 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Neural Path Planning
Jul 20, 2023Learning-based path planning is becoming a promising robot navigation methodology due to its adaptability to various environments. However, the expensive computing and storage associated with networks impose significant challenges for their deployment on low-cost robots. Motivated by this practical challenge, we develop a lightweight neural path planning architecture with a dual input network and a hybrid sampler for resource-constrained robotic systems. Our architecture is designed with efficient task feature extraction and fusion modules to translate the given planning instance into a guidance map. The hybrid sampler is then applied to restrict the planning within the prospective regions indicated by the guide map. To enable the network training, we further construct a publicly available dataset with various successful planning instances. Numerical simulations and physical experiments demonstrate that, compared with baseline approaches, our approach has nearly an order of magnitude fewer model size and five times lower computational while achieving promising performance. Besides, our approach can also accelerate the planning convergence process with fewer planning iterations compared to sample-based methods.
A Nested U-Structure for Instrument Segmentation in Robotic Surgery
Jul 17, 2023



Robot-assisted surgery has made great progress with the development of medical imaging and robotics technology. Medical scene understanding can greatly improve surgical performance while the semantic segmentation of the robotic instrument is a key enabling technology for robot-assisted surgery. However, how to locate an instrument's position and estimate their pose in complex surgical environments is still a challenging fundamental problem. In this paper, pixel-wise instrument segmentation is investigated. The contributions of the paper are twofold: 1) We proposed a two-level nested U-structure model, which is an encoder-decoder architecture with skip-connections and each layer of the network structure adopts a U-structure instead of a simple superposition of convolutional layers. The model can capture more context information from multiple scales and better fuse the local and global information to achieve high-quality segmentation. 2) Experiments have been conducted to qualitatively and quantitatively show the performance of our approach on three segmentation tasks: the binary segmentation, the parts segmentation, and the type segmentation, respectively.
TODE-Trans: Transparent Object Depth Estimation with Transformer
Sep 18, 2022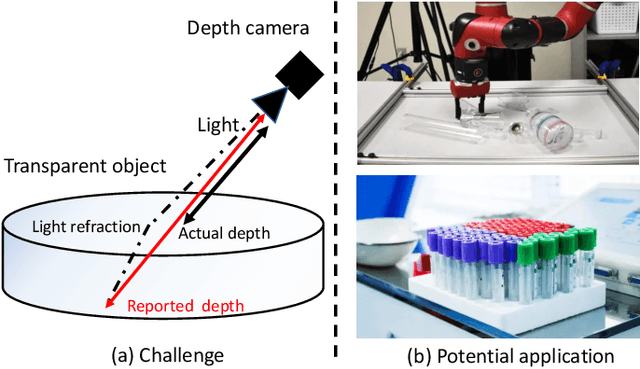
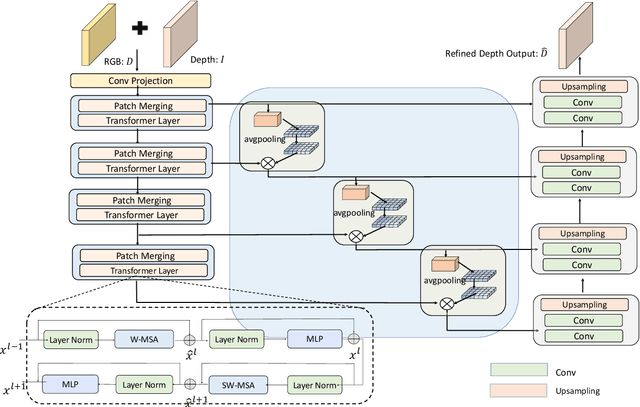


Transparent objects are widely used in industrial automation and daily life. However, robust visual recognition and perception of transparent objects have always been a major challenge. Currently, most commercial-grade depth cameras are still not good at sensing the surfaces of transparent objects due to the refraction and reflection of light. In this work, we present a transformer-based transparent object depth estimation approach from a single RGB-D input. We observe that the global characteristics of the transformer make it easier to extract contextual information to perform depth estimation of transparent areas. In addition, to better enhance the fine-grained features, a feature fusion module (FFM) is designed to assist coherent prediction. Our empirical evidence demonstrates that our model delivers significant improvements in recent popular datasets, e.g., 25% gain on RMSE and 21% gain on REL compared to previous state-of-the-art convolutional-based counterparts in ClearGrasp dataset. Extensive results show that our transformer-based model enables better aggregation of the object's RGB and inaccurate depth information to obtain a better depth representation. Our code and the pre-trained model will be available at https://github.com/yuchendoudou/TODE.
A Robotic Visual Grasping Design: Rethinking Convolution Neural Network with High-Resolutions
Sep 16, 2022
High-resolution representations are important for vision-based robotic grasping problems. Existing works generally encode the input images into low-resolution representations via sub-networks and then recover high-resolution representations. This will lose spatial information, and errors introduced by the decoder will be more serious when multiple types of objects are considered or objects are far away from the camera. To address these issues, we revisit the design paradigm of CNN for robotic perception tasks. We demonstrate that using parallel branches as opposed to serial stacked convolutional layers will be a more powerful design for robotic visual grasping tasks. In particular, guidelines of neural network design are provided for robotic perception tasks, e.g., high-resolution representation and lightweight design, which respond to the challenges in different manipulation scenarios. We then develop a novel grasping visual architecture referred to as HRG-Net, a parallel-branch structure that always maintains a high-resolution representation and repeatedly exchanges information across resolutions. Extensive experiments validate that these two designs can effectively enhance the accuracy of visual-based grasping and accelerate network training. We show a series of comparative experiments in real physical environments at Youtube: https://youtu.be/Jhlsp-xzHFY.
What You See is What You Grasp: User-Friendly Grasping Guided by Near-eye-tracking
Sep 13, 2022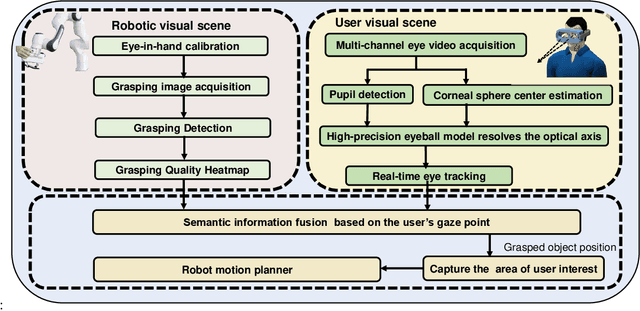

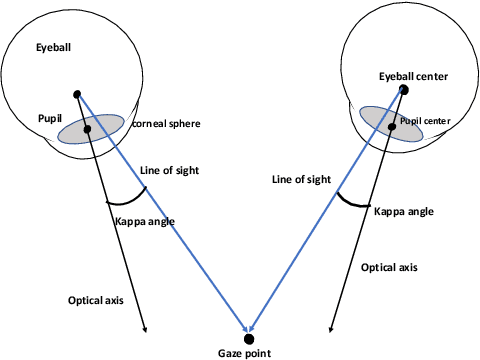
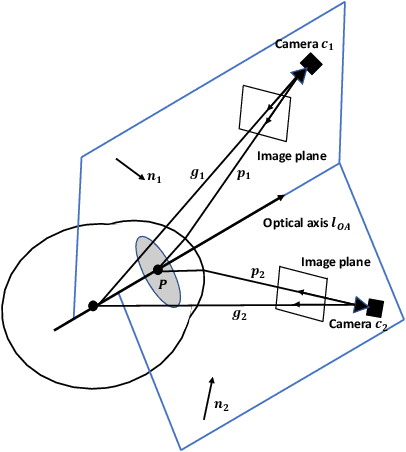
This work presents a next-generation human-robot interface that can infer and realize the user's manipulation intention via sight only. Specifically, we develop a system that integrates near-eye-tracking and robotic manipulation to enable user-specified actions (e.g., grasp, pick-and-place, etc), where visual information is merged with human attention to create a mapping for desired robot actions. To enable sight guided manipulation, a head-mounted near-eye-tracking device is developed to track the eyeball movements in real-time, so that the user's visual attention can be identified. To improve the grasping performance, a transformer based grasp model is then developed. Stacked transformer blocks are used to extract hierarchical features where the volumes of channels are expanded at each stage while squeezing the resolution of feature maps. Experimental validation demonstrates that the eye-tracking system yields low gaze estimation error and the grasping system yields promising results on multiple grasping datasets. This work is a proof of concept for gaze interaction-based assistive robot, which holds great promise to help the elder or upper limb disabilities in their daily lives. A demo video is available at \url{https://www.youtube.com/watch?v=yuZ1hukYUrM}.
When Transformer Meets Robotic Grasping: Exploits Context for Efficient Grasp Detection
Feb 24, 2022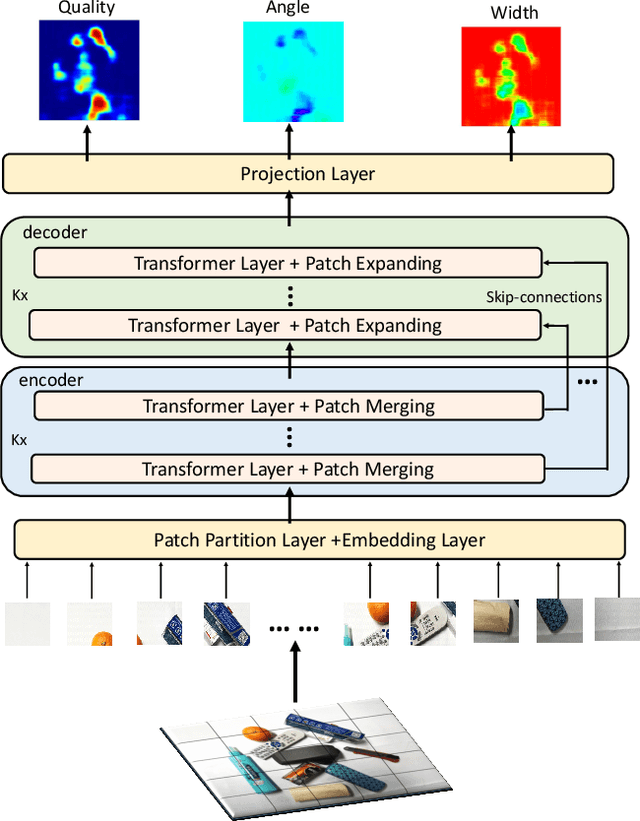
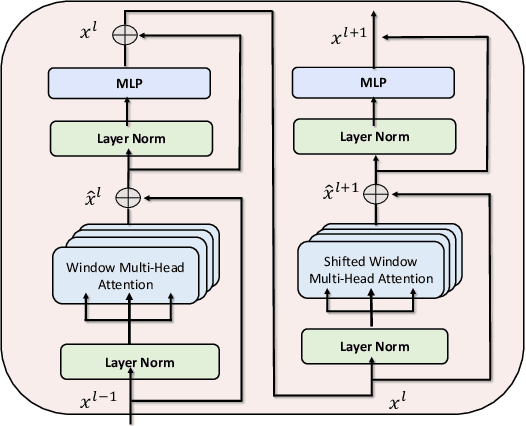


In this paper, we present a transformer-based architecture, namely TF-Grasp, for robotic grasp detection. The developed TF-Grasp framework has two elaborate designs making it well suitable for visual grasping tasks. The first key design is that we adopt the local window attention to capture local contextual information and detailed features of graspable objects. Then, we apply the cross window attention to model the long-term dependencies between distant pixels. Object knowledge, environmental configuration, and relationships between different visual entities are aggregated for subsequent grasp detection. The second key design is that we build a hierarchical encoder-decoder architecture with skip-connections, delivering shallow features from encoder to decoder to enable a multi-scale feature fusion. Due to the powerful attention mechanism, the TF-Grasp can simultaneously obtain the local information (i.e., the contours of objects), and model long-term connections such as the relationships between distinct visual concepts in clutter. Extensive computational experiments demonstrate that the TF-Grasp achieves superior results versus state-of-art grasping convolutional models and attain a higher accuracy of 97.99% and 94.6% on Cornell and Jacquard grasping datasets, respectively. Real-world experiments using a 7DoF Franka Emika Panda robot also demonstrate its capability of grasping unseen objects in a variety of scenarios. The code and pre-trained models will be available at https://github.com/WangShaoSUN/grasp-transformer
Context-Based Soft Actor Critic for Environments with Non-stationary Dynamics
May 10, 2021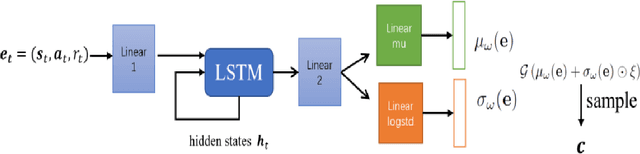
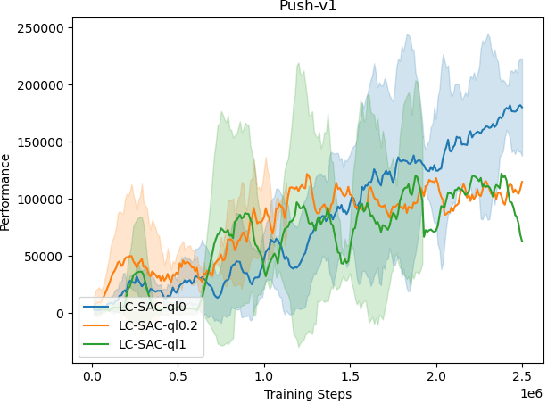
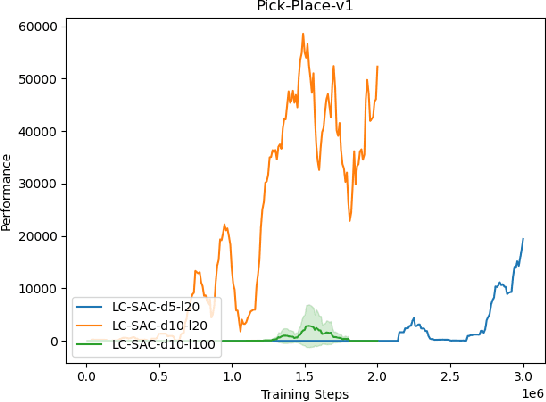
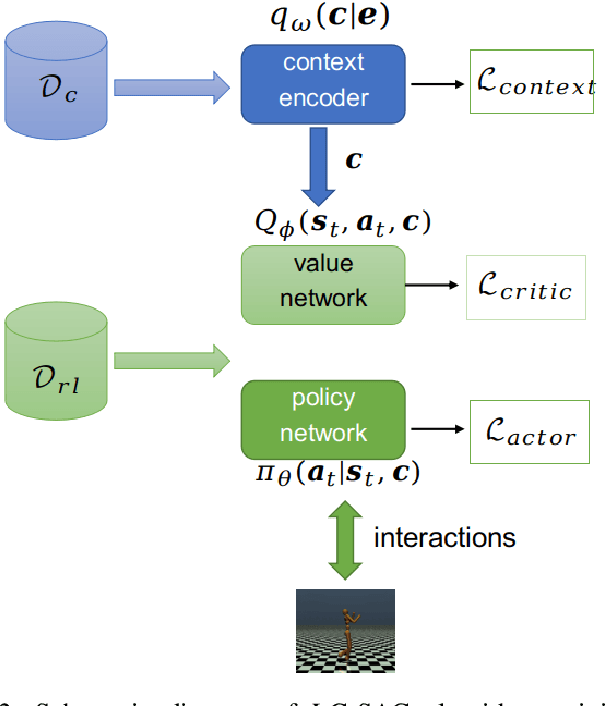
The performance of deep reinforcement learning methods prone to degenerate when applied to environments with non-stationary dynamics. In this paper, we utilize the latent context recurrent encoders motivated by recent Meta-RL materials, and propose the Latent Context-based Soft Actor Critic (LC-SAC) method to address aforementioned issues. By minimizing the contrastive prediction loss function, the learned context variables capture the information of the environment dynamics and the recent behavior of the agent. Then combined with the soft policy iteration paradigm, the LC-SAC method alternates between soft policy evaluation and soft policy improvement until it converges to the optimal policy. Experimental results show that the performance of LC-SAC is significantly better than the SAC algorithm on the MetaWorld ML1 tasks whose dynamics changes drasticly among different episodes, and is comparable to SAC on the continuous control benchmark task MuJoCo whose dynamics changes slowly or doesn't change between different episodes. In addition, we also conduct relevant experiments to determine the impact of different hyperparameter settings on the performance of the LC-SAC algorithm and give the reasonable suggestions of hyperparameter setting.
Decomposed Soft Actor-Critic Method for Cooperative Multi-Agent Reinforcement Learning
May 08, 2021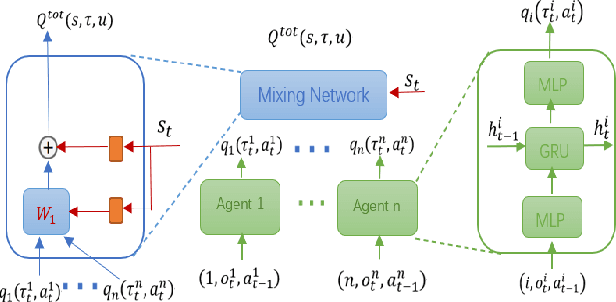
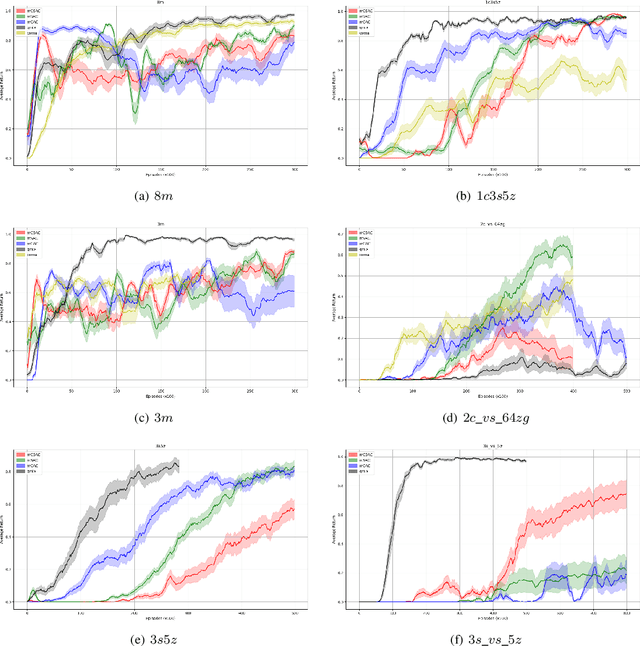
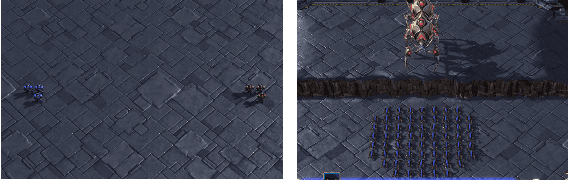
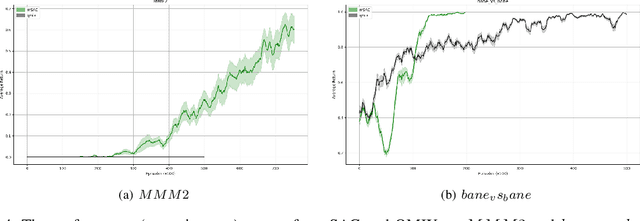
Deep reinforcement learning methods have shown great performance on many challenging cooperative multi-agent tasks. Two main promising research directions are multi-agent value function decomposition and multi-agent policy gradients. In this paper, we propose a new decomposed multi-agent soft actor-critic (mSAC) method, which effectively combines the advantages of the aforementioned two methods. The main modules include decomposed Q network architecture, discrete probabilistic policy and counterfactual advantage function (optinal). Theoretically, mSAC supports efficient off-policy learning and addresses credit assignment problem partially in both discrete and continuous action spaces. Tested on StarCraft II micromanagement cooperative multiagent benchmark, we empirically investigate the performance of mSAC against its variants and analyze the effects of the different components. Experimental results demonstrate that mSAC significantly outperforms policy-based approach COMA, and achieves competitive results with SOTA value-based approach Qmix on most tasks in terms of asymptotic perfomance metric. In addition, mSAC achieves pretty good results on large action space tasks, such as 2c_vs_64zg and MMM2.
Statistical inference in massive datasets by empirical likelihood
Apr 18, 2020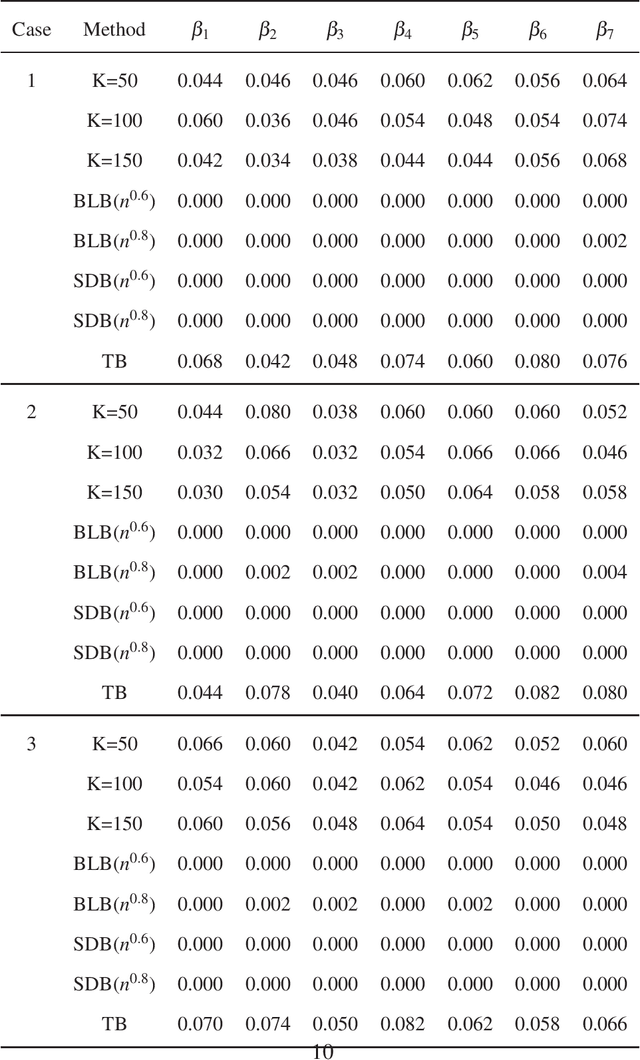
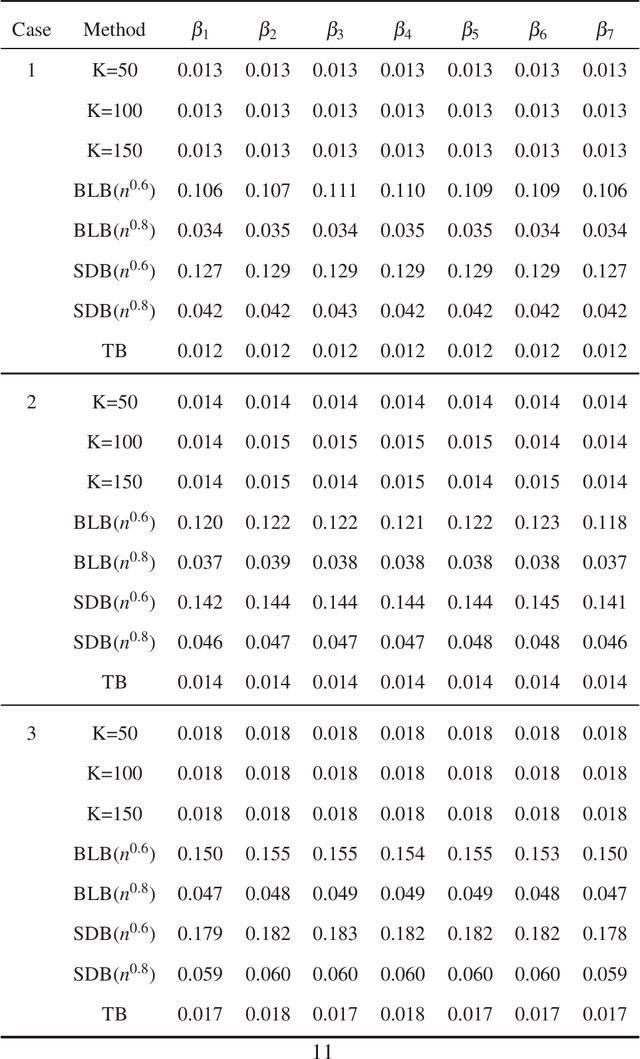
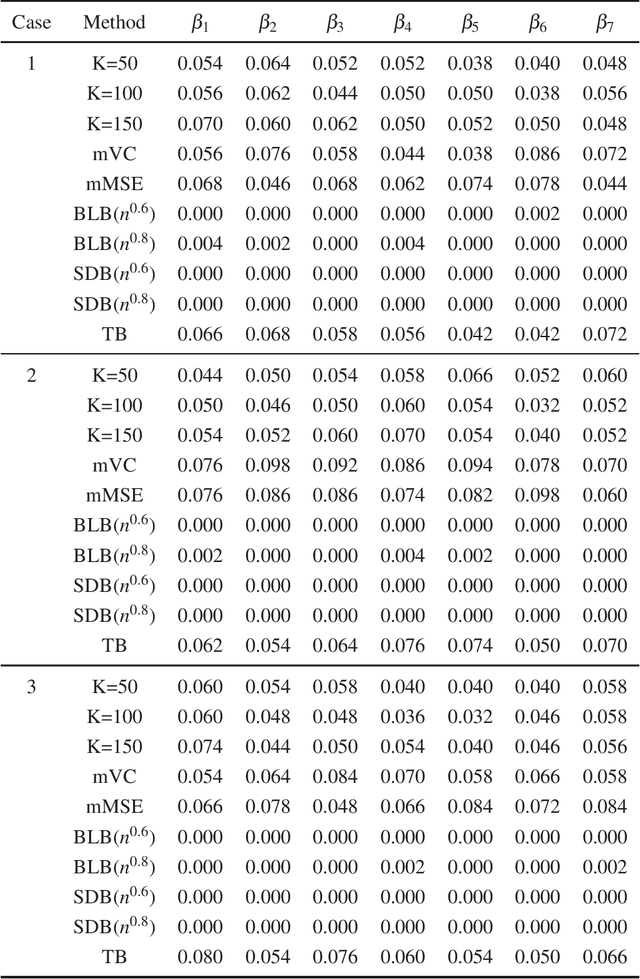
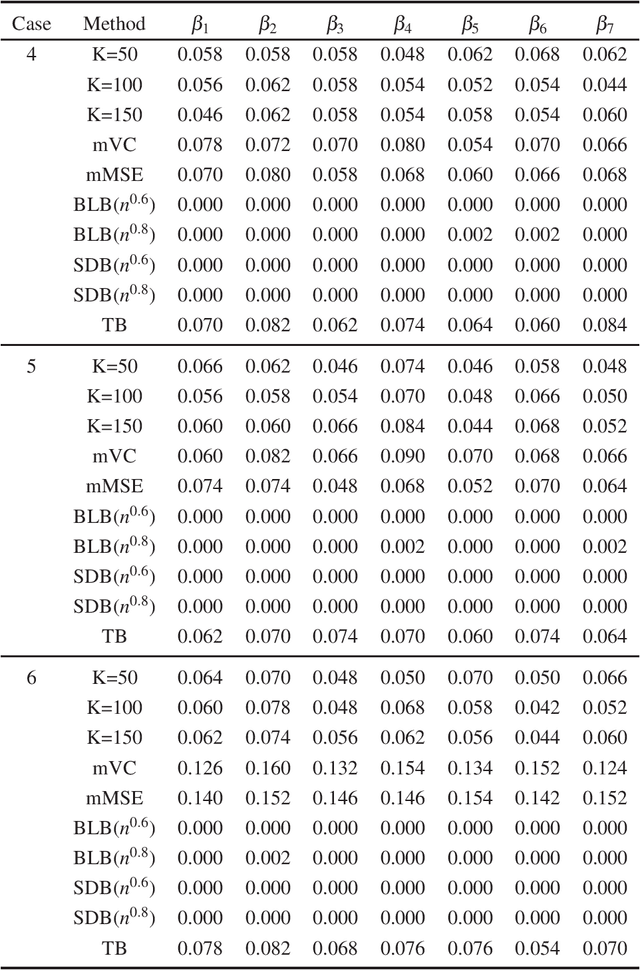
In this paper, we propose a new statistical inference method for massive data sets, which is very simple and efficient by combining divide-and-conquer method and empirical likelihood. Compared with two popular methods (the bag of little bootstrap and the subsampled double bootstrap), we make full use of data sets, and reduce the computation burden. Extensive numerical studies and real data analysis demonstrate the effectiveness and flexibility of our proposed method. Furthermore, the asymptotic property of our method is derived.