 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCAN: Semantic Document Layout Analysis for Textual and Visual Retrieval-Augmented Generation
May 20, 2025With the increasing adoption of Large Language Models (LLMs) and Vision-Language Models (VLMs), rich document analysis technologies for applications like Retrieval-Augmented Generation (RAG) and visual RAG are gaining significant attention. Recent research indicates that using VLMs can achieve better RAG performance, but processing rich documents still remains a challenge since a single page contains large amounts of information. In this paper, we present SCAN (\textbf{S}emanti\textbf{C} Document Layout \textbf{AN}alysis), a novel approach enhancing both textual and visual Retrieval-Augmented Generation (RAG) systems working with visually rich documents. It is a VLM-friendly approach that identifies document components with appropriate semantic granularity, balancing context preservation with processing efficiency. SCAN uses a coarse-grained semantic approach that divides documents into coherent regions covering continuous components. We trained the SCAN model by fine-tuning object detection models with sophisticated annotation datasets. Our experimental results across English and Japanese datasets demonstrate that applying SCAN improves end-to-end textual RAG performance by up to 9.0\% and visual RAG performance by up to 6.4\%, outperforming conventional approaches and even commercial document processing solutions.
Disambiguating Reference in Visually Grounded Dialogues through Joint Modeling of Textual and Multimodal Semantic Structures
May 16, 2025Multimodal reference resolution, including phrase grounding, aims to understand the semantic relations between mentions and real-world objects. Phrase grounding between images and their captions is a well-established task. In contrast, for real-world applications, it is essential to integrate textual and multimodal reference resolution to unravel the reference relations within dialogue, especially in handling ambiguities caused by pronouns and ellipses. This paper presents a framework that unifies textual and multimodal reference resolution by mapping mention embeddings to object embeddings and selecting mentions or objects based on their similarity. Our experiments show that learning textual reference resolution, such as coreference resolution and predicate-argument structure analysis, positively affects performance in multimodal reference resolution. In particular, our model with coreference resolution performs better in pronoun phrase grounding than representative models for this task, MDETR and GLIP. Our qualitative analysis demonstrates that incorporating textual reference relations strengthens the confidence scores between mentions, including pronouns and predicates, and objects, which can reduce the ambiguities that arise in visually grounded dialogues.
LLM-jp: A Cross-organizational Project for the Research and Development of Fully Open Japanese LLMs
Jul 04, 2024



This paper introduces LLM-jp, a cross-organizational project for the research and development of Japanese large language models (LLMs). LLM-jp aims to develop open-source and strong Japanese LLMs, and as of this writing, more than 1,500 participants from academia and industry are working together for this purpose. This paper presents the background of the establishment of LLM-jp, summaries of its activities, and technical reports on the LLMs developed by LLM-jp. For the latest activities, visit https://llm-jp.nii.ac.jp/en/.
J-CRe3: A Japanese Conversation Dataset for Real-world Reference Resolution
Mar 28, 2024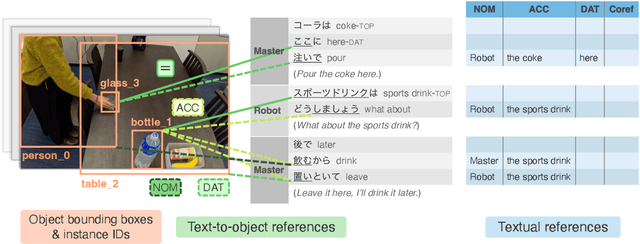
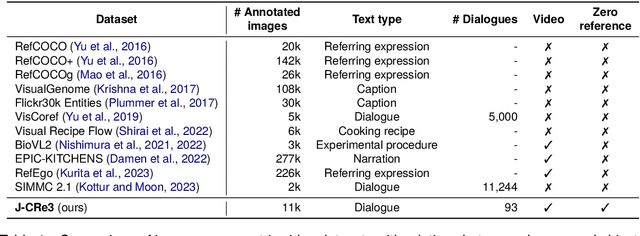

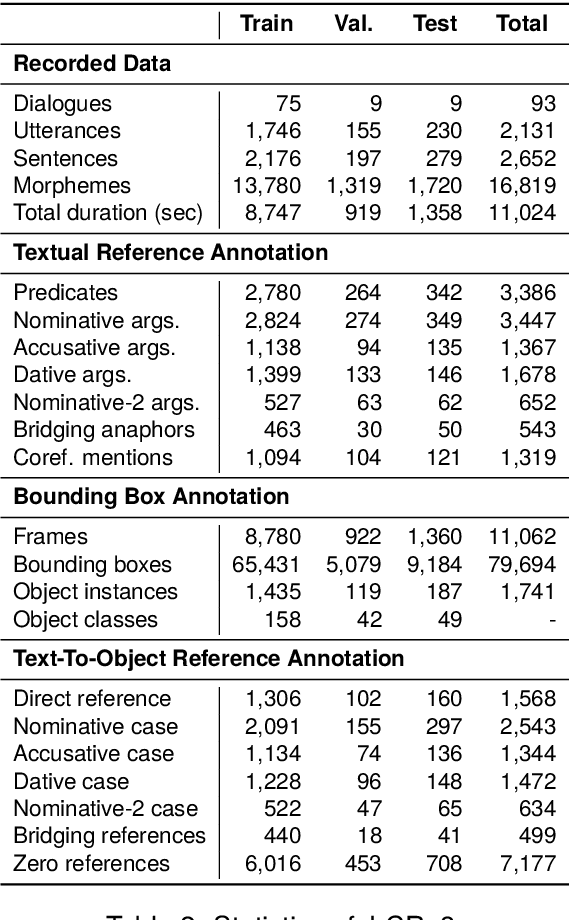
Understanding expressions that refer to the physical world is crucial for such human-assisting systems in the real world, as robots that must perform actions that are expected by users. In real-world reference resolution, a system must ground the verbal information that appears in user interactions to the visual information observed in egocentric views. To this end, we propose a multimodal reference resolution task and construct a Japanese Conversation dataset for Real-world Reference Resolution (J-CRe3). Our dataset contains egocentric video and dialogue audio of real-world conversations between two people acting as a master and an assistant robot at home. The dataset is annotated with crossmodal tags between phrases in the utterances and the object bounding boxes in the video frames. These tags include indirect reference relations, such as predicate-argument structures and bridging references as well as direct reference relations. We also constructed an experimental model and clarified the challenges in multimodal reference resolution tasks.
Rapidly Developing High-quality Instruction Data and Evaluation Benchmark for Large Language Models with Minimal Human Effort: A Case Study on Japanese
Mar 06, 2024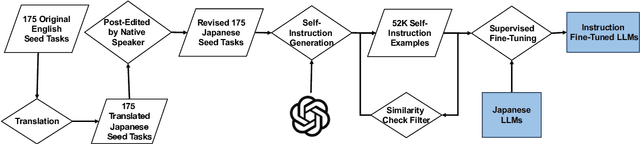
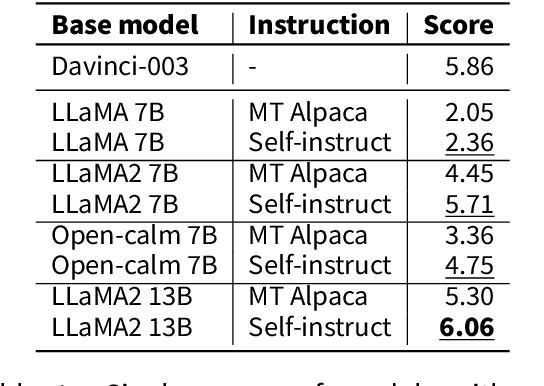
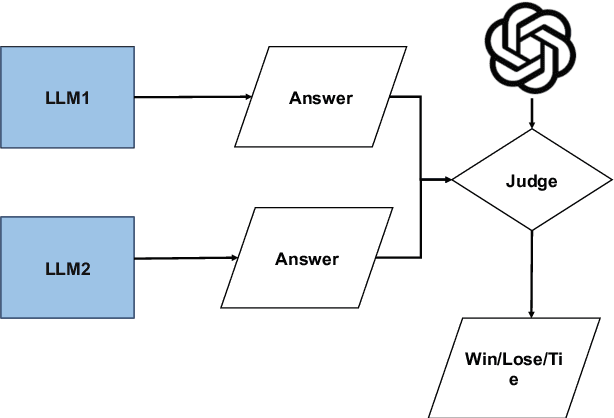

The creation of instruction data and evaluation benchmarks for serving Large language models often involves enormous human annotation. This issue becomes particularly pronounced when rapidly developing such resources for a non-English language like Japanese. Instead of following the popular practice of directly translating existing English resources into Japanese (e.g., Japanese-Alpaca), we propose an efficient self-instruct method based on GPT-4. We first translate a small amount of English instructions into Japanese and post-edit them to obtain native-level quality. GPT-4 then utilizes them as demonstrations to automatically generate Japanese instruction data. We also construct an evaluation benchmark containing 80 questions across 8 categories, using GPT-4 to automatically assess the response quality of LLMs without human references. The empirical results suggest that the models fine-tuned on our GPT-4 self-instruct data significantly outperformed the Japanese-Alpaca across all three base pre-trained models. Our GPT-4 self-instruct data allowed the LLaMA 13B model to defeat GPT-3.5 (Davinci-003) with a 54.37\% win-rate. The human evaluation exhibits the consistency between GPT-4's assessments and human preference. Our high-quality instruction data and evaluation benchmark have been released here.
A System for Worldwide COVID-19 Information Aggregation
Jul 28, 2020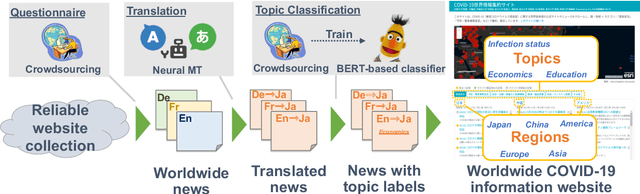

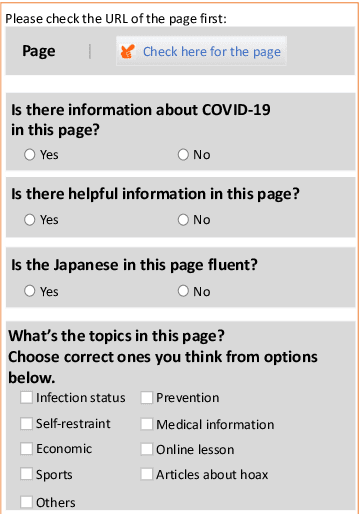
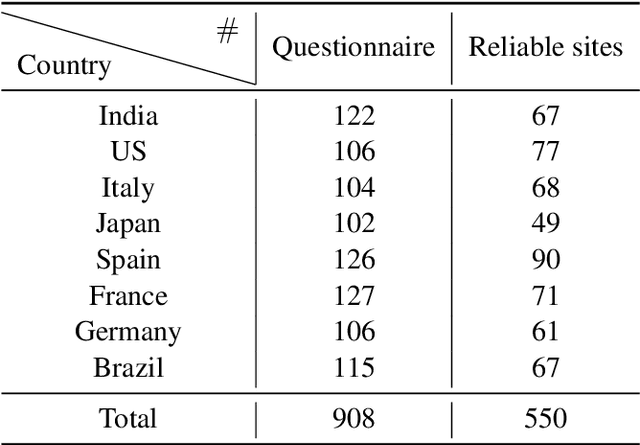
The global pandemic of COVID-19 has made the public pay close attention to related news, covering various domains, such as sanitation, treatment, and effects on education. Meanwhile, the COVID-19 condition is very different among the countries (e.g., policies and development of the epidemic), and thus citizens would be interested in news in foreign countries. We build a system for worldwide COVID-19 information aggregation (http://lotus.kuee.kyoto-u.ac.jp/NLPforCOVID-19 ) containing reliable articles from 10 regions in 7 languages sorted by topics for Japanese citizens. Our reliable COVID-19 related website dataset collected through crowdsourcing ensures the quality of the articles. A neural machine translation module translates articles in other languages into Japanese. A BERT-based topic-classifier trained on an article-topic pair dataset helps users find their interested information efficiently by putting articles into different categories.
Three-dimensional Generative Adversarial Nets for Unsupervised Metal Artifact Reduction
Nov 19, 2019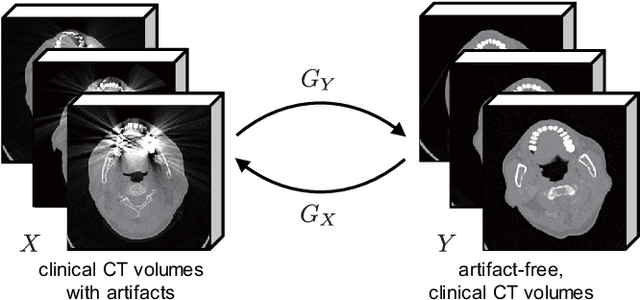
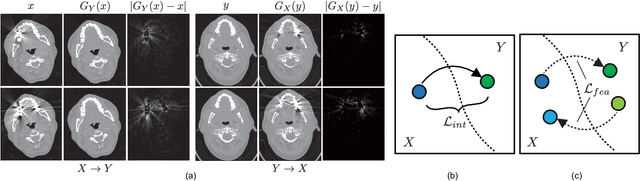
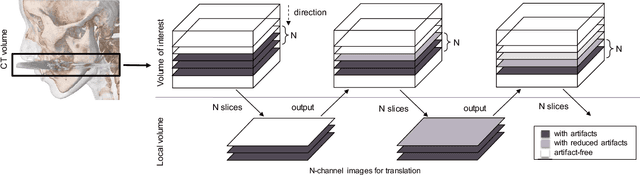
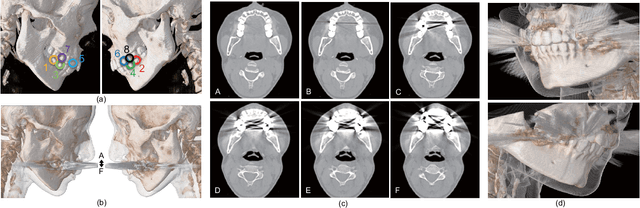
The reduction of metal artifacts in computed tomography (CT) images, specifically for strong artifacts generated from multiple metal objects, is a challenging issue in medical imaging research. Although there have been some studies on supervised metal artifact reduction through the learning of synthesized artifacts, it is difficult for simulated artifacts to cover the complexity of the real physical phenomena that may be observed in X-ray propagation. In this paper, we introduce metal artifact reduction methods based on an unsupervised volume-to-volume translation learned from clinical CT images. We construct three-dimensional adversarial nets with a regularized loss function designed for metal artifacts from multiple dental fillings. The results of experiments using 915 CT volumes from real patients demonstrate that the proposed framework has an outstanding capacity to reduce strong artifacts and to recover underlying missing voxels, while preserving the anatomical features of soft tissues and tooth structures from the original images.