 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Hybrid Policy in Reinforcement Learning for Interpretable Temporal Logic Manipulation
Dec 29, 2024Reinforcement Learning (RL) based methods have been increasingly explored for robot learning. However, RL based methods often suffer from low sampling efficiency in the exploration phase, especially for long-horizon manipulation tasks, and generally neglect the semantic information from the task level, resulted in a delayed convergence or even tasks failure. To tackle these challenges, we propose a Temporal-Logic-guided Hybrid policy framework (HyTL) which leverages three-level decision layers to improve the agent's performance. Specifically, the task specifications are encoded via linear temporal logic (LTL) to improve performance and offer interpretability. And a waypoints planning module is designed with the feedback from the LTL-encoded task level as a high-level policy to improve the exploration efficiency. The middle-level policy selects which behavior primitives to execute, and the low-level policy specifies the corresponding parameters to interact with the environment. We evaluate HyTL on four challenging manipulation tasks, which demonstrate its effectiveness and interpretability. Our project is available at: https://sites.google.com/view/hytl-0257/.
Asymptotic Tracking Control of Uncertain MIMO Nonlinear Systems with Less Conservative Controllability Conditions
Aug 03, 2022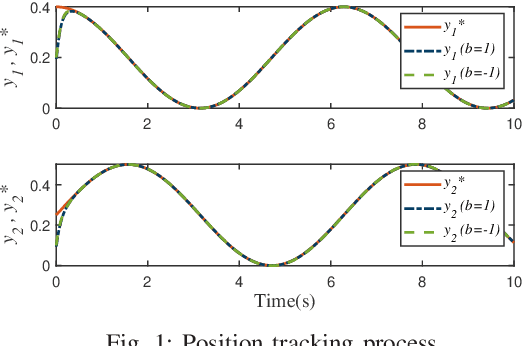
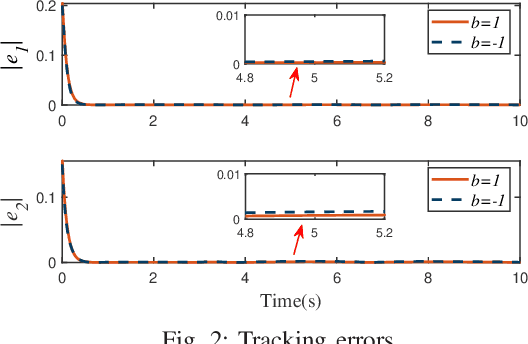
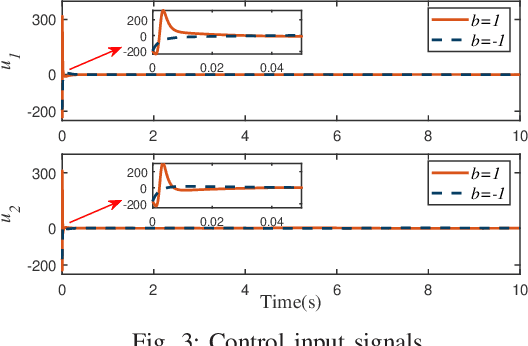
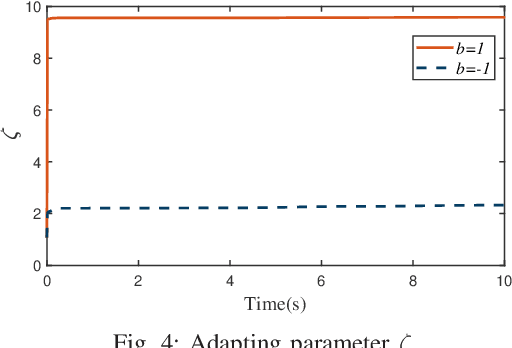
For uncertain multiple inputs multi-outputs (MIMO) nonlinear systems, it is nontrivial to achieve asymptotic tracking, and most existing methods normally demand certain controllability conditions that are rather restrictive or even impractical if unexpected actuator faults are involved. In this note, we present a method capable of achieving zero-error steady-state tracking with less conservative (more practical) controllability condition. By incorporating a novel Nussbaum gain technique and some positive integrable function into the control design, we develop a robust adaptive asymptotic tracking control scheme for the system with time-varying control gain being unknown its magnitude and direction. By resorting to the existence of some feasible auxiliary matrix, the current state-of-art controllability condition is further relaxed, which enlarges the class of systems that can be considered in the proposed control scheme. All the closed-loop signals are ensured to be globally ultimately uniformly bounded. Moreover, such control methodology is further extended to the case involving intermittent actuator faults, with application to robotic systems. Finally, simulation studies are carried out to demonstrate the effectiveness and flexibility of this method.