 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement learning with timed constraints for robotics motion planning
Dec 31, 2025Robotic systems operating in dynamic and uncertain environments increasingly require planners that satisfy complex task sequences while adhering to strict temporal constraints. Metric Interval Temporal Logic (MITL) offers a formal and expressive framework for specifying such time-bounded requirements; however, integrating MITL with reinforcement learning (RL) remains challenging due to stochastic dynamics and partial observability. This paper presents a unified automata-based RL framework for synthesizing policies in both Markov Decision Processes (MDPs) and Partially Observable Markov Decision Processes (POMDPs) under MITL specifications. MITL formulas are translated into Timed Limit-Deterministic Generalized Büchi Automata (Timed-LDGBA) and synchronized with the underlying decision process to construct product timed models suitable for Q-learning. A simple yet expressive reward structure enforces temporal correctness while allowing additional performance objectives. The approach is validated in three simulation studies: a $5 \times 5$ grid-world formulated as an MDP, a $10 \times 10$ grid-world formulated as a POMDP, and an office-like service-robot scenario. Results demonstrate that the proposed framework consistently learns policies that satisfy strict time-bounded requirements under stochastic transitions, scales to larger state spaces, and remains effective in partially observable environments, highlighting its potential for reliable robotic planning in time-critical and uncertain settings.
Learning-based agricultural management in partially observable environments subject to climate variability
Jan 02, 2024Agricultural management, with a particular focus on fertilization strategies, holds a central role in shaping crop yield, economic profitability, and environmental sustainability. While conventional guidelines offer valuable insights, their efficacy diminishes when confronted with extreme weather conditions, such as heatwaves and droughts. In this study, we introduce an innovative framework that integrates Deep Reinforcement Learning (DRL) with Recurrent Neural Networks (RNNs). Leveraging the Gym-DSSAT simulator, we train an intelligent agent to master optimal nitrogen fertilization management. Through a series of simulation experiments conducted on corn crops in Iowa, we compare Partially Observable Markov Decision Process (POMDP) models with Markov Decision Process (MDP) models. Our research underscores the advantages of utilizing sequential observations in developing more efficient nitrogen input policies. Additionally, we explore the impact of climate variability, particularly during extreme weather events, on agricultural outcomes and management. Our findings demonstrate the adaptability of fertilization policies to varying climate conditions. Notably, a fixed policy exhibits resilience in the face of minor climate fluctuations, leading to commendable corn yields, cost-effectiveness, and environmental conservation. However, our study illuminates the need for agent retraining to acquire new optimal policies under extreme weather events. This research charts a promising course toward adaptable fertilization strategies that can seamlessly align with dynamic climate scenarios, ultimately contributing to the optimization of crop management practices.
Model-free Motion Planning of Autonomous Agents for Complex Tasks in Partially Observable Environments
Apr 30, 2023Motion planning of autonomous agents in partially known environments with incomplete information is a challenging problem, particularly for complex tasks. This paper proposes a model-free reinforcement learning approach to address this problem. We formulate motion planning as a probabilistic-labeled partially observable Markov decision process (PL-POMDP) problem and use linear temporal logic (LTL) to express the complex task. The LTL formula is then converted to a limit-deterministic generalized B\"uchi automaton (LDGBA). The problem is redefined as finding an optimal policy on the product of PL-POMDP with LDGBA based on model-checking techniques to satisfy the complex task. We implement deep Q learning with long short-term memory (LSTM) to process the observation history and task recognition. Our contributions include the proposed method, the utilization of LTL and LDGBA, and the LSTM-enhanced deep Q learning. We demonstrate the applicability of the proposed method by conducting simulations in various environments, including grid worlds, a virtual office, and a multi-agent warehouse. The simulation results demonstrate that our proposed method effectively addresses environment, action, and observation uncertainties. This indicates its potential for real-world applications, including the control of unmanned aerial vehicles (UAVs).
Intelligent Traffic Light via Policy-based Deep Reinforcement Learning
Dec 27, 2021
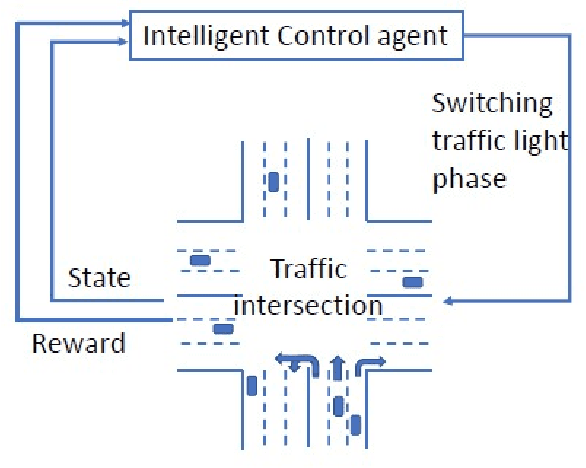

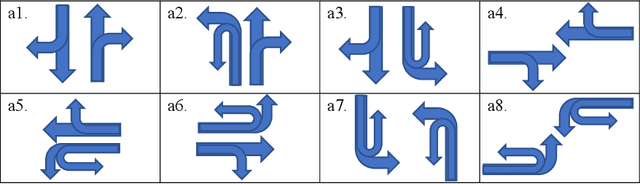
Intelligent traffic lights in smart cities can optimally reduce traffic congestion. In this study, we employ reinforcement learning to train the control agent of a traffic light on a simulator of urban mobility. As a difference from existing works, a policy-based deep reinforcement learning method, Proximal Policy Optimization (PPO), is utilized other than value-based methods such as Deep Q Network (DQN) and Double DQN (DDQN). At first, the obtained optimal policy from PPO is compared to those from DQN and DDQN. It is found that the policy from PPO performs better than the others. Next, instead of the fixed-interval traffic light phases, we adopt the light phases with variable time intervals, which result in a better policy to pass the traffic flow. Then, the effects of environment and action disturbances are studied to demonstrate the learning-based controller is robust. At last, we consider unbalanced traffic flows and find that an intelligent traffic light can perform moderately well for the unbalanced traffic scenarios, although it learns the optimal policy from the balanced traffic scenarios only.