 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement learning with timed constraints for robotics motion planning
Dec 31, 2025Robotic systems operating in dynamic and uncertain environments increasingly require planners that satisfy complex task sequences while adhering to strict temporal constraints. Metric Interval Temporal Logic (MITL) offers a formal and expressive framework for specifying such time-bounded requirements; however, integrating MITL with reinforcement learning (RL) remains challenging due to stochastic dynamics and partial observability. This paper presents a unified automata-based RL framework for synthesizing policies in both Markov Decision Processes (MDPs) and Partially Observable Markov Decision Processes (POMDPs) under MITL specifications. MITL formulas are translated into Timed Limit-Deterministic Generalized Büchi Automata (Timed-LDGBA) and synchronized with the underlying decision process to construct product timed models suitable for Q-learning. A simple yet expressive reward structure enforces temporal correctness while allowing additional performance objectives. The approach is validated in three simulation studies: a $5 \times 5$ grid-world formulated as an MDP, a $10 \times 10$ grid-world formulated as a POMDP, and an office-like service-robot scenario. Results demonstrate that the proposed framework consistently learns policies that satisfy strict time-bounded requirements under stochastic transitions, scales to larger state spaces, and remains effective in partially observable environments, highlighting its potential for reliable robotic planning in time-critical and uncertain settings.
Developing and Integrating Trust Modeling into Multi-Objective Reinforcement Learning for Intelligent Agricultural Management
May 16, 2025



Precision agriculture, enhanced by artificial intelligence (AI), offers promising tools such as remote sensing, intelligent irrigation, fertilization management, and crop simulation to improve agricultural efficiency and sustainability. Reinforcement learning (RL), in particular, has outperformed traditional methods in optimizing yields and resource management. However, widespread AI adoption is limited by gaps between algorithmic recommendations and farmers' practical experience, local knowledge, and traditional practices. To address this, our study emphasizes Human-AI Interaction (HAII), focusing on transparency, usability, and trust in RL-based farm management. We employ a well-established trust framework - comprising ability, benevolence, and integrity - to develop a novel mathematical model quantifying farmers' confidence in AI-based fertilization strategies. Surveys conducted with farmers for this research reveal critical misalignments, which are integrated into our trust model and incorporated into a multi-objective RL framework. Unlike prior methods, our approach embeds trust directly into policy optimization, ensuring AI recommendations are technically robust, economically feasible, context-aware, and socially acceptable. By aligning technical performance with human-centered trust, this research supports broader AI adoption in agriculture.
Mechanics and Design of Metastructured Auxetic Patches with Bio-inspired Materials
Jan 08, 2025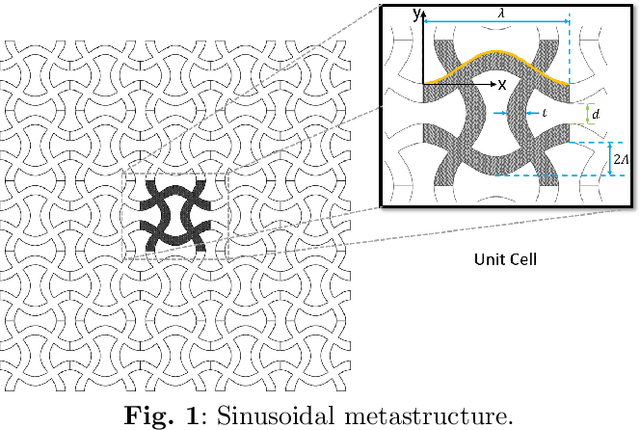
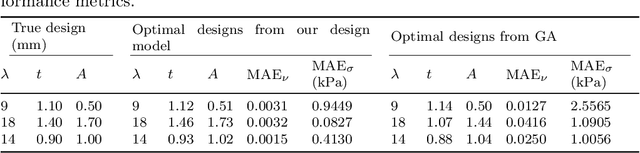
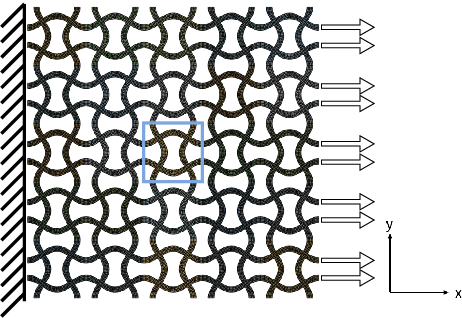
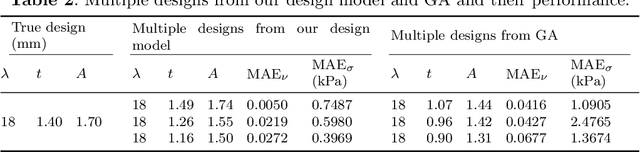
Metastructured auxetic patches, characterized by negative Poisson's ratios, offer unique mechanical properties that closely resemble the behavior of human tissues and organs. As a result, these patches have gained significant attention for their potential applications in organ repair and tissue regeneration. This study focuses on neural networks-based computational modeling of auxetic patches with a sinusoidal metastructure fabricated from silk fibroin, a bio-inspired material known for its biocompatibility and strength. The primary objective of this research is to introduce a novel, data-driven framework for patch design. To achieve this, we conducted experimental fabrication and mechanical testing to determine material properties and validate the corresponding finite element models. Finite element simulations were then employed to generate the necessary data, while greedy sampling, an active learning technique, was utilized to reduce the computational cost associated with data labeling. Two neural networks were trained to accurately predict Poisson's ratios and stresses for strains up to 15\%, respectively. Both models achieved $R^2$ scores exceeding 0.995, which indicates highly reliable predictions. Building on this, we developed a neural network-based design model capable of tailoring patch designs to achieve specific mechanical properties. This model demonstrated superior performance when compared to traditional optimization methods, such as genetic algorithms, by providing more efficient and precise design solutions. The proposed framework represents a significant advancement in the design of bio-inspired metastructures for medical applications, paving the way for future innovations in tissue engineering and regenerative medicine.
Intelligent Agricultural Management Considering N$_2$O Emission and Climate Variability with Uncertainties
Feb 13, 2024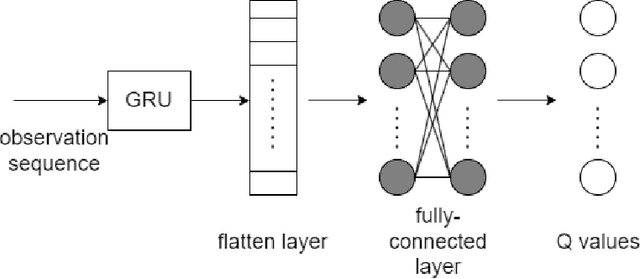



This study examines how artificial intelligence (AI), especially Reinforcement Learning (RL), can be used in farming to boost crop yields, fine-tune nitrogen use and watering, and reduce nitrate runoff and greenhouse gases, focusing on Nitrous Oxide (N$_2$O) emissions from soil. Facing climate change and limited agricultural knowledge, we use Partially Observable Markov Decision Processes (POMDPs) with a crop simulator to model AI agents' interactions with farming environments. We apply deep Q-learning with Recurrent Neural Network (RNN)-based Q networks for training agents on optimal actions. Also, we develop Machine Learning (ML) models to predict N$_2$O emissions, integrating these predictions into the simulator. Our research tackles uncertainties in N$_2$O emission estimates with a probabilistic ML approach and climate variability through a stochastic weather model, offering a range of emission outcomes to improve forecast reliability and decision-making. By incorporating climate change effects, we enhance agents' climate adaptability, aiming for resilient agricultural practices. Results show these agents can align crop productivity with environmental concerns by penalizing N$_2$O emissions, adapting effectively to climate shifts like warmer temperatures and less rain. This strategy improves farm management under climate change, highlighting AI's role in sustainable agriculture.
Learning-based agricultural management in partially observable environments subject to climate variability
Jan 02, 2024Agricultural management, with a particular focus on fertilization strategies, holds a central role in shaping crop yield, economic profitability, and environmental sustainability. While conventional guidelines offer valuable insights, their efficacy diminishes when confronted with extreme weather conditions, such as heatwaves and droughts. In this study, we introduce an innovative framework that integrates Deep Reinforcement Learning (DRL) with Recurrent Neural Networks (RNNs). Leveraging the Gym-DSSAT simulator, we train an intelligent agent to master optimal nitrogen fertilization management. Through a series of simulation experiments conducted on corn crops in Iowa, we compare Partially Observable Markov Decision Process (POMDP) models with Markov Decision Process (MDP) models. Our research underscores the advantages of utilizing sequential observations in developing more efficient nitrogen input policies. Additionally, we explore the impact of climate variability, particularly during extreme weather events, on agricultural outcomes and management. Our findings demonstrate the adaptability of fertilization policies to varying climate conditions. Notably, a fixed policy exhibits resilience in the face of minor climate fluctuations, leading to commendable corn yields, cost-effectiveness, and environmental conservation. However, our study illuminates the need for agent retraining to acquire new optimal policies under extreme weather events. This research charts a promising course toward adaptable fertilization strategies that can seamlessly align with dynamic climate scenarios, ultimately contributing to the optimization of crop management practices.
Model-free Motion Planning of Autonomous Agents for Complex Tasks in Partially Observable Environments
Apr 30, 2023Motion planning of autonomous agents in partially known environments with incomplete information is a challenging problem, particularly for complex tasks. This paper proposes a model-free reinforcement learning approach to address this problem. We formulate motion planning as a probabilistic-labeled partially observable Markov decision process (PL-POMDP) problem and use linear temporal logic (LTL) to express the complex task. The LTL formula is then converted to a limit-deterministic generalized B\"uchi automaton (LDGBA). The problem is redefined as finding an optimal policy on the product of PL-POMDP with LDGBA based on model-checking techniques to satisfy the complex task. We implement deep Q learning with long short-term memory (LSTM) to process the observation history and task recognition. Our contributions include the proposed method, the utilization of LTL and LDGBA, and the LSTM-enhanced deep Q learning. We demonstrate the applicability of the proposed method by conducting simulations in various environments, including grid worlds, a virtual office, and a multi-agent warehouse. The simulation results demonstrate that our proposed method effectively addresses environment, action, and observation uncertainties. This indicates its potential for real-world applications, including the control of unmanned aerial vehicles (UAVs).
Intelligent Traffic Light via Policy-based Deep Reinforcement Learning
Dec 27, 2021
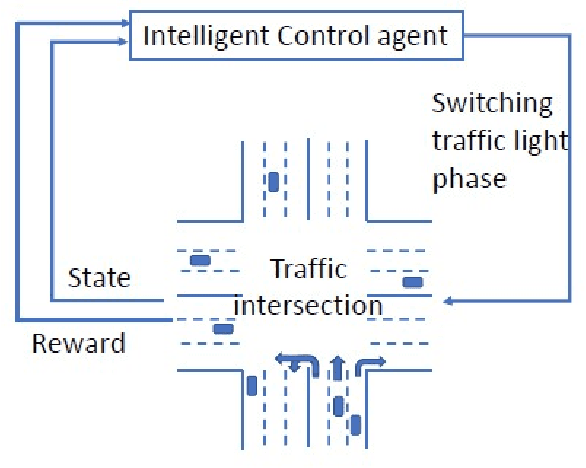

Intelligent traffic lights in smart cities can optimally reduce traffic congestion. In this study, we employ reinforcement learning to train the control agent of a traffic light on a simulator of urban mobility. As a difference from existing works, a policy-based deep reinforcement learning method, Proximal Policy Optimization (PPO), is utilized other than value-based methods such as Deep Q Network (DQN) and Double DQN (DDQN). At first, the obtained optimal policy from PPO is compared to those from DQN and DDQN. It is found that the policy from PPO performs better than the others. Next, instead of the fixed-interval traffic light phases, we adopt the light phases with variable time intervals, which result in a better policy to pass the traffic flow. Then, the effects of environment and action disturbances are studied to demonstrate the learning-based controller is robust. At last, we consider unbalanced traffic flows and find that an intelligent traffic light can perform moderately well for the unbalanced traffic scenarios, although it learns the optimal policy from the balanced traffic scenarios only.
Online Motion Planning with Soft Timed Temporal Logic in Dynamic and Unknown Environment
Oct 21, 2021
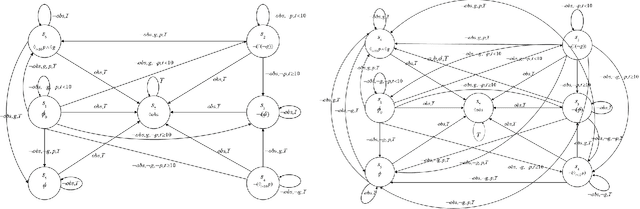
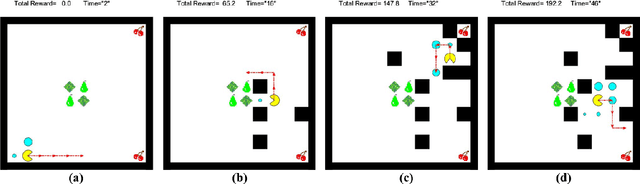
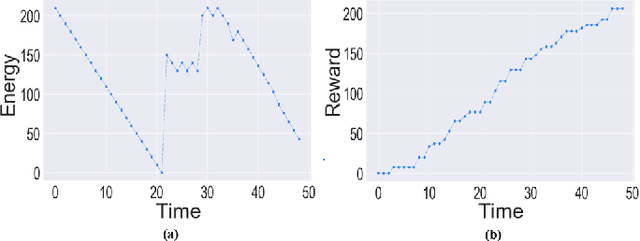
Motion planning of an autonomous system with high-level specifications has wide applications. However, research of formal languages involving timed temporal logic is still under investigation. Furthermore, many existing results rely on a key assumption that user-specified tasks are feasible in the given environment. Challenges arise when the operating environment is dynamic and unknown since the environment can be found prohibitive, leading to potentially conflicting tasks where pre-specified timed missions cannot be fully satisfied. Such issues become even more challenging when considering timed requirements. To address these challenges, this work proposes a control framework that considers hard constraints to enforce safety requirements and soft constraints to enable task relaxation. The metric interval temporal logic (MITL) specifications are employed to deal with time constraints. By constructing a relaxed timed product automaton, an online motion planning strategy is synthesized with a receding horizon controller to generate policies, achieving multiple objectives in decreasing order of priority 1) formally guarantee the satisfaction of hard safety constraints; 2) mostly fulfill soft timed tasks; and 3) collect time-varying rewards as much as possible. Another novelty of the relaxed structure is to consider violations of both time and tasks for infeasible cases. Simulation results are provided to validate the proposed approach.
Modular Deep Reinforcement Learning for Continuous Motion Planning with Temporal Logic
Feb 24, 2021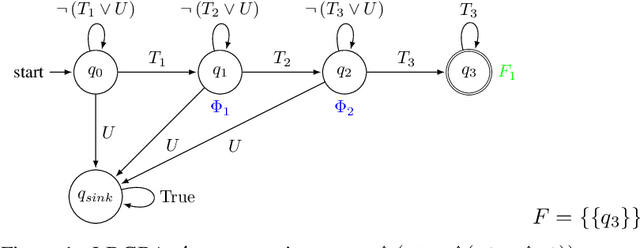
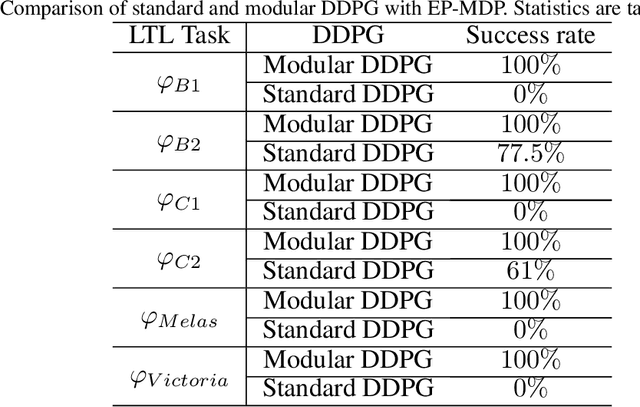
This paper investigates the motion planning of autonomous dynamical systems modeled by Markov decision processes (MDP) with unknown transition probabilities over continuous state and action spaces. Linear temporal logic (LTL) is used to specify high-level tasks over infinite horizon, which can be converted into a limit deterministic generalized B\"uchi automaton (LDGBA) with several accepting sets. The novelty is to design an embedded product MDP (EP-MDP) between the LDGBA and the MDP by incorporating a synchronous tracking-frontier function to record unvisited accepting sets of the automaton, and to facilitate the satisfaction of the accepting conditions. The proposed LDGBA-based reward shaping and discounting schemes for the model-free reinforcement learning (RL) only depend on the EP-MDP states and can overcome the issues of sparse rewards. Rigorous analysis shows that any RL method that optimizes the expected discounted return is guaranteed to find an optimal policy whose traces maximize the satisfaction probability. A modular deep deterministic policy gradient (DDPG) is then developed to generate such policies over continuous state and action spaces. The performance of our framework is evaluated via an array of OpenAI gym environments.
Reinforcement Learning Based Temporal Logic Control with Soft Constraints Using Limit-deterministic Generalized Buchi Automata
Jan 31, 2021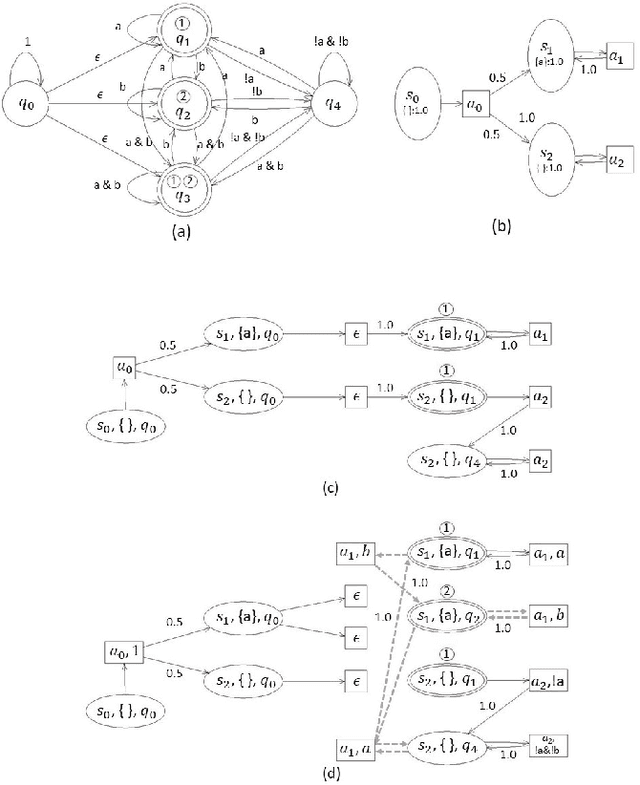
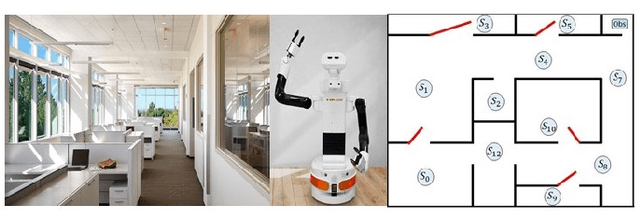
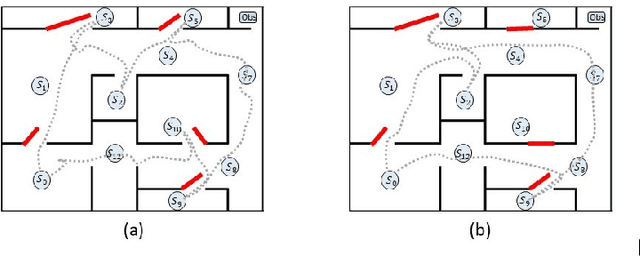
This paper studies the control synthesis of motion planning subject to uncertainties. The uncertainties are considered in robot motion and environment properties, giving rise to the probabilistic labeled Markov decision process (MDP). A model-free reinforcement learning (RL) is developed to generate a finite-memory control policy to satisfy high-level tasks expressed in linear temporal logic (LTL) formulas. One of the novelties is to translate LTL into a limit deterministic generalized B\"uchi automaton (LDGBA) and develop a corresponding embedded LDGBA (E-LDGBA) by incorporating a tracking-frontier function to overcome the issue of sparse accepting rewards, resulting in improved learning performance without increasing computational complexity. Due to potentially conflicting tasks, a relaxed product MDP is developed to allow the agent to revise its motion plan without strictly following the desired LTL constraints if the desired tasks can only be partially fulfilled. An expected return composed of violation rewards and accepting rewards is developed. The designed violation function quantifies the differences between the revised and the desired motion planning, while the accepting rewards are designed to enforce the satisfaction of the acceptance condition of the relaxed product MDP. Rigorous analysis shows that any RL algorithm that optimizes the expected return is guaranteed to find policies that, in decreasing order, can 1) satisfy acceptance condition of relaxed product MDP and 2) reduce the violation cost over long-term behaviors. Also, we validate the control synthesis approach via simulation and experimental results.