 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Task-Driven Diffusion-Based Policy with Affordance Learning for Generalizable Manipulation of Articulated Objects
Sep 18, 2025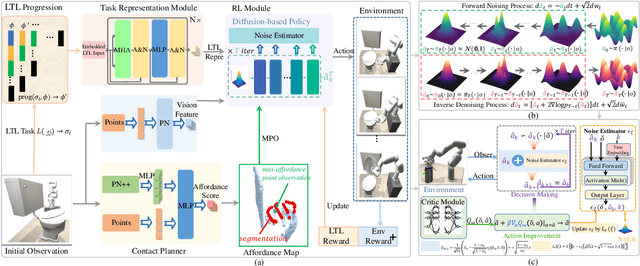
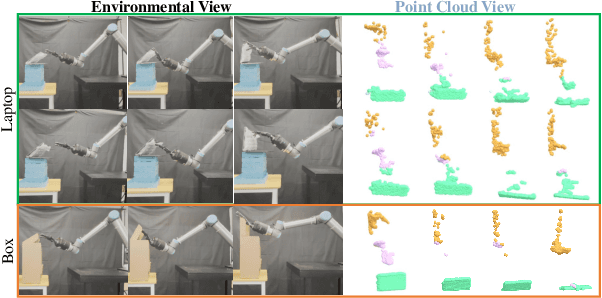


Despite recent advances in dexterous manipulations, the manipulation of articulated objects and generalization across different categories remain significant challenges. To address these issues, we introduce DART, a novel framework that enhances a diffusion-based policy with affordance learning and linear temporal logic (LTL) representations to improve the learning efficiency and generalizability of articulated dexterous manipulation. Specifically, DART leverages LTL to understand task semantics and affordance learning to identify optimal interaction points. The {diffusion-based policy} then generalizes these interactions across various categories. Additionally, we exploit an optimization method based on interaction data to refine actions, overcoming the limitations of traditional diffusion policies that typically rely on offline reinforcement learning or learning from demonstrations. Experimental results demonstrate that DART outperforms most existing methods in manipulation ability, generalization performance, transfer reasoning, and robustness. For more information, visit our project website at: https://sites.google.com/view/dart0257/.
Exploiting Hybrid Policy in Reinforcement Learning for Interpretable Temporal Logic Manipulation
Dec 29, 2024Reinforcement Learning (RL) based methods have been increasingly explored for robot learning. However, RL based methods often suffer from low sampling efficiency in the exploration phase, especially for long-horizon manipulation tasks, and generally neglect the semantic information from the task level, resulted in a delayed convergence or even tasks failure. To tackle these challenges, we propose a Temporal-Logic-guided Hybrid policy framework (HyTL) which leverages three-level decision layers to improve the agent's performance. Specifically, the task specifications are encoded via linear temporal logic (LTL) to improve performance and offer interpretability. And a waypoints planning module is designed with the feedback from the LTL-encoded task level as a high-level policy to improve the exploration efficiency. The middle-level policy selects which behavior primitives to execute, and the low-level policy specifies the corresponding parameters to interact with the environment. We evaluate HyTL on four challenging manipulation tasks, which demonstrate its effectiveness and interpretability. Our project is available at: https://sites.google.com/view/hytl-0257/.
LMT-GP: Combined Latent Mean-Teacher and Gaussian Process for Semi-supervised Low-light Image Enhancement
Aug 29, 2024



While recent low-light image enhancement (LLIE) methods have made significant advancements, they still face challenges in terms of low visual quality and weak generalization ability when applied to complex scenarios. To address these issues, we propose a semi-supervised method based on latent mean-teacher and Gaussian process, named LMT-GP. We first design a latent mean-teacher framework that integrates both labeled and unlabeled data, as well as their latent vectors, into model training. Meanwhile, we use a mean-teacher-assisted Gaussian process learning strategy to establish a connection between the latent and pseudo-latent vectors obtained from the labeled and unlabeled data. To guide the learning process, we utilize an assisted Gaussian process regression (GPR) loss function. Furthermore, we design a pseudo-label adaptation module (PAM) to ensure the reliability of the network learning. To demonstrate our method's generalization ability and effectiveness, we apply it to multiple LLIE datasets and high-level vision tasks. Experiment results demonstrate that our method achieves high generalization performance and image quality. The code is available at https://github.com/HFUT-CV/LMT-GP.
WorldAfford: Affordance Grounding based on Natural Language Instructions
May 21, 2024Affordance grounding aims to localize the interaction regions for the manipulated objects in the scene image according to given instructions. A critical challenge in affordance grounding is that the embodied agent should understand human instructions and analyze which tools in the environment can be used, as well as how to use these tools to accomplish the instructions. Most recent works primarily supports simple action labels as input instructions for localizing affordance regions, failing to capture complex human objectives. Moreover, these approaches typically identify affordance regions of only a single object in object-centric images, ignoring the object context and struggling to localize affordance regions of multiple objects in complex scenes for practical applications. To address this concern, for the first time, we introduce a new task of affordance grounding based on natural language instructions, extending it from previously using simple labels for complex human instructions. For this new task, we propose a new framework, WorldAfford. We design a novel Affordance Reasoning Chain-of-Thought Prompting to reason about affordance knowledge from LLMs more precisely and logically. Subsequently, we use SAM and CLIP to localize the objects related to the affordance knowledge in the image. We identify the affordance regions of the objects through an affordance region localization module. To benchmark this new task and validate our framework, an affordance grounding dataset, LLMaFF, is constructed. We conduct extensive experiments to verify that WorldAfford performs state-of-the-art on both the previous AGD20K and the new LLMaFF dataset. In particular, WorldAfford can localize the affordance regions of multiple objects and provide an alternative when objects in the environment cannot fully match the given instruction.
The RoboDepth Challenge: Methods and Advancements Towards Robust Depth Estimation
Jul 27, 2023



Accurate depth estimation under out-of-distribution (OoD) scenarios, such as adverse weather conditions, sensor failure, and noise contamination, is desirable for safety-critical applications. Existing depth estimation systems, however, suffer inevitably from real-world corruptions and perturbations and are struggled to provide reliable depth predictions under such cases. In this paper, we summarize the winning solutions from the RoboDepth Challenge -- an academic competition designed to facilitate and advance robust OoD depth estimation. This challenge was developed based on the newly established KITTI-C and NYUDepth2-C benchmarks. We hosted two stand-alone tracks, with an emphasis on robust self-supervised and robust fully-supervised depth estimation, respectively. Out of more than two hundred participants, nine unique and top-performing solutions have appeared, with novel designs ranging from the following aspects: spatial- and frequency-domain augmentations, masked image modeling, image restoration and super-resolution, adversarial training, diffusion-based noise suppression, vision-language pre-training, learned model ensembling, and hierarchical feature enhancement. Extensive experimental analyses along with insightful observations are drawn to better understand the rationale behind each design. We hope this challenge could lay a solid foundation for future research on robust and reliable depth estimation and beyond. The datasets, competition toolkit, workshop recordings, and source code from the winning teams are publicly available on the challenge website.
Lightweight Neural Path Planning
Jul 20, 2023Learning-based path planning is becoming a promising robot navigation methodology due to its adaptability to various environments. However, the expensive computing and storage associated with networks impose significant challenges for their deployment on low-cost robots. Motivated by this practical challenge, we develop a lightweight neural path planning architecture with a dual input network and a hybrid sampler for resource-constrained robotic systems. Our architecture is designed with efficient task feature extraction and fusion modules to translate the given planning instance into a guidance map. The hybrid sampler is then applied to restrict the planning within the prospective regions indicated by the guide map. To enable the network training, we further construct a publicly available dataset with various successful planning instances. Numerical simulations and physical experiments demonstrate that, compared with baseline approaches, our approach has nearly an order of magnitude fewer model size and five times lower computational while achieving promising performance. Besides, our approach can also accelerate the planning convergence process with fewer planning iterations compared to sample-based methods.
A Nested U-Structure for Instrument Segmentation in Robotic Surgery
Jul 17, 2023



Robot-assisted surgery has made great progress with the development of medical imaging and robotics technology. Medical scene understanding can greatly improve surgical performance while the semantic segmentation of the robotic instrument is a key enabling technology for robot-assisted surgery. However, how to locate an instrument's position and estimate their pose in complex surgical environments is still a challenging fundamental problem. In this paper, pixel-wise instrument segmentation is investigated. The contributions of the paper are twofold: 1) We proposed a two-level nested U-structure model, which is an encoder-decoder architecture with skip-connections and each layer of the network structure adopts a U-structure instead of a simple superposition of convolutional layers. The model can capture more context information from multiple scales and better fuse the local and global information to achieve high-quality segmentation. 2) Experiments have been conducted to qualitatively and quantitatively show the performance of our approach on three segmentation tasks: the binary segmentation, the parts segmentation, and the type segmentation, respectively.
Vision-Based Reactive Planning and Control of Quadruped Robots in Unstructured Dynamic Environments
Jul 17, 2023
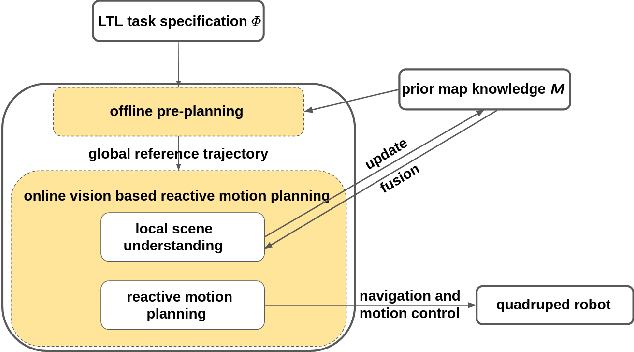

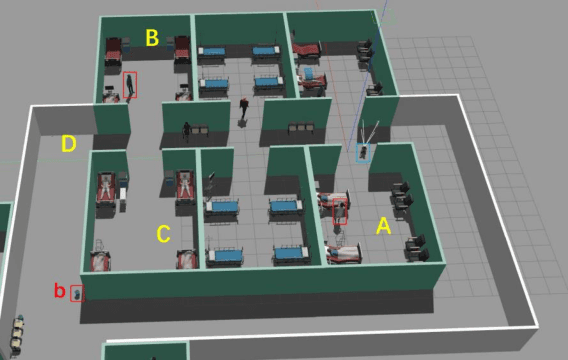
Quadruped robots have received increasing attention for the past few years. However, existing works primarily focus on static environments or assume the robot has full observations of the environment. This limits their practical applications since real-world environments are often dynamic and partially observable. To tackle these issues, vision-based reactive planning and control (V-RPC) is developed in this work. The V-RPC comprises two modules: offline pre-planning and online reactive planning. The pre-planning phase generates a reference trajectory over continuous workspace via sampling-based methods using prior environmental knowledge, given an LTL specification. The online reactive module dynamically adjusts the reference trajectory and control based on the robot's real-time visual perception to adapt to environmental changes.
Model-free Motion Planning of Autonomous Agents for Complex Tasks in Partially Observable Environments
Apr 30, 2023Motion planning of autonomous agents in partially known environments with incomplete information is a challenging problem, particularly for complex tasks. This paper proposes a model-free reinforcement learning approach to address this problem. We formulate motion planning as a probabilistic-labeled partially observable Markov decision process (PL-POMDP) problem and use linear temporal logic (LTL) to express the complex task. The LTL formula is then converted to a limit-deterministic generalized B\"uchi automaton (LDGBA). The problem is redefined as finding an optimal policy on the product of PL-POMDP with LDGBA based on model-checking techniques to satisfy the complex task. We implement deep Q learning with long short-term memory (LSTM) to process the observation history and task recognition. Our contributions include the proposed method, the utilization of LTL and LDGBA, and the LSTM-enhanced deep Q learning. We demonstrate the applicability of the proposed method by conducting simulations in various environments, including grid worlds, a virtual office, and a multi-agent warehouse. The simulation results demonstrate that our proposed method effectively addresses environment, action, and observation uncertainties. This indicates its potential for real-world applications, including the control of unmanned aerial vehicles (UAVs).
Exploiting Transformer in Reinforcement Learning for Interpretable Temporal Logic Motion Planning
Sep 27, 2022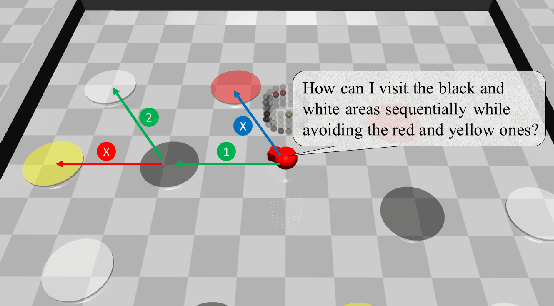
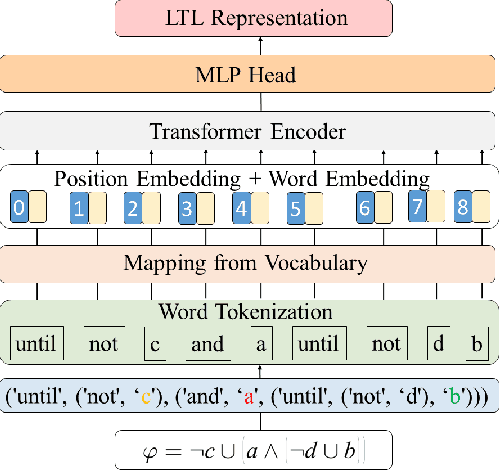

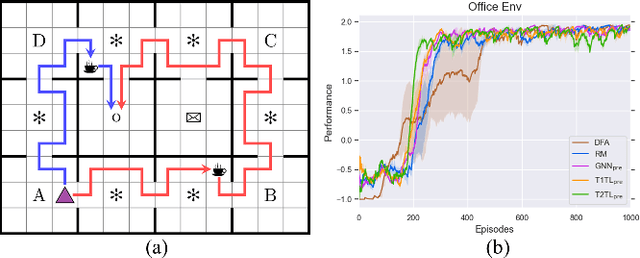
Automaton based approaches have enabled robots to perform various complex tasks. However, most existing automaton based algorithms highly rely on the manually customized representation of states for the considered task, limiting its applicability in deep reinforcement learning algorithms. To address this issue, by incorporating Transformer into reinforcement learning, we develop a Double-Transformer-guided Temporal Logic framework (T2TL) that exploits the structural feature of Transformer twice, i.e., first encoding the LTL instruction via the Transformer module for efficient understanding of task instructions during the training and then encoding the context variable via the Transformer again for improved task performance. Particularly, the LTL instruction is specified by co-safe LTL. As a semantics-preserving rewriting operation, LTL progression is exploited to decompose the complex task into learnable sub-goals, which not only converts non-Markovian reward decision process to Markovian ones, but also improves the sampling efficiency by simultaneous learning of multiple sub-tasks. An environment-agnostic LTL pre-training scheme is further incorporated to facilitate the learning of the Transformer module resulting in improved representation of LTL. The simulation and experiment results demonstrate the effectiveness of the T2TL framework.