 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederate the Router: Learning Language Model Routers with Sparse and Decentralized Evaluations
Jan 29, 2026Large language models (LLMs) are increasingly accessed as remotely hosted services by edge and enterprise clients that cannot run frontier models locally. Since models vary widely in capability and price, routing queries to models that balance quality and inference cost is essential. Existing router approaches assume access to centralized query-model evaluation data. However, these data are often fragmented across clients, such as end users and organizations, and are privacy-sensitive, which makes centralizing data infeasible. Additionally, per-client router training is ineffective since local evaluation data is limited and covers only a restricted query distribution and a biased subset of model evaluations. We introduce the first federated framework for LLM routing, enabling clients to learn a shared routing policy from local offline query-model evaluation data. Our framework supports both parametric multilayer perceptron router and nonparametric K-means router under heterogeneous client query distributions and non-uniform model coverage. Across two benchmarks, federated collaboration improves the accuracy-cost frontier over client-local routers, both via increased effective model coverage and better query generalization. Our theoretical results also validate that federated training reduces routing suboptimality.
LOCUS: Low-Dimensional Model Embeddings for Efficient Model Exploration, Comparison, and Selection
Jan 28, 2026The rapidly growing ecosystem of Large Language Models (LLMs) makes it increasingly challenging to manage and utilize the vast and dynamic pool of models effectively. We propose LOCUS, a method that produces low-dimensional vector embeddings that compactly represent a language model's capabilities across queries. LOCUS is an attention-based approach that generates embeddings by a deterministic forward pass over query encodings and evaluation scores via an encoder model, enabling seamless incorporation of new models to the pool and refinement of existing model embeddings without having to perform any retraining. We additionally train a correctness predictor that uses model embeddings and query encodings to achieve state-of-the-art routing accuracy on unseen queries. Experiments show that LOCUS needs up to 4.8x fewer query evaluation samples than baselines to produce informative and robust embeddings. Moreover, the learned embedding space is geometrically meaningful: proximity reflects model similarity, enabling a range of downstream applications including model comparison and clustering, model portfolio selection, and resilient proxies of unavailable models.
ACEGEN: Reinforcement learning of generative chemical agents for drug discovery
May 07, 2024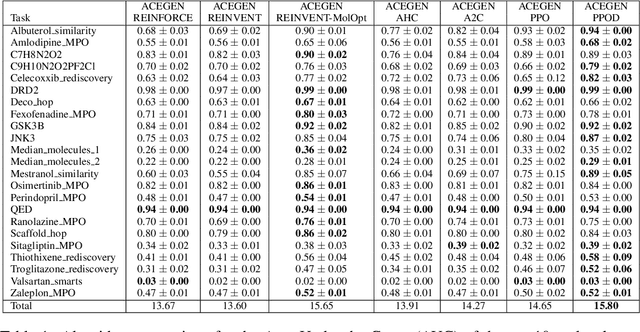


In recent years, reinforcement learning (RL) has emerged as a valuable tool in drug design, offering the potential to propose and optimize molecules with desired properties. However, striking a balance between capability, flexibility, and reliability remains challenging due to the complexity of advanced RL algorithms and the significant reliance on specialized code. In this work, we introduce ACEGEN, a comprehensive and streamlined toolkit tailored for generative drug design, built using TorchRL, a modern decision-making library that offers efficient and thoroughly tested reusable components. ACEGEN provides a robust, flexible, and efficient platform for molecular design. We validate its effectiveness by benchmarking it across various algorithms and conducting multiple drug discovery case studies. ACEGEN is accessible at https://github.com/acellera/acegen-open.
Intelligent Agricultural Management Considering N$_2$O Emission and Climate Variability with Uncertainties
Feb 13, 2024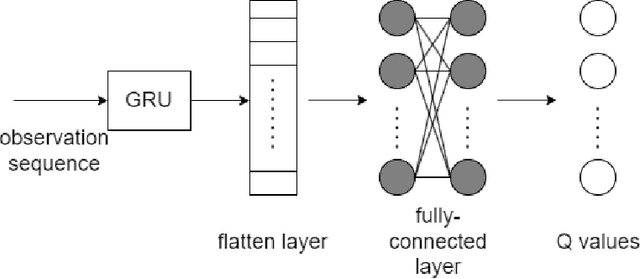



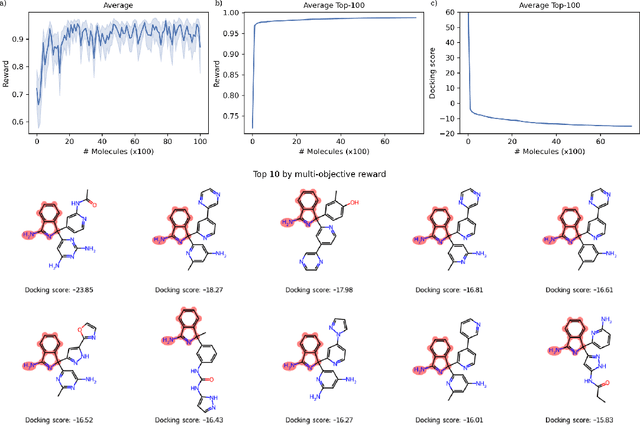
This study examines how artificial intelligence (AI), especially Reinforcement Learning (RL), can be used in farming to boost crop yields, fine-tune nitrogen use and watering, and reduce nitrate runoff and greenhouse gases, focusing on Nitrous Oxide (N$_2$O) emissions from soil. Facing climate change and limited agricultural knowledge, we use Partially Observable Markov Decision Processes (POMDPs) with a crop simulator to model AI agents' interactions with farming environments. We apply deep Q-learning with Recurrent Neural Network (RNN)-based Q networks for training agents on optimal actions. Also, we develop Machine Learning (ML) models to predict N$_2$O emissions, integrating these predictions into the simulator. Our research tackles uncertainties in N$_2$O emission estimates with a probabilistic ML approach and climate variability through a stochastic weather model, offering a range of emission outcomes to improve forecast reliability and decision-making. By incorporating climate change effects, we enhance agents' climate adaptability, aiming for resilient agricultural practices. Results show these agents can align crop productivity with environmental concerns by penalizing N$_2$O emissions, adapting effectively to climate shifts like warmer temperatures and less rain. This strategy improves farm management under climate change, highlighting AI's role in sustainable agriculture.
f-FERM: A Scalable Framework for Robust Fair Empirical Risk Minimization
Dec 06, 2023Training and deploying machine learning models that meet fairness criteria for protected groups are fundamental in modern artificial intelligence. While numerous constraints and regularization terms have been proposed in the literature to promote fairness in machine learning tasks, most of these methods are not amenable to stochastic optimization due to the complex and nonlinear structure of constraints and regularizers. Here, the term "stochastic" refers to the ability of the algorithm to work with small mini-batches of data. Motivated by the limitation of existing literature, this paper presents a unified stochastic optimization framework for fair empirical risk minimization based on f-divergence measures (f-FERM). The proposed stochastic algorithm enjoys theoretical convergence guarantees. In addition, our experiments demonstrate the superiority of fairness-accuracy tradeoffs offered by f-FERM for almost all batch sizes (ranging from full-batch to batch size of one). Moreover, we show that our framework can be extended to the case where there is a distribution shift from training to the test data. Our extension is based on a distributionally robust optimization reformulation of f-FERM objective under $L_p$ norms as uncertainty sets. Again, in this distributionally robust setting, f-FERM not only enjoys theoretical convergence guarantees but also outperforms other baselines in the literature in the tasks involving distribution shifts. An efficient stochastic implementation of $f$-FERM is publicly available.
Topic Modeling Based Extractive Text Summarization
Jun 29, 2021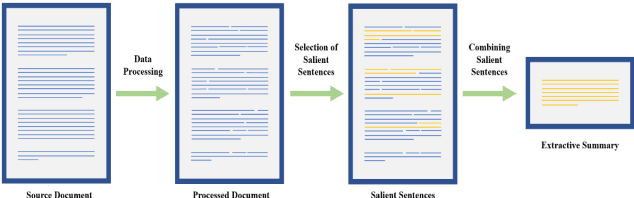
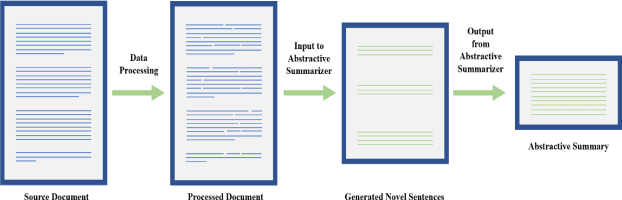
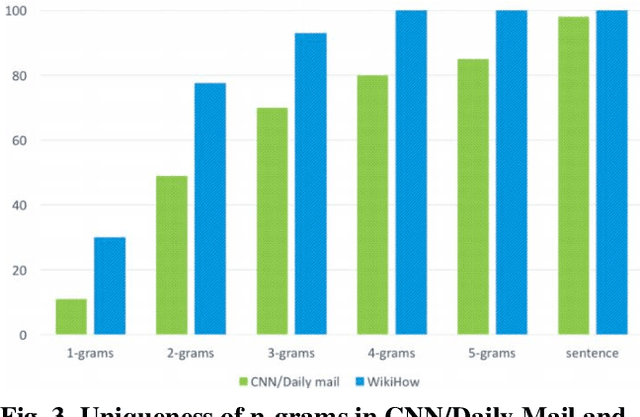
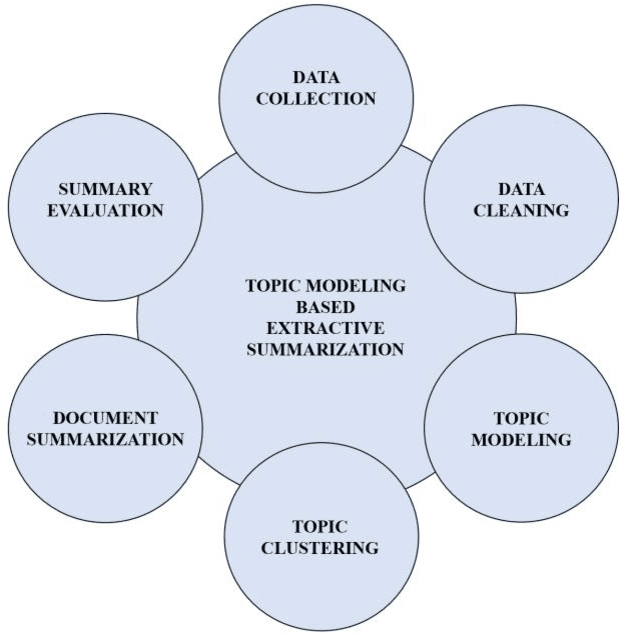
Text summarization is an approach for identifying important information present within text documents. This computational technique aims to generate shorter versions of the source text, by including only the relevant and salient information present within the source text. In this paper, we propose a novel method to summarize a text document by clustering its contents based on latent topics produced using topic modeling techniques and by generating extractive summaries for each of the identified text clusters. All extractive sub-summaries are later combined to generate a summary for any given source document. We utilize the lesser used and challenging WikiHow dataset in our approach to text summarization. This dataset is unlike the commonly used news datasets which are available for text summarization. The well-known news datasets present their most important information in the first few lines of their source texts, which make their summarization a lesser challenging task when compared to summarizing the WikiHow dataset. Contrary to these news datasets, the documents in the WikiHow dataset are written using a generalized approach and have lesser abstractedness and higher compression ratio, thus proposing a greater challenge to generate summaries. A lot of the current state-of-the-art text summarization techniques tend to eliminate important information present in source documents in the favor of brevity. Our proposed technique aims to capture all the varied information present in source documents. Although the dataset proved challenging, after performing extensive tests within our experimental setup, we have discovered that our model produces encouraging ROUGE results and summaries when compared to the other published extractive and abstractive text summarization models.
* 10 pages, 13 figures, 3 tables