 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobotic Stroke Motion Following the Shape of the Human Back: Motion Generation and Psychological Effects
May 10, 2024In this study, to perform the robotic stroke motions following the shape of the human back similar to the stroke motions by humans, in contrast to the conventional robotic stroke motion with a linear trajectory, we propose a trajectory generation method for a robotic stroke motion following the shape of the human back. We confirmed that the accuracy of the method's trajectory was close to that of the actual stroking motion by a human. Furthermore, we conducted a subjective experiment to evaluate the psychological effects of the proposed stroke motion in contrast to those of the conventional stroke motion with a linear trajectory. The experimental results showed that the actual stroke motion following the shape of the human back tended to evoke more pleasant and active feelings than the conventional stroke motion.
J-CRe3: A Japanese Conversation Dataset for Real-world Reference Resolution
Mar 28, 2024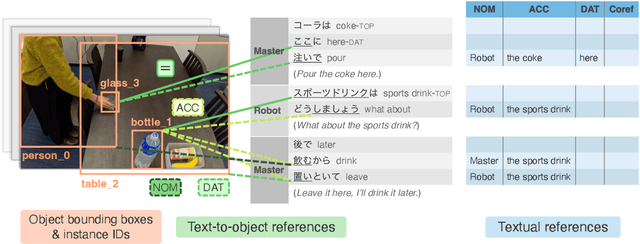
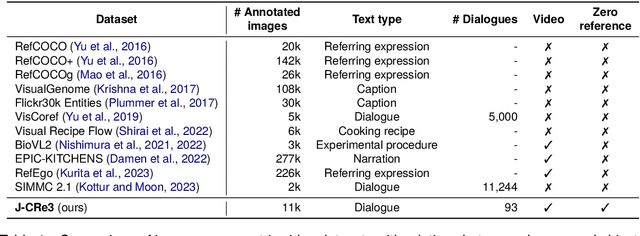

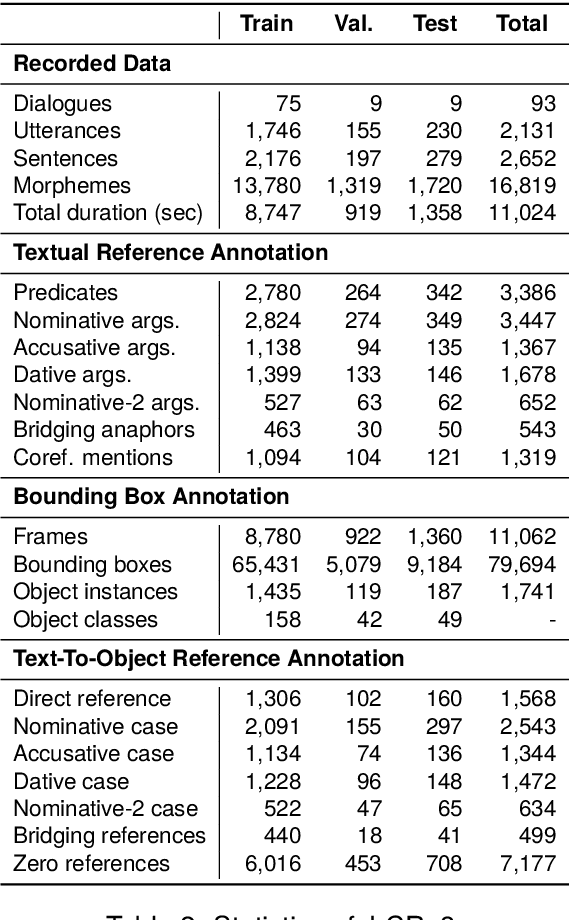
Understanding expressions that refer to the physical world is crucial for such human-assisting systems in the real world, as robots that must perform actions that are expected by users. In real-world reference resolution, a system must ground the verbal information that appears in user interactions to the visual information observed in egocentric views. To this end, we propose a multimodal reference resolution task and construct a Japanese Conversation dataset for Real-world Reference Resolution (J-CRe3). Our dataset contains egocentric video and dialogue audio of real-world conversations between two people acting as a master and an assistant robot at home. The dataset is annotated with crossmodal tags between phrases in the utterances and the object bounding boxes in the video frames. These tags include indirect reference relations, such as predicate-argument structures and bridging references as well as direct reference relations. We also constructed an experimental model and clarified the challenges in multimodal reference resolution tasks.
A Gaze-grounded Visual Question Answering Dataset for Clarifying Ambiguous Japanese Questions
Mar 26, 2024Situated conversations, which refer to visual information as visual question answering (VQA), often contain ambiguities caused by reliance on directive information. This problem is exacerbated because some languages, such as Japanese, often omit subjective or objective terms. Such ambiguities in questions are often clarified by the contexts in conversational situations, such as joint attention with a user or user gaze information. In this study, we propose the Gaze-grounded VQA dataset (GazeVQA) that clarifies ambiguous questions using gaze information by focusing on a clarification process complemented by gaze information. We also propose a method that utilizes gaze target estimation results to improve the accuracy of GazeVQA tasks. Our experimental results showed that the proposed method improved the performance in some cases of a VQA system on GazeVQA and identified some typical problems of GazeVQA tasks that need to be improved.
What Should the System Do Next?: Operative Action Captioning for Estimating System Actions
Oct 06, 2022
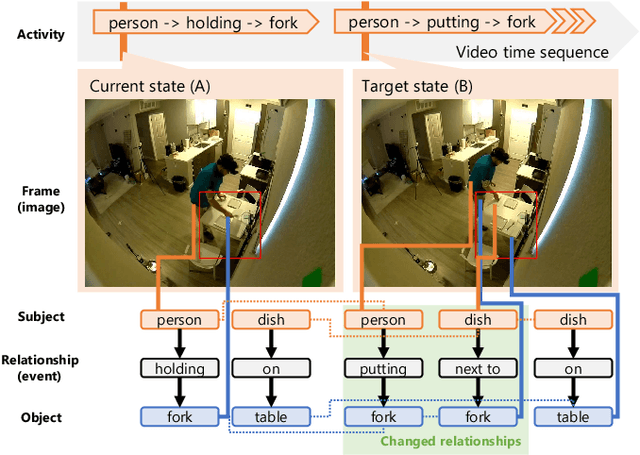
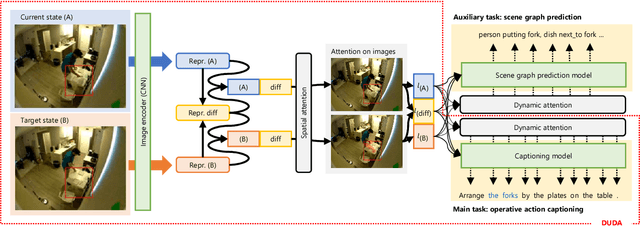

Such human-assisting systems as robots need to correctly understand the surrounding situation based on observations and output the required support actions for humans. Language is one of the important channels to communicate with humans, and the robots are required to have the ability to express their understanding and action planning results. In this study, we propose a new task of operative action captioning that estimates and verbalizes the actions to be taken by the system in a human-assisting domain. We constructed a system that outputs a verbal description of a possible operative action that changes the current state to the given target state. We collected a dataset consisting of two images as observations, which express the current state and the state changed by actions, and a caption that describes the actions that change the current state to the target state, by crowdsourcing in daily life situations. Then we constructed a system that estimates operative action by a caption. Since the operative action's caption is expected to contain some state-changing actions, we use scene-graph prediction as an auxiliary task because the events written in the scene graphs correspond to the state changes. Experimental results showed that our system successfully described the operative actions that should be conducted between the current and target states. The auxiliary tasks that predict the scene graphs improved the quality of the estimation results.
Toward an Affective Touch Robot: Subjective and Physiological Evaluation of Gentle Stroke Motion Using a Human-Imitation Hand
Dec 09, 2020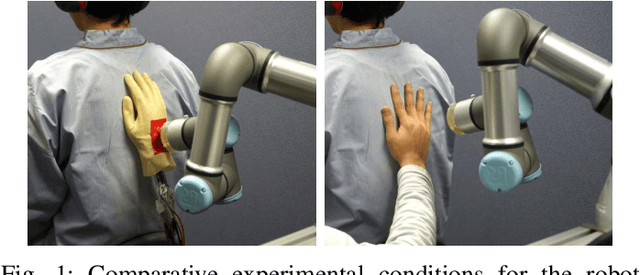
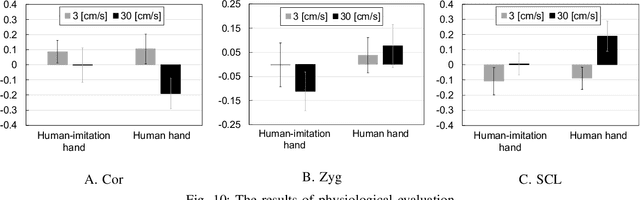
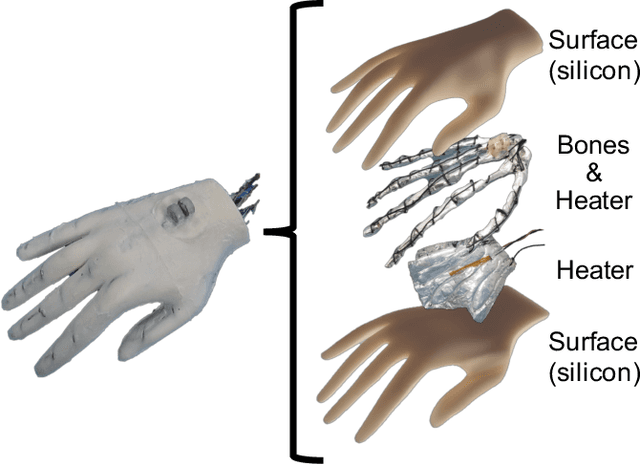
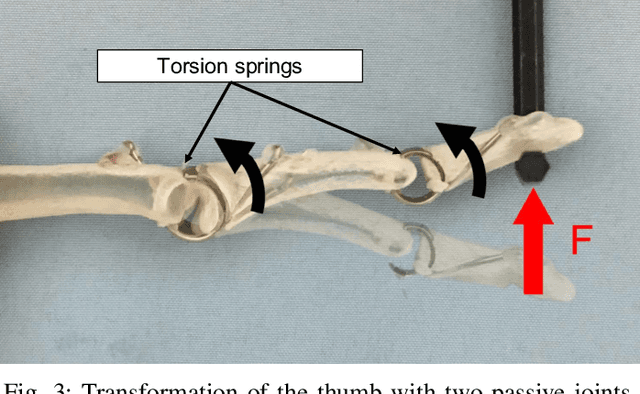
Affective touch offers positive psychological and physiological benefits such as the mitigation of stress and pain. If a robot could realize human-like affective touch, it would open up new application areas, including supporting care work. In this research, we focused on the gentle stroking motion of a robot to evoke the same emotions that human touch would evoke: in other words, an affective touch robot. We propose a robot that is able to gently stroke the back of a human using our designed human-imitation hand. To evaluate the emotional effects of this affective touch, we compared the results of a combination of two agents (the human-imitation hand and the human hand), at two stroke speeds (3 and 30 cm/s). The results of the subjective and physiological evaluations highlighted the following three findings: 1) the subjects evaluated strokes similarly with regard to the stroke speed of the human and human-imitation hand, in both the subjective and physiological evaluations; 2) the subjects felt greater pleasure and arousal at the faster stroke rate (30 cm/s rather than 3 cm/s); and 3) poorer fitting of the human-imitation hand due to the bending of the back had a negative emotional effect on the subjects.