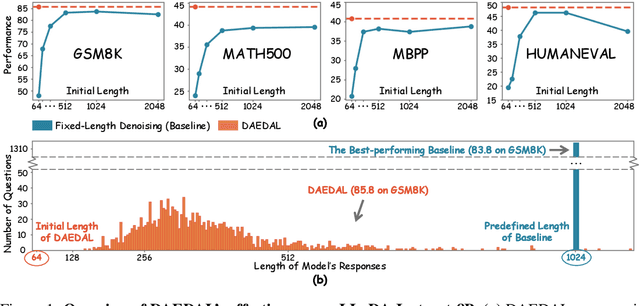
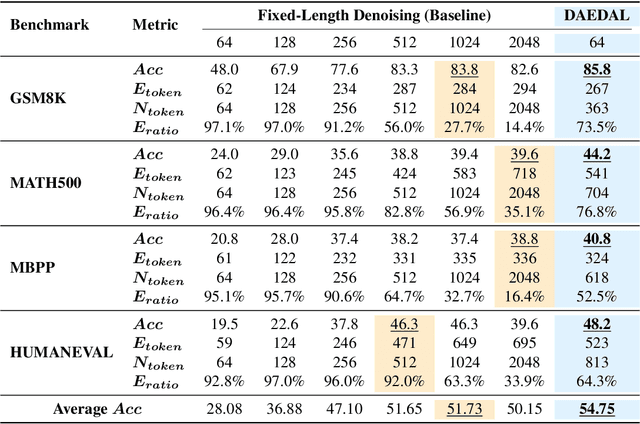

Diffusion Large Language Models (DLLMs) are emerging as a powerful alternative to the dominant Autoregressive Large Language Models, offering efficient parallel generation and capable global context modeling. However, the practical application of DLLMs is hindered by a critical architectural constraint: the need for a statically predefined generation length. This static length allocation leads to a problematic trade-off: insufficient lengths cripple performance on complex tasks, while excessive lengths incur significant computational overhead and sometimes result in performance degradation. While the inference framework is rigid, we observe that the model itself possesses internal signals that correlate with the optimal response length for a given task. To bridge this gap, we leverage these latent signals and introduce DAEDAL, a novel training-free denoising strategy that enables Dynamic Adaptive Length Expansion for Diffusion Large Language Models. DAEDAL operates in two phases: 1) Before the denoising process, DAEDAL starts from a short initial length and iteratively expands it to a coarse task-appropriate length, guided by a sequence completion metric. 2) During the denoising process, DAEDAL dynamically intervenes by pinpointing and expanding insufficient generation regions through mask token insertion, ensuring the final output is fully developed. Extensive experiments on DLLMs demonstrate that DAEDAL achieves performance comparable, and in some cases superior, to meticulously tuned fixed-length baselines, while simultaneously enhancing computational efficiency by achieving a higher effective token ratio. By resolving the static length constraint, DAEDAL unlocks new potential for DLLMs, bridging a critical gap with their Autoregressive counterparts and paving the way for more efficient and capable generation.
ScaleCap: Inference-Time Scalable Image Captioning via Dual-Modality Debiasing
Jun 24, 2025
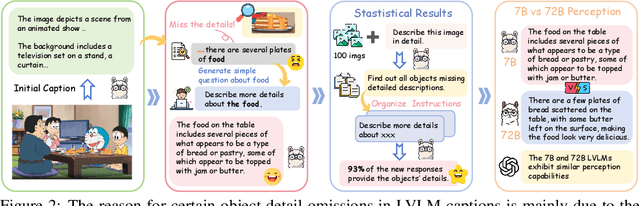


This paper presents ScaleCap, an inference-time scalable image captioning strategy that generates comprehensive and detailed image captions. The key challenges of high-quality image captioning lie in the inherent biases of LVLMs: multimodal bias resulting in imbalanced descriptive granularity, offering detailed accounts of some elements while merely skimming over others; linguistic bias leading to hallucinated descriptions of non-existent objects. To address these issues, we propose a scalable debiased captioning strategy, which continuously enriches and calibrates the caption with increased inference budget. Specifically, we propose two novel components: heuristic question answering and contrastive sentence rating. The former generates content-specific questions based on the image and answers them to progressively inject relevant information into the caption. The latter employs sentence-level offline contrastive decoding to effectively identify and eliminate hallucinations caused by linguistic biases. With increased inference cost, more heuristic questions are raised by ScaleCap to progressively capture additional visual details, generating captions that are more accurate, balanced, and informative. Extensive modality alignment experiments demonstrate the effectiveness of ScaleCap. Annotating 450K images with ScaleCap and using them for LVLM pretraining leads to consistent performance gains across 11 widely used benchmarks. Furthermore, ScaleCap showcases superb richness and fidelity of generated captions with two additional tasks: replacing images with captions in VQA task, and reconstructing images from captions to assess semantic coverage. Code is available at https://github.com/Cooperx521/ScaleCap.
Towards Storage-Efficient Visual Document Retrieval: An Empirical Study on Reducing Patch-Level Embeddings
Jun 05, 2025Despite the strong performance of ColPali/ColQwen2 in Visualized Document Retrieval (VDR), it encodes each page into multiple patch-level embeddings and leads to excessive memory usage. This empirical study investigates methods to reduce patch embeddings per page at minimum performance degradation. We evaluate two token-reduction strategies: token pruning and token merging. Regarding token pruning, we surprisingly observe that a simple random strategy outperforms other sophisticated pruning methods, though still far from satisfactory. Further analysis reveals that pruning is inherently unsuitable for VDR as it requires removing certain page embeddings without query-specific information. Turning to token merging (more suitable for VDR), we search for the optimal combinations of merging strategy across three dimensions and develop Light-ColPali/ColQwen2. It maintains 98.2% of retrieval performance with only 11.8% of original memory usage, and preserves 94.6% effectiveness at 2.8% memory footprint. We expect our empirical findings and resulting Light-ColPali/ColQwen2 offer valuable insights and establish a competitive baseline for future research towards efficient VDR.
Light-A-Video: Training-free Video Relighting via Progressive Light Fusion
Feb 12, 2025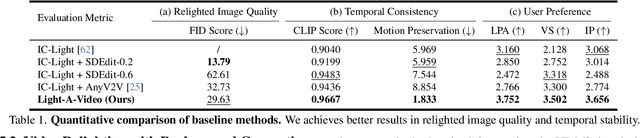
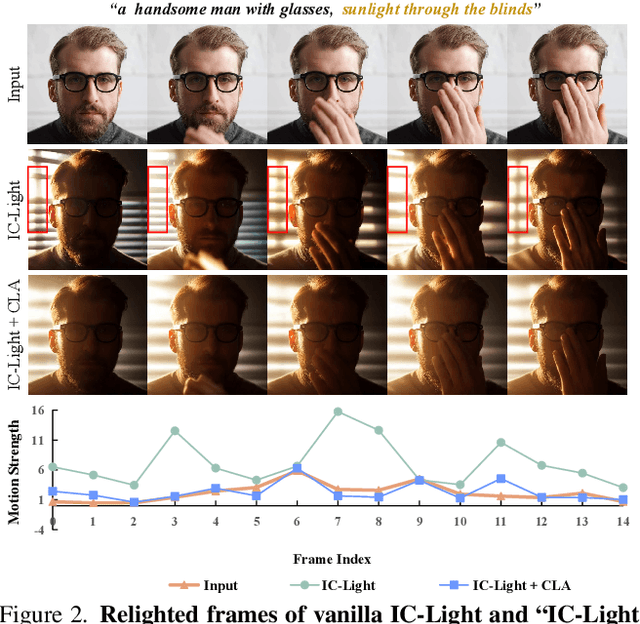
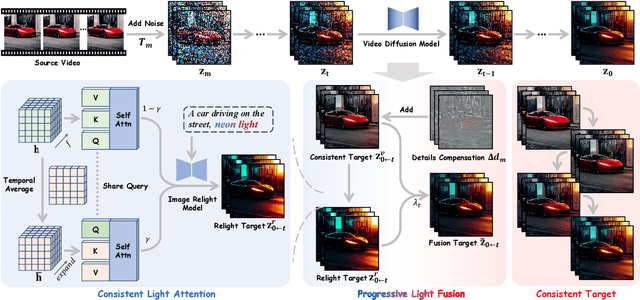
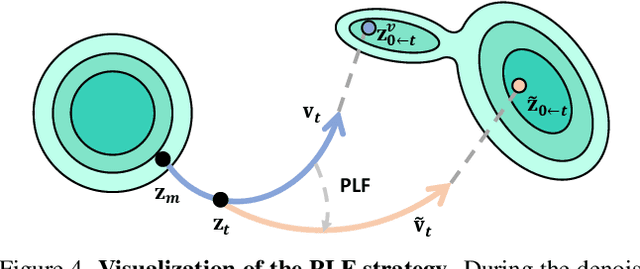
Recent advancements in image relighting models, driven by large-scale datasets and pre-trained diffusion models, have enabled the imposition of consistent lighting. However, video relighting still lags, primarily due to the excessive training costs and the scarcity of diverse, high-quality video relighting datasets. A simple application of image relighting models on a frame-by-frame basis leads to several issues: lighting source inconsistency and relighted appearance inconsistency, resulting in flickers in the generated videos. In this work, we propose Light-A-Video, a training-free approach to achieve temporally smooth video relighting. Adapted from image relighting models, Light-A-Video introduces two key techniques to enhance lighting consistency. First, we design a Consistent Light Attention (CLA) module, which enhances cross-frame interactions within the self-attention layers to stabilize the generation of the background lighting source. Second, leveraging the physical principle of light transport independence, we apply linear blending between the source video's appearance and the relighted appearance, using a Progressive Light Fusion (PLF) strategy to ensure smooth temporal transitions in illumination. Experiments show that Light-A-Video improves the temporal consistency of relighted video while maintaining the image quality, ensuring coherent lighting transitions across frames. Project page: https://bujiazi.github.io/light-a-video.github.io/.
ShareGPT4Video: Improving Video Understanding and Generation with Better Captions
Jun 06, 2024



We present the ShareGPT4Video series, aiming to facilitate the video understanding of large video-language models (LVLMs) and the video generation of text-to-video models (T2VMs) via dense and precise captions. The series comprises: 1) ShareGPT4Video, 40K GPT4V annotated dense captions of videos with various lengths and sources, developed through carefully designed data filtering and annotating strategy. 2) ShareCaptioner-Video, an efficient and capable captioning model for arbitrary videos, with 4.8M high-quality aesthetic videos annotated by it. 3) ShareGPT4Video-8B, a simple yet superb LVLM that reached SOTA performance on three advancing video benchmarks. To achieve this, taking aside the non-scalable costly human annotators, we find using GPT4V to caption video with a naive multi-frame or frame-concatenation input strategy leads to less detailed and sometimes temporal-confused results. We argue the challenge of designing a high-quality video captioning strategy lies in three aspects: 1) Inter-frame precise temporal change understanding. 2) Intra-frame detailed content description. 3) Frame-number scalability for arbitrary-length videos. To this end, we meticulously designed a differential video captioning strategy, which is stable, scalable, and efficient for generating captions for videos with arbitrary resolution, aspect ratios, and length. Based on it, we construct ShareGPT4Video, which contains 40K high-quality videos spanning a wide range of categories, and the resulting captions encompass rich world knowledge, object attributes, camera movements, and crucially, detailed and precise temporal descriptions of events. Based on ShareGPT4Video, we further develop ShareCaptioner-Video, a superior captioner capable of efficiently generating high-quality captions for arbitrary videos...
Are We on the Right Way for Evaluating Large Vision-Language Models?
Apr 09, 2024



Large vision-language models (LVLMs) have recently achieved rapid progress, sparking numerous studies to evaluate their multi-modal capabilities. However, we dig into current evaluation works and identify two primary issues: 1) Visual content is unnecessary for many samples. The answers can be directly inferred from the questions and options, or the world knowledge embedded in LLMs. This phenomenon is prevalent across current benchmarks. For instance, GeminiPro achieves 42.9% on the MMMU benchmark without any visual input, and outperforms the random choice baseline across six benchmarks over 24% on average. 2) Unintentional data leakage exists in LLM and LVLM training. LLM and LVLM could still answer some visual-necessary questions without visual content, indicating the memorizing of these samples within large-scale training data. For example, Sphinx-X-MoE gets 43.6% on MMMU without accessing images, surpassing its LLM backbone with 17.9%. Both problems lead to misjudgments of actual multi-modal gains and potentially misguide the study of LVLM. To this end, we present MMStar, an elite vision-indispensable multi-modal benchmark comprising 1,500 samples meticulously selected by humans. MMStar benchmarks 6 core capabilities and 18 detailed axes, aiming to evaluate LVLMs' multi-modal capacities with carefully balanced and purified samples. These samples are first roughly selected from current benchmarks with an automated pipeline, human review is then involved to ensure each curated sample exhibits visual dependency, minimal data leakage, and requires advanced multi-modal capabilities. Moreover, two metrics are developed to measure data leakage and actual performance gain in multi-modal training. We evaluate 16 leading LVLMs on MMStar to assess their multi-modal capabilities, and on 7 benchmarks with the proposed metrics to investigate their data leakage and actual multi-modal gain.
SA$^2$VP: Spatially Aligned-and-Adapted Visual Prompt
Dec 16, 2023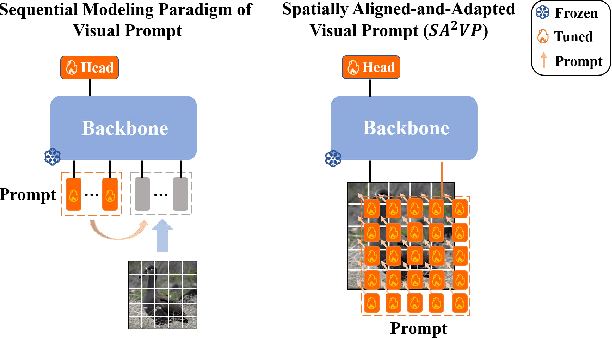
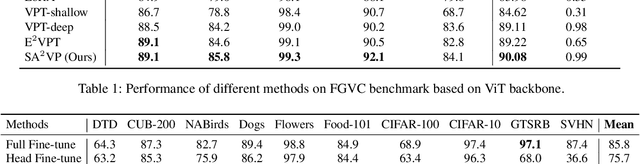
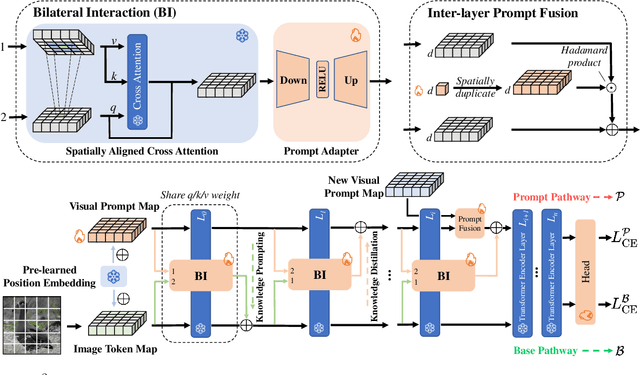

As a prominent parameter-efficient fine-tuning technique in NLP, prompt tuning is being explored its potential in computer vision. Typical methods for visual prompt tuning follow the sequential modeling paradigm stemming from NLP, which represents an input image as a flattened sequence of token embeddings and then learns a set of unordered parameterized tokens prefixed to the sequence representation as the visual prompts for task adaptation of large vision models. While such sequential modeling paradigm of visual prompt has shown great promise, there are two potential limitations. First, the learned visual prompts cannot model the underlying spatial relations in the input image, which is crucial for image encoding. Second, since all prompt tokens play the same role of prompting for all image tokens without distinction, it lacks the fine-grained prompting capability, i.e., individual prompting for different image tokens. In this work, we propose the \mymodel model (\emph{SA$^2$VP}), which learns a two-dimensional prompt token map with equal (or scaled) size to the image token map, thereby being able to spatially align with the image map. Each prompt token is designated to prompt knowledge only for the spatially corresponding image tokens. As a result, our model can conduct individual prompting for different image tokens in a fine-grained manner. Moreover, benefiting from the capability of preserving the spatial structure by the learned prompt token map, our \emph{SA$^2$VP} is able to model the spatial relations in the input image, leading to more effective prompting. Extensive experiments on three challenging benchmarks for image classification demonstrate the superiority of our model over other state-of-the-art methods for visual prompt tuning. Code is available at \emph{https://github.com/tommy-xq/SA2VP}.