 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Based Soft Actor Critic for Environments with Non-stationary Dynamics
Paper and Code
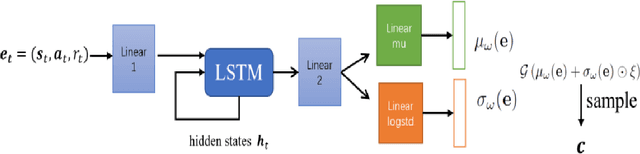
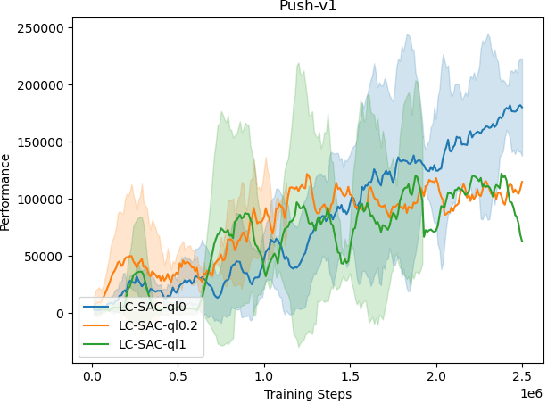
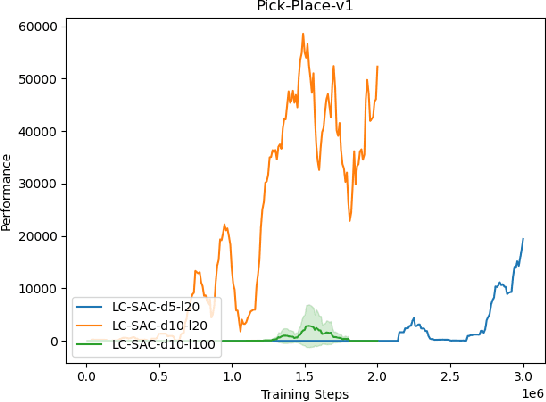
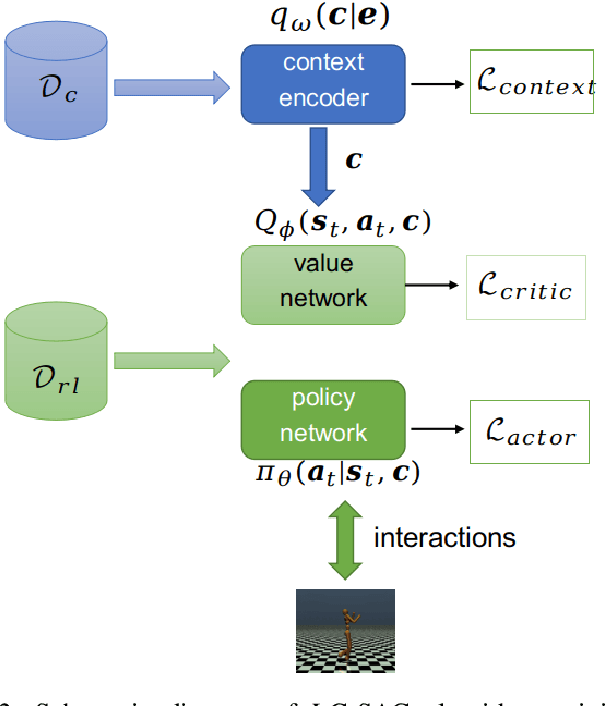
The performance of deep reinforcement learning methods prone to degenerate when applied to environments with non-stationary dynamics. In this paper, we utilize the latent context recurrent encoders motivated by recent Meta-RL materials, and propose the Latent Context-based Soft Actor Critic (LC-SAC) method to address aforementioned issues. By minimizing the contrastive prediction loss function, the learned context variables capture the information of the environment dynamics and the recent behavior of the agent. Then combined with the soft policy iteration paradigm, the LC-SAC method alternates between soft policy evaluation and soft policy improvement until it converges to the optimal policy. Experimental results show that the performance of LC-SAC is significantly better than the SAC algorithm on the MetaWorld ML1 tasks whose dynamics changes drasticly among different episodes, and is comparable to SAC on the continuous control benchmark task MuJoCo whose dynamics changes slowly or doesn't change between different episodes. In addition, we also conduct relevant experiments to determine the impact of different hyperparameter settings on the performance of the LC-SAC algorithm and give the reasonable suggestions of hyperparameter setting.