 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopic Modeling Based Extractive Text Summarization
Jun 29, 2021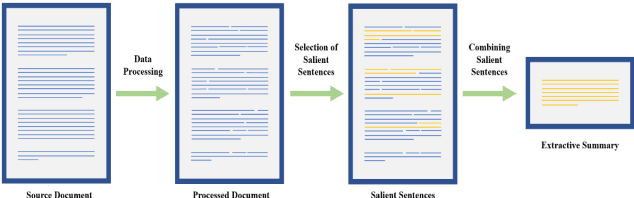
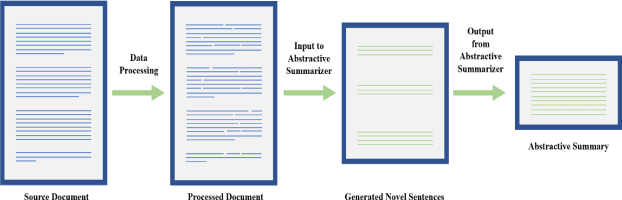
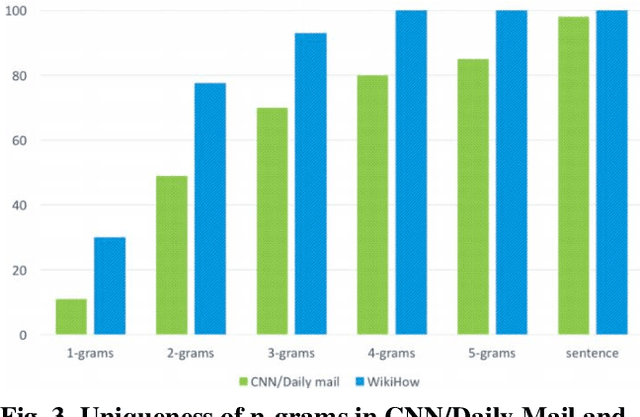
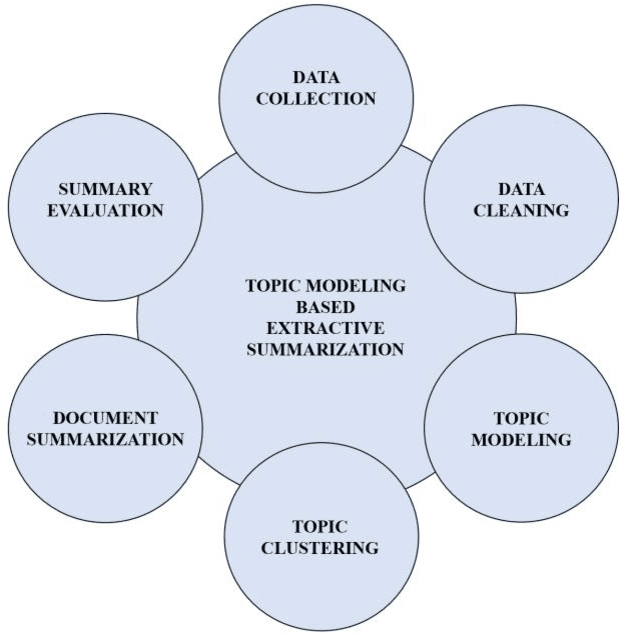
Text summarization is an approach for identifying important information present within text documents. This computational technique aims to generate shorter versions of the source text, by including only the relevant and salient information present within the source text. In this paper, we propose a novel method to summarize a text document by clustering its contents based on latent topics produced using topic modeling techniques and by generating extractive summaries for each of the identified text clusters. All extractive sub-summaries are later combined to generate a summary for any given source document. We utilize the lesser used and challenging WikiHow dataset in our approach to text summarization. This dataset is unlike the commonly used news datasets which are available for text summarization. The well-known news datasets present their most important information in the first few lines of their source texts, which make their summarization a lesser challenging task when compared to summarizing the WikiHow dataset. Contrary to these news datasets, the documents in the WikiHow dataset are written using a generalized approach and have lesser abstractedness and higher compression ratio, thus proposing a greater challenge to generate summaries. A lot of the current state-of-the-art text summarization techniques tend to eliminate important information present in source documents in the favor of brevity. Our proposed technique aims to capture all the varied information present in source documents. Although the dataset proved challenging, after performing extensive tests within our experimental setup, we have discovered that our model produces encouraging ROUGE results and summaries when compared to the other published extractive and abstractive text summarization models.
* 10 pages, 13 figures, 3 tables