 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFacet-Level Persona Control by Trait-Activated Routing with Contrastive SAE for Role-Playing LLMs
Feb 22, 2026Personality control in Role-Playing Agents (RPAs) is commonly achieved via training-free methods that inject persona descriptions and memory through prompts or retrieval-augmented generation, or via supervised fine-tuning (SFT) on persona-specific corpora. While SFT can be effective, it requires persona-labeled data and retraining for new roles, limiting flexibility. In contrast, prompt- and RAG-based signals are easy to apply but can be diluted in long dialogues, leading to drifting and sometimes inconsistent persona behavior. To address this, we propose a contrastive Sparse AutoEncoder (SAE) framework that learns facet-level personality control vectors aligned with the Big Five 30-facet model. A new 15,000-sample leakage-controlled corpus is constructed to provide balanced supervision for each facet. The learned vectors are integrated into the model's residual space and dynamically selected by a trait-activated routing module, enabling precise and interpretable personality steering. Experiments on Large Language Models (LLMs) show that the proposed method maintains stable character fidelity and output quality across contextualized settings, outperforming Contrastive Activation Addition (CAA) and prompt-only baselines. The combined SAE+Prompt configuration achieves the best overall performance, confirming that contrastively trained latent vectors can enhance persona control while preserving dialogue coherence.
Speech-Hands: A Self-Reflection Voice Agentic Approach to Speech Recognition and Audio Reasoning with Omni Perception
Jan 14, 2026We introduce a voice-agentic framework that learns one critical omni-understanding skill: knowing when to trust itself versus when to consult external audio perception. Our work is motivated by a crucial yet counterintuitive finding: naively fine-tuning an omni-model on both speech recognition and external sound understanding tasks often degrades performance, as the model can be easily misled by noisy hypotheses. To address this, our framework, Speech-Hands, recasts the problem as an explicit self-reflection decision. This learnable reflection primitive proves effective in preventing the model from being derailed by flawed external candidates. We show that this agentic action mechanism generalizes naturally from speech recognition to complex, multiple-choice audio reasoning. Across the OpenASR leaderboard, Speech-Hands consistently outperforms strong baselines by 12.1% WER on seven benchmarks. The model also achieves 77.37% accuracy and high F1 on audio QA decisions, showing robust generalization and reliability across diverse audio question answering datasets. By unifying perception and decision-making, our work offers a practical path toward more reliable and resilient audio intelligence.
Causal Tree Extraction from Medical Case Reports: A Novel Task for Experts-like Text Comprehension
Mar 03, 2025Extracting causal relationships from a medical case report is essential for comprehending the case, particularly its diagnostic process. Since the diagnostic process is regarded as a bottom-up inference, causal relationships in cases naturally form a multi-layered tree structure. The existing tasks, such as medical relation extraction, are insufficient for capturing the causal relationships of an entire case, as they treat all relations equally without considering the hierarchical structure inherent in the diagnostic process. Thus, we propose a novel task, Causal Tree Extraction (CTE), which receives a case report and generates a causal tree with the primary disease as the root, providing an intuitive understanding of a case's diagnostic process. Subsequently, we construct a Japanese case report CTE dataset, J-Casemap, propose a generation-based CTE method that outperforms the baseline by 20.2 points in the human evaluation, and introduce evaluation metrics that reflect clinician preferences. Further experiments also show that J-Casemap enhances the performance of solving other medical tasks, such as question answering.
Neuro-Symbolic Contrastive Learning for Cross-domain Inference
Feb 13, 2025Pre-trained language models (PLMs) have made significant advances in natural language inference (NLI) tasks, however their sensitivity to textual perturbations and dependence on large datasets indicate an over-reliance on shallow heuristics. In contrast, inductive logic programming (ILP) excels at inferring logical relationships across diverse, sparse and limited datasets, but its discrete nature requires the inputs to be precisely specified, which limits their application. This paper proposes a bridge between the two approaches: neuro-symbolic contrastive learning. This allows for smooth and differentiable optimisation that improves logical accuracy across an otherwise discrete, noisy, and sparse topological space of logical functions. We show that abstract logical relationships can be effectively embedded within a neuro-symbolic paradigm, by representing data as logic programs and sets of logic rules. The embedding space captures highly varied textual information with similar semantic logical relations, but can also separate similar textual relations that have dissimilar logical relations. Experimental results demonstrate that our approach significantly improves the inference capabilities of the models in terms of generalisation and reasoning.
* In Proceedings ICLP 2024, arXiv:2502.08453
UniPaint: Unified Space-time Video Inpainting via Mixture-of-Experts
Dec 09, 2024



In this paper, we present UniPaint, a unified generative space-time video inpainting framework that enables spatial-temporal inpainting and interpolation. Different from existing methods that treat video inpainting and video interpolation as two distinct tasks, we leverage a unified inpainting framework to tackle them and observe that these two tasks can mutually enhance synthesis performance. Specifically, we first introduce a plug-and-play space-time video inpainting adapter, which can be employed in various personalized models. The key insight is to propose a Mixture of Experts (MoE) attention to cover various tasks. Then, we design a spatial-temporal masking strategy during the training stage to mutually enhance each other and improve performance. UniPaint produces high-quality and aesthetically pleasing results, achieving the best quantitative results across various tasks and scale setups. The code and checkpoints will be available soon.
Beyond English-Centric LLMs: What Language Do Multilingual Language Models Think in?
Aug 20, 2024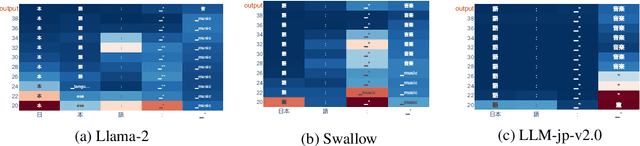

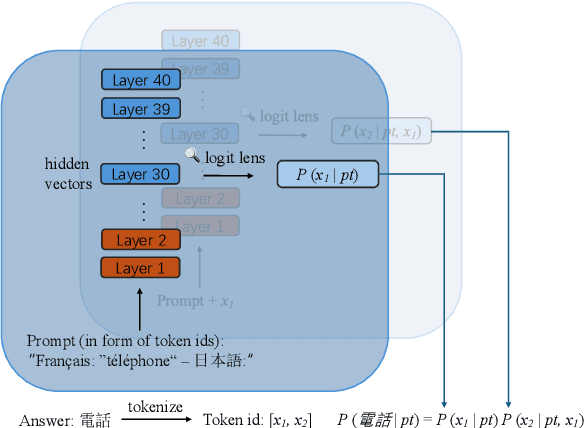
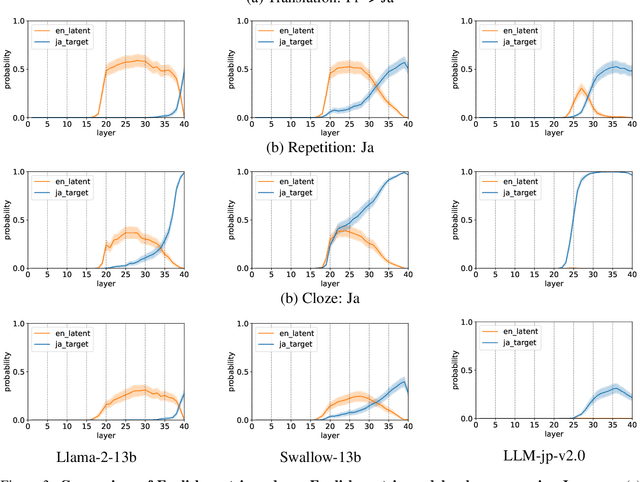
In this study, we investigate whether non-English-centric LLMs, despite their strong performance, `think' in their respective dominant language: more precisely, `think' refers to how the representations of intermediate layers, when un-embedded into the vocabulary space, exhibit higher probabilities for certain dominant languages during generation. We term such languages as internal $\textbf{latent languages}$. We examine the latent language of three typical categories of models for Japanese processing: Llama2, an English-centric model; Swallow, an English-centric model with continued pre-training in Japanese; and LLM-jp, a model pre-trained on balanced English and Japanese corpora. Our empirical findings reveal that, unlike Llama2 which relies exclusively on English as the internal latent language, Japanese-specific Swallow and LLM-jp employ both Japanese and English, exhibiting dual internal latent languages. For any given target language, the model preferentially activates the latent language most closely related to it. In addition, we explore how intermediate layers respond to questions involving cultural conflicts between latent internal and target output languages. We further explore how the language identity shifts across layers while keeping consistent semantic meaning reflected in the intermediate layer representations. This study deepens the understanding of non-English-centric large language models, highlighting the intricate dynamics of language representation within their intermediate layers.
LLM-jp: A Cross-organizational Project for the Research and Development of Fully Open Japanese LLMs
Jul 04, 2024



This paper introduces LLM-jp, a cross-organizational project for the research and development of Japanese large language models (LLMs). LLM-jp aims to develop open-source and strong Japanese LLMs, and as of this writing, more than 1,500 participants from academia and industry are working together for this purpose. This paper presents the background of the establishment of LLM-jp, summaries of its activities, and technical reports on the LLMs developed by LLM-jp. For the latest activities, visit https://llm-jp.nii.ac.jp/en/.
Evaluating Saliency Explanations in NLP by Crowdsourcing
May 17, 2024
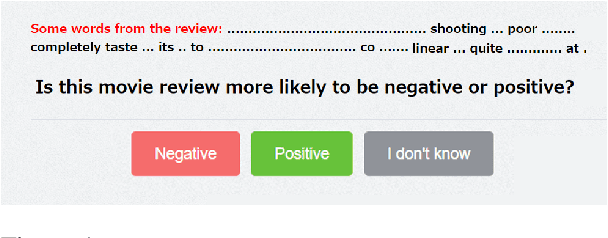


Deep learning models have performed well on many NLP tasks. However, their internal mechanisms are typically difficult for humans to understand. The development of methods to explain models has become a key issue in the reliability of deep learning models in many important applications. Various saliency explanation methods, which give each feature of input a score proportional to the contribution of output, have been proposed to determine the part of the input which a model values most. Despite a considerable body of work on the evaluation of saliency methods, whether the results of various evaluation metrics agree with human cognition remains an open question. In this study, we propose a new human-based method to evaluate saliency methods in NLP by crowdsourcing. We recruited 800 crowd workers and empirically evaluated seven saliency methods on two datasets with the proposed method. We analyzed the performance of saliency methods, compared our results with existing automated evaluation methods, and identified notable differences between NLP and computer vision (CV) fields when using saliency methods. The instance-level data of our crowdsourced experiments and the code to reproduce the explanations are available at https://github.com/xtlu/lreccoling_evaluation.
Rapidly Developing High-quality Instruction Data and Evaluation Benchmark for Large Language Models with Minimal Human Effort: A Case Study on Japanese
Mar 06, 2024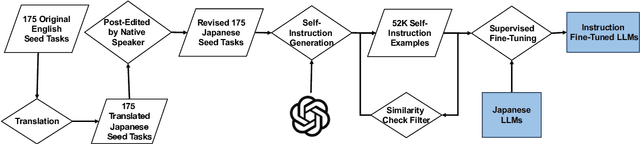
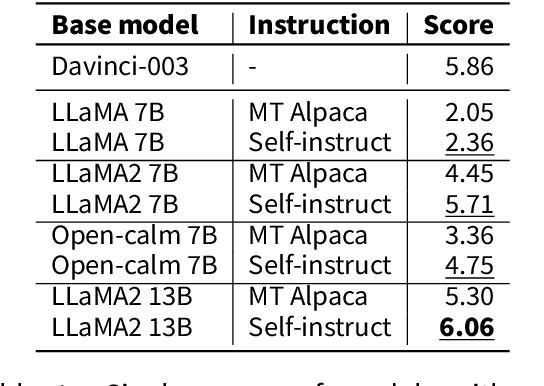
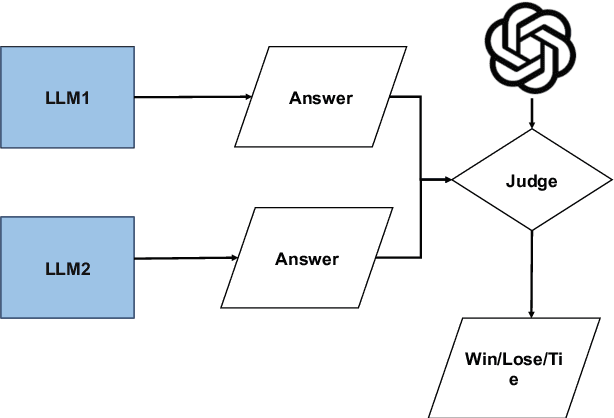

The creation of instruction data and evaluation benchmarks for serving Large language models often involves enormous human annotation. This issue becomes particularly pronounced when rapidly developing such resources for a non-English language like Japanese. Instead of following the popular practice of directly translating existing English resources into Japanese (e.g., Japanese-Alpaca), we propose an efficient self-instruct method based on GPT-4. We first translate a small amount of English instructions into Japanese and post-edit them to obtain native-level quality. GPT-4 then utilizes them as demonstrations to automatically generate Japanese instruction data. We also construct an evaluation benchmark containing 80 questions across 8 categories, using GPT-4 to automatically assess the response quality of LLMs without human references. The empirical results suggest that the models fine-tuned on our GPT-4 self-instruct data significantly outperformed the Japanese-Alpaca across all three base pre-trained models. Our GPT-4 self-instruct data allowed the LLaMA 13B model to defeat GPT-3.5 (Davinci-003) with a 54.37\% win-rate. The human evaluation exhibits the consistency between GPT-4's assessments and human preference. Our high-quality instruction data and evaluation benchmark have been released here.
Pushing the Limits of ChatGPT on NLP Tasks
Jun 16, 2023



Despite the success of ChatGPT, its performances on most NLP tasks are still well below the supervised baselines. In this work, we looked into the causes, and discovered that its subpar performance was caused by the following factors: (1) token limit in the prompt does not allow for the full utilization of the supervised datasets; (2) mismatch between the generation nature of ChatGPT and NLP tasks; (3) intrinsic pitfalls of LLMs models, e.g., hallucination, overly focus on certain keywords, etc. In this work, we propose a collection of general modules to address these issues, in an attempt to push the limits of ChatGPT on NLP tasks. Our proposed modules include (1) a one-input-multiple-prompts strategy that employs multiple prompts for one input to accommodate more demonstrations; (2) using fine-tuned models for better demonstration retrieval; (3) transforming tasks to formats that are more tailored to the generation nature; (4) employing reasoning strategies that are tailored to addressing the task-specific complexity; (5) the self-verification strategy to address the hallucination issue of LLMs; (6) the paraphrase strategy to improve the robustness of model predictions. We conduct experiments on 21 datasets of 10 representative NLP tasks, including question answering, commonsense reasoning, natural language inference, sentiment analysis, named entity recognition, entity-relation extraction, event extraction, dependency parsing, semantic role labeling, and part-of-speech tagging. Using the proposed assemble of techniques, we are able to significantly boost the performance of ChatGPT on the selected NLP tasks, achieving performances comparable to or better than supervised baselines, or even existing SOTA performances.