 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Motion Planning with Soft Timed Temporal Logic in Dynamic and Unknown Environment
Oct 21, 2021
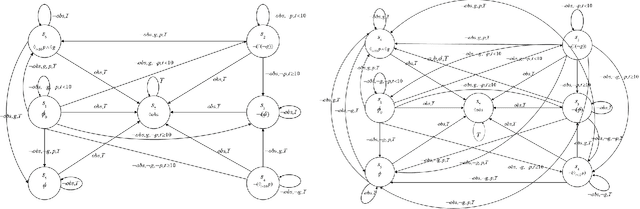
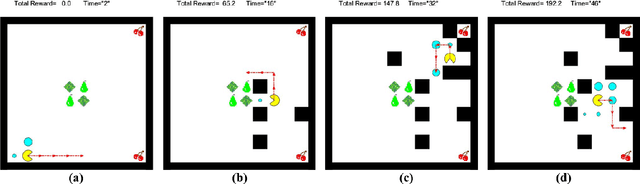
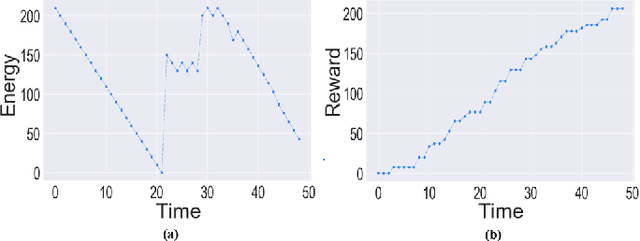
Motion planning of an autonomous system with high-level specifications has wide applications. However, research of formal languages involving timed temporal logic is still under investigation. Furthermore, many existing results rely on a key assumption that user-specified tasks are feasible in the given environment. Challenges arise when the operating environment is dynamic and unknown since the environment can be found prohibitive, leading to potentially conflicting tasks where pre-specified timed missions cannot be fully satisfied. Such issues become even more challenging when considering timed requirements. To address these challenges, this work proposes a control framework that considers hard constraints to enforce safety requirements and soft constraints to enable task relaxation. The metric interval temporal logic (MITL) specifications are employed to deal with time constraints. By constructing a relaxed timed product automaton, an online motion planning strategy is synthesized with a receding horizon controller to generate policies, achieving multiple objectives in decreasing order of priority 1) formally guarantee the satisfaction of hard safety constraints; 2) mostly fulfill soft timed tasks; and 3) collect time-varying rewards as much as possible. Another novelty of the relaxed structure is to consider violations of both time and tasks for infeasible cases. Simulation results are provided to validate the proposed approach.
Reinforcement Learning Based Temporal Logic Control with Maximum Probabilistic Satisfaction
Oct 15, 2020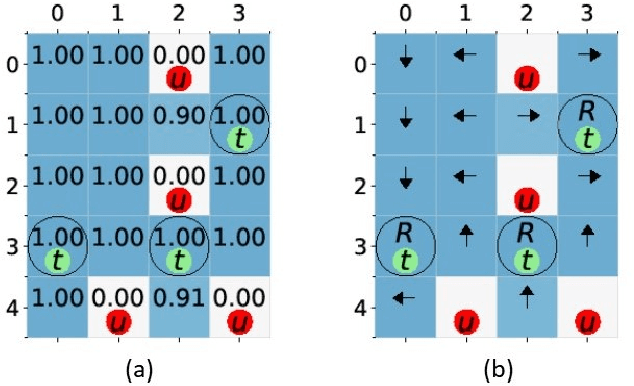
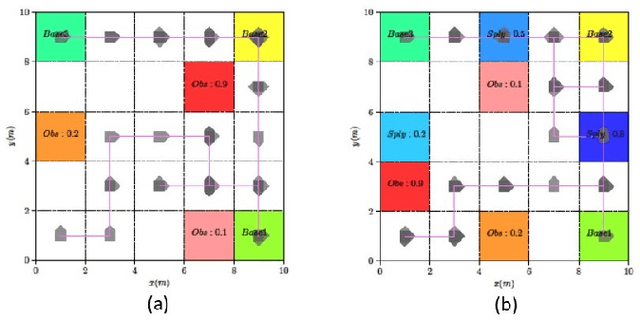
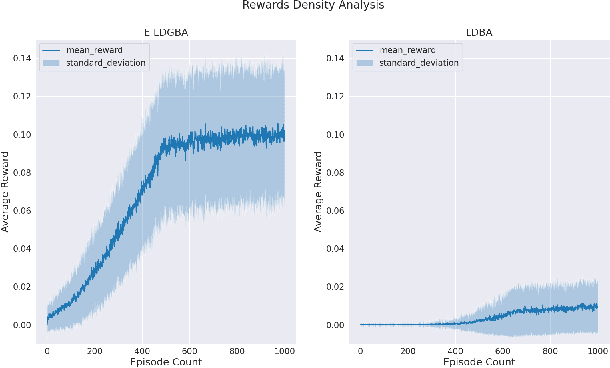
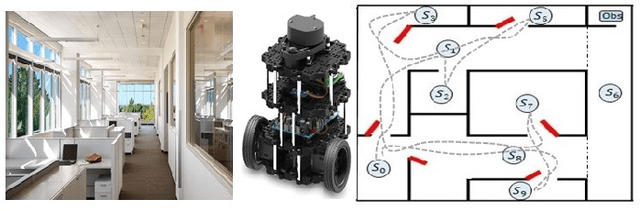
This paper presents a model-free reinforcement learning (RL) algorithm to synthesize a control policy that maximizes the satisfaction probability of linear temporal logic (LTL) specifications. Due to the consideration of environment and motion uncertainties, we model the robot motion as a probabilistic labeled Markov decision process with unknown transition probabilities and unknown probabilistic label functions. The LTL task specification is converted to a limit deterministic generalized B\"uchi automaton (LDGBA) with several accepting sets to maintain dense rewards during learning. The novelty of applying LDGBA is to construct an embedded LDGBA (E-LDGBA) by designing a synchronous tracking-frontier function, which enables the record of non-visited accepting sets without increasing dimensional and computational complexity. With appropriate dependent reward and discount functions, rigorous analysis shows that any method that optimizes the expected discount return of the RL-based approach is guaranteed to find the optimal policy that maximizes the satisfaction probability of the LTL specifications. A model-free RL-based motion planning strategy is developed to generate the optimal policy in this paper. The effectiveness of the RL-based control synthesis is demonstrated via simulation and experimental results.