 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELICIT: LLM Augmentation via External In-Context Capability
Paper and Code



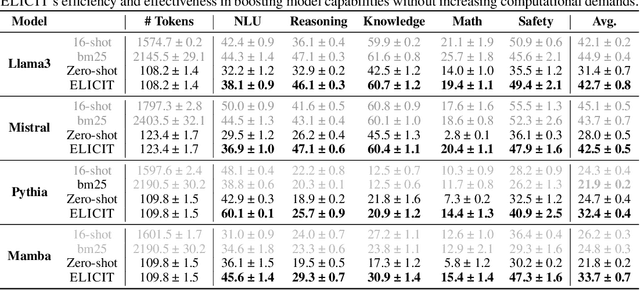
Enhancing the adaptive capabilities of large language models is a critical pursuit in both research and application. Traditional fine-tuning methods require substantial data and computational resources, especially for enhancing specific capabilities, while in-context learning is limited by the need for appropriate demonstrations and efficient token usage. Inspired by the expression of in-context learned capabilities through task vectors and the concept of modularization, we propose \alg, a framework consisting of two modules designed to effectively store and reuse task vectors to elicit the diverse capabilities of models without additional training or inference tokens. Our comprehensive experiments and analysis demonstrate that our pipeline is highly transferable across different input formats, tasks, and model architectures. ELICIT serves as a plug-and-play performance booster to enable adaptive elicitation of model capabilities. By externally storing and reusing vectors that represent in-context learned capabilities, \alg not only demonstrates the potential to operate modular capabilities but also significantly enhances the performance, versatility, adaptability, and scalability of large language models. Our code will be publicly available at https://github.com/LINs-lab/ELICIT.