 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Interest Transfer Network via Prototypical Contrastive Learning for Recommendation
Feb 28, 2023



Cross-domain recommendation has attracted increasing attention from industry and academia recently. However, most existing methods do not exploit the interest invariance between domains, which would yield sub-optimal solutions. In this paper, we propose a cross-domain recommendation method: Self-supervised Interest Transfer Network (SITN), which can effectively transfer invariant knowledge between domains via prototypical contrastive learning. Specifically, we perform two levels of cross-domain contrastive learning: 1) instance-to-instance contrastive learning, 2) instance-to-cluster contrastive learning. Not only that, we also take into account users' multi-granularity and multi-view interests. With this paradigm, SITN can explicitly learn the invariant knowledge of interest clusters between domains and accurately capture users' intents and preferences. We conducted extensive experiments on a public dataset and a large-scale industrial dataset collected from one of the world's leading e-commerce corporations. The experimental results indicate that SITN achieves significant improvements over state-of-the-art recommendation methods. Additionally, SITN has been deployed on a micro-video recommendation platform, and the online A/B testing results further demonstrate its practical value. Supplement is available at: https://github.com/fanqieCoffee/SITN-Supplement.
Textual Enhanced Contrastive Learning for Solving Math Word Problems
Nov 29, 2022



Solving math word problems is the task that analyses the relation of quantities and requires an accurate understanding of contextual natural language information. Recent studies show that current models rely on shallow heuristics to predict solutions and could be easily misled by small textual perturbations. To address this problem, we propose a Textual Enhanced Contrastive Learning framework, which enforces the models to distinguish semantically similar examples while holding different mathematical logic. We adopt a self-supervised manner strategy to enrich examples with subtle textual variance by textual reordering or problem re-construction. We then retrieve the hardest to differentiate samples from both equation and textual perspectives and guide the model to learn their representations. Experimental results show that our method achieves state-of-the-art on both widely used benchmark datasets and also exquisitely designed challenge datasets in English and Chinese. \footnote{Our code and data is available at \url{https://github.com/yiyunya/Textual_CL_MWP}
Seeking Diverse Reasoning Logic: Controlled Equation Expression Generation for Solving Math Word Problems
Sep 21, 2022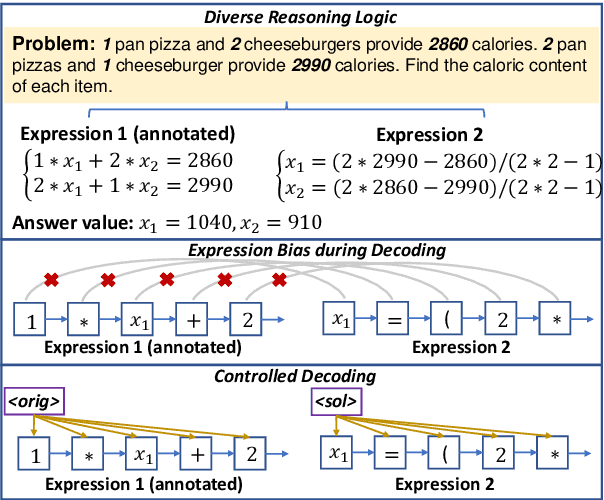
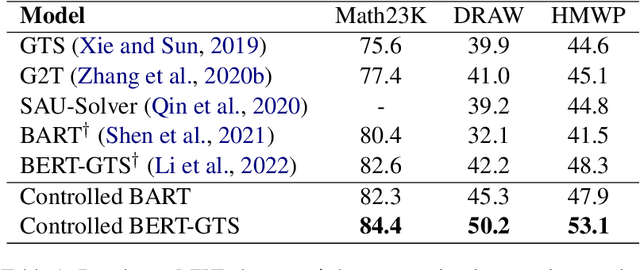
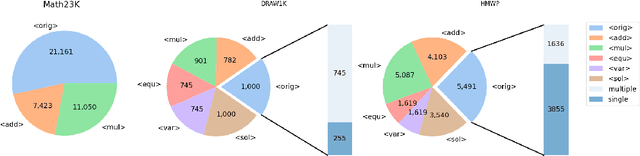
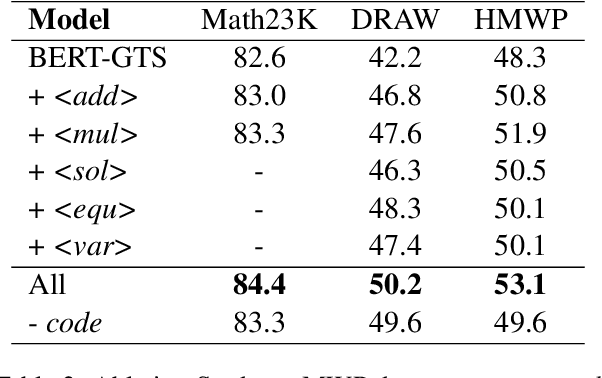
To solve Math Word Problems, human students leverage diverse reasoning logic that reaches different possible equation solutions. However, the mainstream sequence-to-sequence approach of automatic solvers aims to decode a fixed solution equation supervised by human annotation. In this paper, we propose a controlled equation generation solver by leveraging a set of control codes to guide the model to consider certain reasoning logic and decode the corresponding equations expressions transformed from the human reference. The empirical results suggest that our method universally improves the performance on single-unknown (Math23K) and multiple-unknown (DRAW1K, HMWP) benchmarks, with substantial improvements up to 13.2% accuracy on the challenging multiple-unknown datasets.
SAME: Scenario Adaptive Mixture-of-Experts for Promotion-Aware Click-Through Rate Prediction
Dec 27, 2021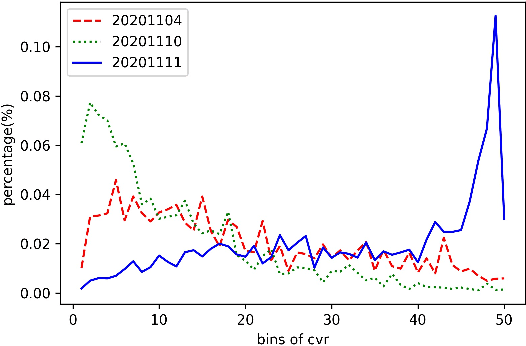
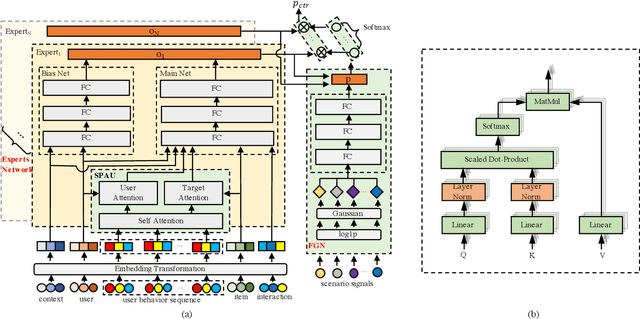
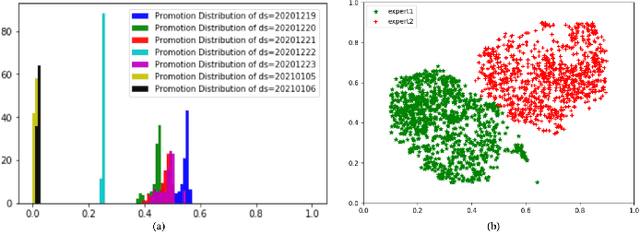
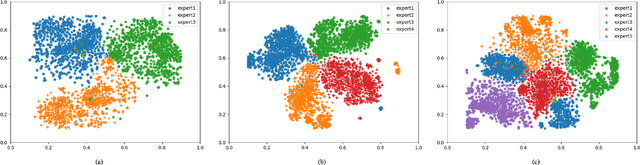
Promotions are becoming more important and prevalent in e-commerce platforms to attract customers and boost sales. However, Click-Through Rate (CTR) prediction methods in recommender systems are not able to handle such circumstances well since: 1) they can't generalize well to serving because the online data distribution is uncertain due to the potentially upcoming promotions; 2) without paying enough attention to scenario signals, they are incapable of learning different feature representation patterns which coexist in each scenario. In this work, we propose Scenario Adaptive Mixture-of-Experts (SAME), a simple yet effective model that serves both promotion and normal scenarios. Technically, it follows the idea of Mixture-of-Experts by adopting multiple experts to learn feature representations, which are modulated by a Feature Gated Network (FGN) via an attention mechanism. To obtain high-quality representations, we design a Stacked Parallel Attention Unit (SPAU) to help each expert better handle user behavior sequence. To tackle the distribution uncertainty, a set of scenario signals are elaborately devised from a perspective of time series prediction and fed into the FGN, whose output is concatenated with feature representation from each expert to learn the attention. Accordingly, a mixture of the feature representations is obtained scenario-adaptively and used for the final CTR prediction. In this way, each expert can learn a discriminative representation pattern. To the best of our knowledge, this is the first study for promotion-aware CTR prediction. Experimental results on real-world datasets validate the superiority of SAME. Online A/B test also shows SAME achieves significant gains of 3.58% on CTR and 5.94% on IPV during promotion periods as well as 3.93% and 6.57% in normal days, respectively.