 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedRedFlag: Investigating how LLMs Redirect Misconceptions in Real-World Health Communication
Jan 14, 2026Real-world health questions from patients often unintentionally embed false assumptions or premises. In such cases, safe medical communication typically involves redirection: addressing the implicit misconception and then responding to the underlying patient context, rather than the original question. While large language models (LLMs) are increasingly being used by lay users for medical advice, they have not yet been tested for this crucial competency. Therefore, in this work, we investigate how LLMs react to false premises embedded within real-world health questions. We develop a semi-automated pipeline to curate MedRedFlag, a dataset of 1100+ questions sourced from Reddit that require redirection. We then systematically compare responses from state-of-the-art LLMs to those from clinicians. Our analysis reveals that LLMs often fail to redirect problematic questions, even when the problematic premise is detected, and provide answers that could lead to suboptimal medical decision making. Our benchmark and results reveal a novel and substantial gap in how LLMs perform under the conditions of real-world health communication, highlighting critical safety concerns for patient-facing medical AI systems. Code and dataset are available at https://github.com/srsambara-1/MedRedFlag.
Counting Clues: A Lightweight Probabilistic Baseline Can Match an LLM
Dec 14, 2025Large language models (LLMs) excel on multiple-choice clinical diagnosis benchmarks, yet it is unclear how much of this performance reflects underlying probabilistic reasoning. We study this through questions from MedQA, where the task is to select the most likely diagnosis. We introduce the Frequency-Based Probabilistic Ranker (FBPR), a lightweight method that scores options with a smoothed Naive Bayes over concept-diagnosis co-occurrence statistics from a large corpus. When co-occurrence statistics were sourced from the pretraining corpora for OLMo and Llama, FBPR achieves comparable performance to the corresponding LLMs pretrained on that same corpus. Direct LLM inference and FBPR largely get different questions correct, with an overlap only slightly above random chance, indicating complementary strengths of each method. These findings highlight the continued value of explicit probabilistic baselines: they provide a meaningful performance reference point and a complementary signal for potential hybridization. While the performance of LLMs seems to be driven by a mechanism other than simple frequency aggregation, we show that an approach similar to the historically grounded, low-complexity expert systems still accounts for a substantial portion of benchmark performance.
One Model for All Tasks: Leveraging Efficient World Models in Multi-Task Planning
Sep 09, 2025In heterogeneous multi-task learning, tasks not only exhibit diverse observation and action spaces but also vary substantially in intrinsic difficulty. While conventional multi-task world models like UniZero excel in single-task settings, we find that when handling large-scale heterogeneous environments, gradient conflicts and the loss of model plasticity often constrain their sample and computational efficiency. In this work, we address these challenges from two perspectives: the single learning iteration and the overall learning process. First, we investigate the impact of key design spaces on extending UniZero to multi-task planning. We find that a Mixture-of-Experts (MoE) architecture provides the most substantial performance gains by mitigating gradient conflicts, leading to our proposed model, \textit{ScaleZero}. Second, to dynamically balance the computational load across the learning process, we introduce an online, LoRA-based \textit{dynamic parameter scaling} (DPS) strategy. This strategy progressively integrates LoRA adapters in response to task-specific progress, enabling adaptive knowledge retention and parameter expansion. Empirical evaluations on standard benchmarks such as Atari, DMControl (DMC), and Jericho demonstrate that ScaleZero, relying exclusively on online reinforcement learning with one model, attains performance on par with specialized single-task baselines. Furthermore, when augmented with our dynamic parameter scaling strategy, our method achieves competitive performance while requiring only 80\% of the single-task environment interaction steps. These findings underscore the potential of ScaleZero for effective large-scale multi-task learning. Our code is available at \textcolor{magenta}{https://github.com/opendilab/LightZero}.
SafeWork-R1: Coevolving Safety and Intelligence under the AI-45$^{\circ}$ Law
Jul 24, 2025



We introduce SafeWork-R1, a cutting-edge multimodal reasoning model that demonstrates the coevolution of capabilities and safety. It is developed by our proposed SafeLadder framework, which incorporates large-scale, progressive, safety-oriented reinforcement learning post-training, supported by a suite of multi-principled verifiers. Unlike previous alignment methods such as RLHF that simply learn human preferences, SafeLadder enables SafeWork-R1 to develop intrinsic safety reasoning and self-reflection abilities, giving rise to safety `aha' moments. Notably, SafeWork-R1 achieves an average improvement of $46.54\%$ over its base model Qwen2.5-VL-72B on safety-related benchmarks without compromising general capabilities, and delivers state-of-the-art safety performance compared to leading proprietary models such as GPT-4.1 and Claude Opus 4. To further bolster its reliability, we implement two distinct inference-time intervention methods and a deliberative search mechanism, enforcing step-level verification. Finally, we further develop SafeWork-R1-InternVL3-78B, SafeWork-R1-DeepSeek-70B, and SafeWork-R1-Qwen2.5VL-7B. All resulting models demonstrate that safety and capability can co-evolve synergistically, highlighting the generalizability of our framework in building robust, reliable, and trustworthy general-purpose AI.
UniMoCo: Unified Modality Completion for Robust Multi-Modal Embeddings
May 17, 2025Current research has explored vision-language models for multi-modal embedding tasks, such as information retrieval, visual grounding, and classification. However, real-world scenarios often involve diverse modality combinations between queries and targets, such as text and image to text, text and image to text and image, and text to text and image. These diverse combinations pose significant challenges for existing models, as they struggle to align all modality combinations within a unified embedding space during training, which degrades performance at inference. To address this limitation, we propose UniMoCo, a novel vision-language model architecture designed for multi-modal embedding tasks. UniMoCo introduces a modality-completion module that generates visual features from textual inputs, ensuring modality completeness for both queries and targets. Additionally, we develop a specialized training strategy to align embeddings from both original and modality-completed inputs, ensuring consistency within the embedding space. This enables the model to robustly handle a wide range of modality combinations across embedding tasks. Experiments show that UniMoCo outperforms previous methods while demonstrating consistent robustness across diverse settings. More importantly, we identify and quantify the inherent bias in conventional approaches caused by imbalance of modality combinations in training data, which can be mitigated through our modality-completion paradigm. The code is available at https://github.com/HobbitQia/UniMoCo.
Circuit Representation Learning with Masked Gate Modeling and Verilog-AIG Alignment
Feb 18, 2025Understanding the structure and function of circuits is crucial for electronic design automation (EDA). Circuits can be formulated as And-Inverter graphs (AIGs), enabling efficient implementation of representation learning through graph neural networks (GNNs). Masked modeling paradigms have been proven effective in graph representation learning. However, masking augmentation to original circuits will destroy their logical equivalence, which is unsuitable for circuit representation learning. Moreover, existing masked modeling paradigms often prioritize structural information at the expense of abstract information such as circuit function. To address these limitations, we introduce MGVGA, a novel constrained masked modeling paradigm incorporating masked gate modeling (MGM) and Verilog-AIG alignment (VGA). Specifically, MGM preserves logical equivalence by masking gates in the latent space rather than in the original circuits, subsequently reconstructing the attributes of these masked gates. Meanwhile, large language models (LLMs) have demonstrated an excellent understanding of the Verilog code functionality. Building upon this capability, VGA performs masking operations on original circuits and reconstructs masked gates under the constraints of equivalent Verilog codes, enabling GNNs to learn circuit functions from LLMs. We evaluate MGVGA on various logic synthesis tasks for EDA and show the superior performance of MGVGA compared to previous state-of-the-art methods. Our code is available at https://github.com/wuhy68/MGVGA.
Trajectory Flow Matching with Applications to Clinical Time Series Modeling
Oct 28, 2024Modeling stochastic and irregularly sampled time series is a challenging problem found in a wide range of applications, especially in medicine. Neural stochastic differential equations (Neural SDEs) are an attractive modeling technique for this problem, which parameterize the drift and diffusion terms of an SDE with neural networks. However, current algorithms for training Neural SDEs require backpropagation through the SDE dynamics, greatly limiting their scalability and stability. To address this, we propose Trajectory Flow Matching (TFM), which trains a Neural SDE in a simulation-free manner, bypassing backpropagation through the dynamics. TFM leverages the flow matching technique from generative modeling to model time series. In this work we first establish necessary conditions for TFM to learn time series data. Next, we present a reparameterization trick which improves training stability. Finally, we adapt TFM to the clinical time series setting, demonstrating improved performance on three clinical time series datasets both in terms of absolute performance and uncertainty prediction.
Customized Retrieval Augmented Generation and Benchmarking for EDA Tool Documentation QA
Jul 26, 2024Retrieval augmented generation (RAG) enhances the accuracy and reliability of generative AI models by sourcing factual information from external databases, which is extensively employed in document-grounded question-answering (QA) tasks. Off-the-shelf RAG flows are well pretrained on general-purpose documents, yet they encounter significant challenges when being applied to knowledge-intensive vertical domains, such as electronic design automation (EDA). This paper addresses such issue by proposing a customized RAG framework along with three domain-specific techniques for EDA tool documentation QA, including a contrastive learning scheme for text embedding model fine-tuning, a reranker distilled from proprietary LLM, and a generative LLM fine-tuned with high-quality domain corpus. Furthermore, we have developed and released a documentation QA evaluation benchmark, ORD-QA, for OpenROAD, an advanced RTL-to-GDSII design platform. Experimental results demonstrate that our proposed RAG flow and techniques have achieved superior performance on ORD-QA as well as on a commercial tool, compared with state-of-the-arts. The ORD-QA benchmark and the training dataset for our customized RAG flow are open-source at https://github.com/lesliepy99/RAG-EDA.
UniZero: Generalized and Efficient Planning with Scalable Latent World Models
Jun 15, 2024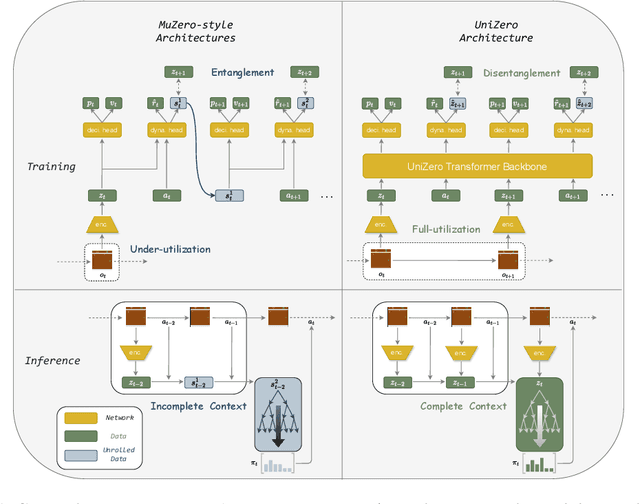
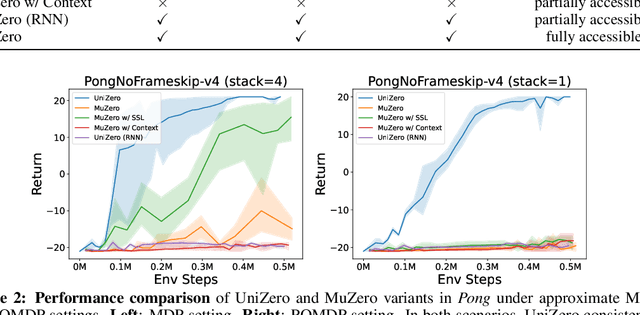

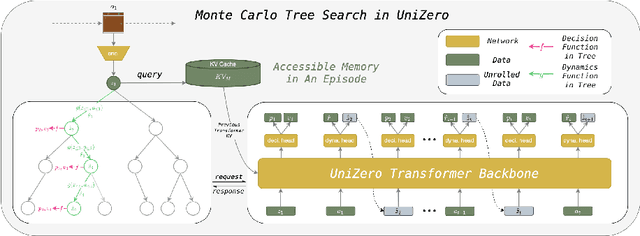
Learning predictive world models is essential for enhancing the planning capabilities of reinforcement learning agents. Notably, the MuZero-style algorithms, based on the value equivalence principle and Monte Carlo Tree Search (MCTS), have achieved superhuman performance in various domains. However, in environments that require capturing long-term dependencies, MuZero's performance deteriorates rapidly. We identify that this is partially due to the \textit{entanglement} of latent representations with historical information, which results in incompatibility with the auxiliary self-supervised state regularization. To overcome this limitation, we present \textit{UniZero}, a novel approach that \textit{disentangles} latent states from implicit latent history using a transformer-based latent world model. By concurrently predicting latent dynamics and decision-oriented quantities conditioned on the learned latent history, UniZero enables joint optimization of the long-horizon world model and policy, facilitating broader and more efficient planning in latent space. We demonstrate that UniZero, even with single-frame inputs, matches or surpasses the performance of MuZero-style algorithms on the Atari 100k benchmark. Furthermore, it significantly outperforms prior baselines in benchmarks that require long-term memory. Lastly, we validate the effectiveness and scalability of our design choices through extensive ablation studies, visual analyses, and multi-task learning results. The code is available at \textcolor{magenta}{https://github.com/opendilab/LightZero}.
ReZero: Boosting MCTS-based Algorithms by Just-in-Time and Speedy Reanalyze
Apr 28, 2024



MCTS-based algorithms, such as MuZero and its derivatives, have achieved widespread success in various decision-making domains. These algorithms employ the reanalyze process to enhance sample efficiency, albeit at the expense of significant wall-clock time consumption. To address this issue, we propose a general approach named ReZero to boost MCTS-based algorithms. Specifically, we propose a new scheme that simplifies data collecting and reanalyzing, which significantly reduces the search cost while guarantees the performance as well. Furthermore, to accelerate each search process, we conceive a method to reuse the subsequent information in the trajectory. The corresponding analysis conducted on the bandit model also provides auxiliary theoretical substantiation for our design. Experiments conducted on Atari environments and board games demonstrates that ReZero substantially improves training speed while maintaining high sample efficiency. The code is available as part of the LightZero benchmark at https://github.com/opendilab/LightZero.