 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Based Reactive Planning and Control of Quadruped Robots in Unstructured Dynamic Environments
Jul 17, 2023
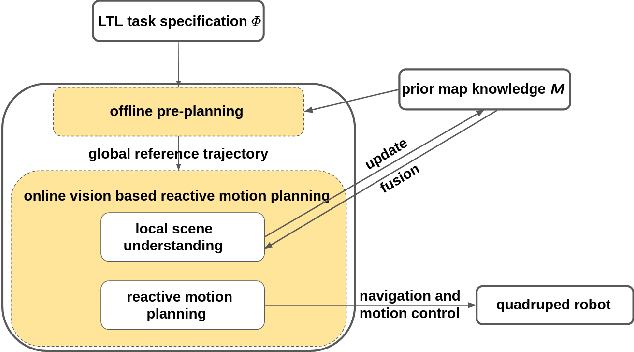

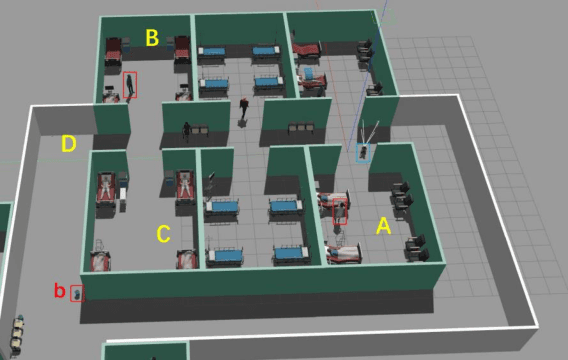
Quadruped robots have received increasing attention for the past few years. However, existing works primarily focus on static environments or assume the robot has full observations of the environment. This limits their practical applications since real-world environments are often dynamic and partially observable. To tackle these issues, vision-based reactive planning and control (V-RPC) is developed in this work. The V-RPC comprises two modules: offline pre-planning and online reactive planning. The pre-planning phase generates a reference trajectory over continuous workspace via sampling-based methods using prior environmental knowledge, given an LTL specification. The online reactive module dynamically adjusts the reference trajectory and control based on the robot's real-time visual perception to adapt to environmental changes.
A Robotic Visual Grasping Design: Rethinking Convolution Neural Network with High-Resolutions
Sep 16, 2022
High-resolution representations are important for vision-based robotic grasping problems. Existing works generally encode the input images into low-resolution representations via sub-networks and then recover high-resolution representations. This will lose spatial information, and errors introduced by the decoder will be more serious when multiple types of objects are considered or objects are far away from the camera. To address these issues, we revisit the design paradigm of CNN for robotic perception tasks. We demonstrate that using parallel branches as opposed to serial stacked convolutional layers will be a more powerful design for robotic visual grasping tasks. In particular, guidelines of neural network design are provided for robotic perception tasks, e.g., high-resolution representation and lightweight design, which respond to the challenges in different manipulation scenarios. We then develop a novel grasping visual architecture referred to as HRG-Net, a parallel-branch structure that always maintains a high-resolution representation and repeatedly exchanges information across resolutions. Extensive experiments validate that these two designs can effectively enhance the accuracy of visual-based grasping and accelerate network training. We show a series of comparative experiments in real physical environments at Youtube: https://youtu.be/Jhlsp-xzHFY.
What You See is What You Grasp: User-Friendly Grasping Guided by Near-eye-tracking
Sep 13, 2022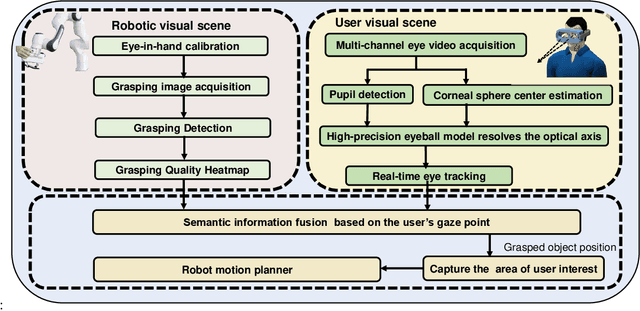

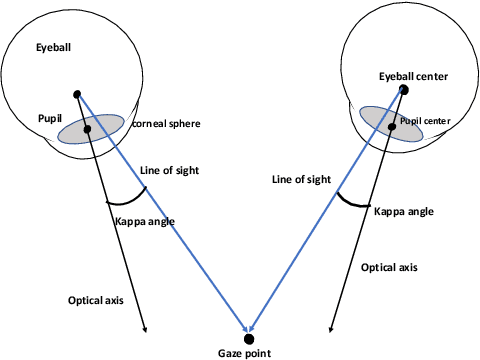
This work presents a next-generation human-robot interface that can infer and realize the user's manipulation intention via sight only. Specifically, we develop a system that integrates near-eye-tracking and robotic manipulation to enable user-specified actions (e.g., grasp, pick-and-place, etc), where visual information is merged with human attention to create a mapping for desired robot actions. To enable sight guided manipulation, a head-mounted near-eye-tracking device is developed to track the eyeball movements in real-time, so that the user's visual attention can be identified. To improve the grasping performance, a transformer based grasp model is then developed. Stacked transformer blocks are used to extract hierarchical features where the volumes of channels are expanded at each stage while squeezing the resolution of feature maps. Experimental validation demonstrates that the eye-tracking system yields low gaze estimation error and the grasping system yields promising results on multiple grasping datasets. This work is a proof of concept for gaze interaction-based assistive robot, which holds great promise to help the elder or upper limb disabilities in their daily lives. A demo video is available at \url{https://www.youtube.com/watch?v=yuZ1hukYUrM}.
When Transformer Meets Robotic Grasping: Exploits Context for Efficient Grasp Detection
Feb 24, 2022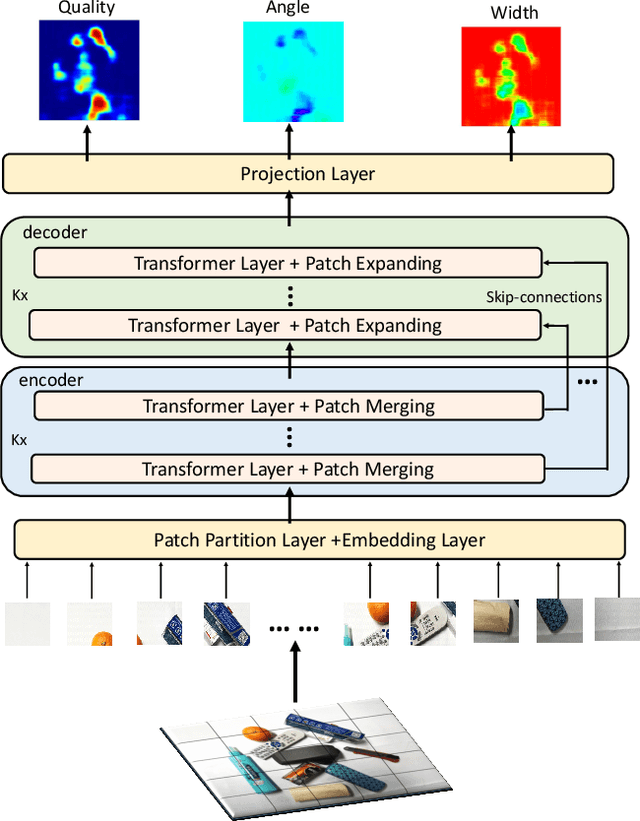
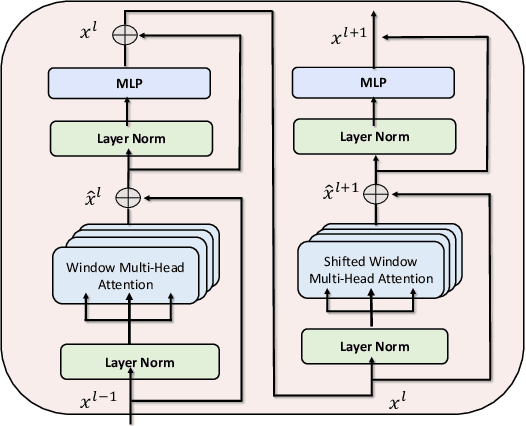


In this paper, we present a transformer-based architecture, namely TF-Grasp, for robotic grasp detection. The developed TF-Grasp framework has two elaborate designs making it well suitable for visual grasping tasks. The first key design is that we adopt the local window attention to capture local contextual information and detailed features of graspable objects. Then, we apply the cross window attention to model the long-term dependencies between distant pixels. Object knowledge, environmental configuration, and relationships between different visual entities are aggregated for subsequent grasp detection. The second key design is that we build a hierarchical encoder-decoder architecture with skip-connections, delivering shallow features from encoder to decoder to enable a multi-scale feature fusion. Due to the powerful attention mechanism, the TF-Grasp can simultaneously obtain the local information (i.e., the contours of objects), and model long-term connections such as the relationships between distinct visual concepts in clutter. Extensive computational experiments demonstrate that the TF-Grasp achieves superior results versus state-of-art grasping convolutional models and attain a higher accuracy of 97.99% and 94.6% on Cornell and Jacquard grasping datasets, respectively. Real-world experiments using a 7DoF Franka Emika Panda robot also demonstrate its capability of grasping unseen objects in a variety of scenarios. The code and pre-trained models will be available at https://github.com/WangShaoSUN/grasp-transformer