Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical inference in massive datasets by empirical likelihood
Paper and Code
Apr 18, 2020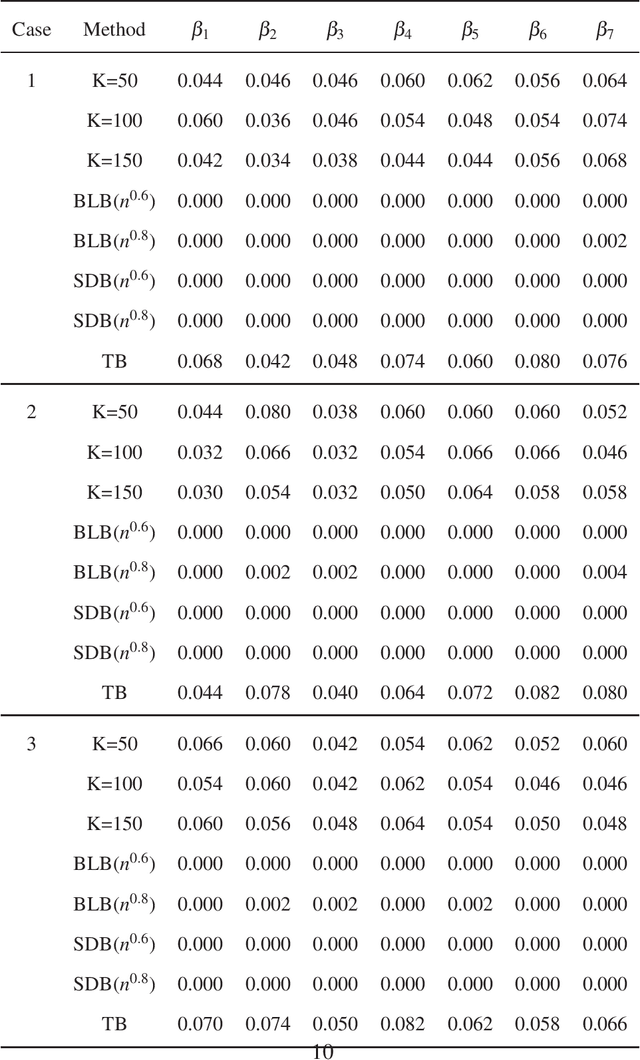
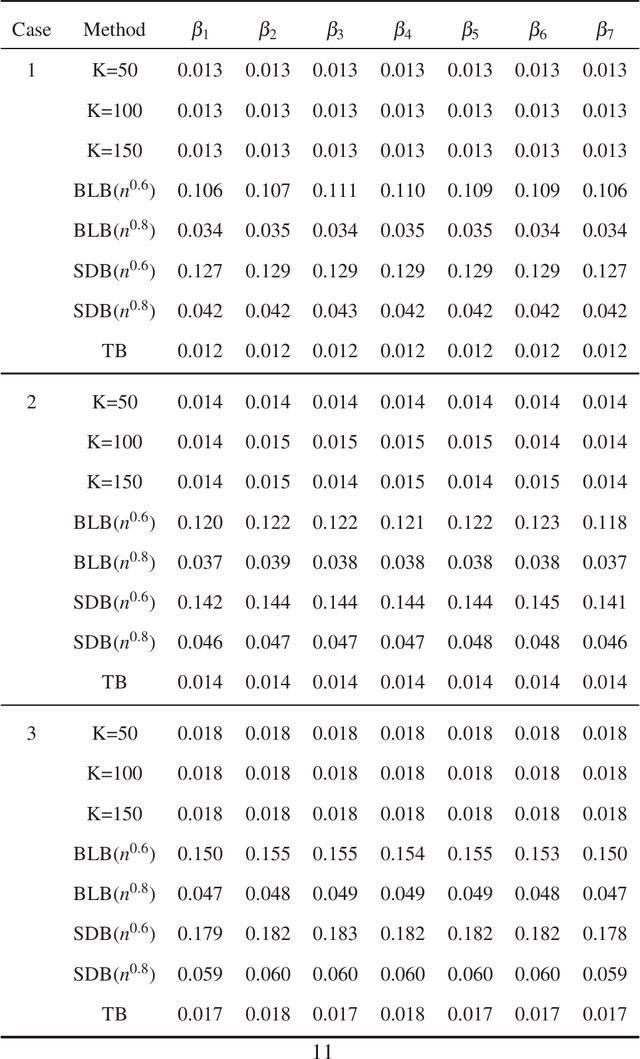
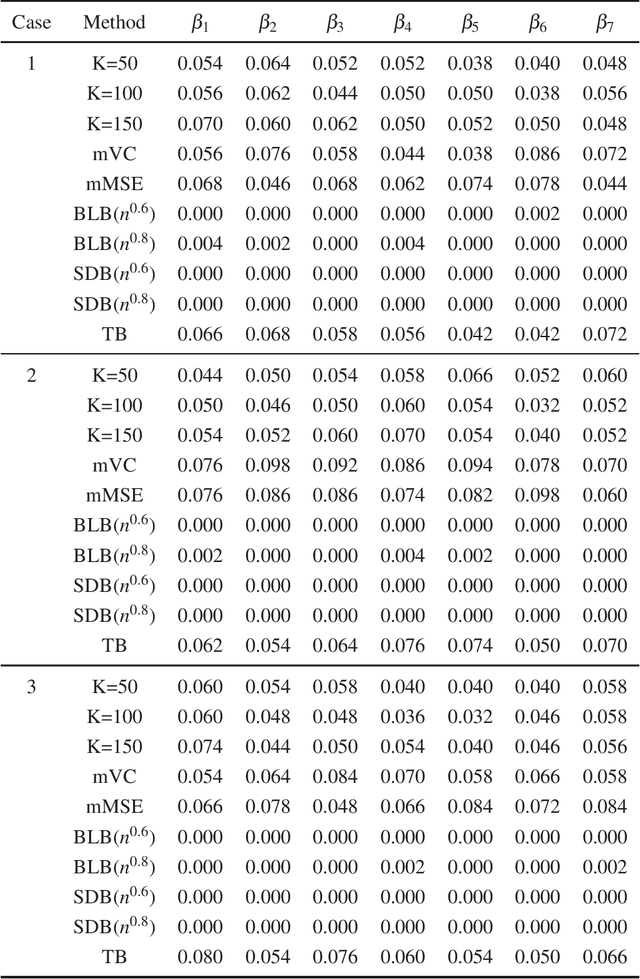
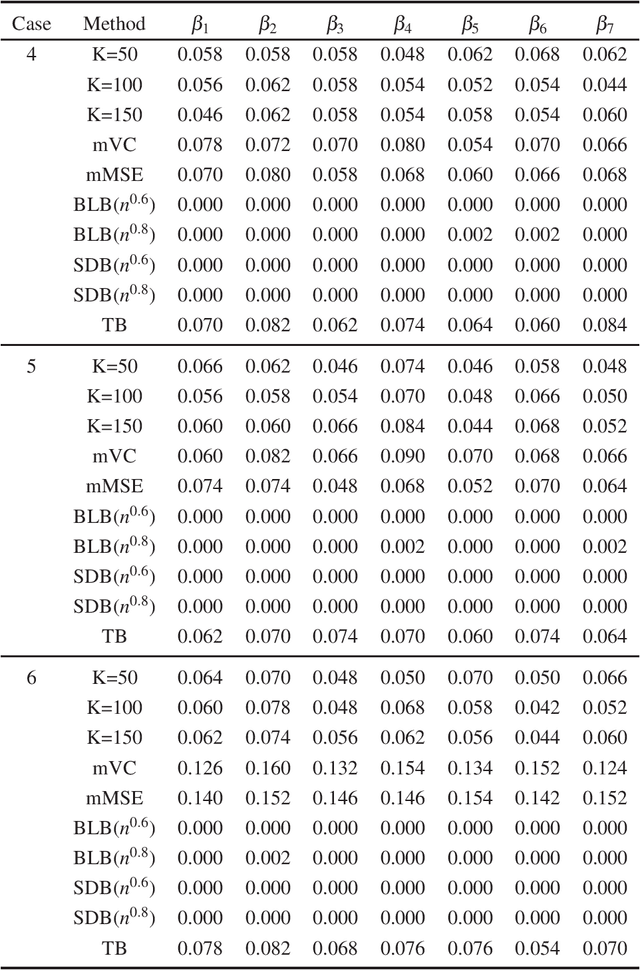
In this paper, we propose a new statistical inference method for massive data sets, which is very simple and efficient by combining divide-and-conquer method and empirical likelihood. Compared with two popular methods (the bag of little bootstrap and the subsampled double bootstrap), we make full use of data sets, and reduce the computation burden. Extensive numerical studies and real data analysis demonstrate the effectiveness and flexibility of our proposed method. Furthermore, the asymptotic property of our method is derived.
* 33 pages
View paper on