 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuro-Symbolic Contrastive Learning for Cross-domain Inference
Feb 13, 2025Pre-trained language models (PLMs) have made significant advances in natural language inference (NLI) tasks, however their sensitivity to textual perturbations and dependence on large datasets indicate an over-reliance on shallow heuristics. In contrast, inductive logic programming (ILP) excels at inferring logical relationships across diverse, sparse and limited datasets, but its discrete nature requires the inputs to be precisely specified, which limits their application. This paper proposes a bridge between the two approaches: neuro-symbolic contrastive learning. This allows for smooth and differentiable optimisation that improves logical accuracy across an otherwise discrete, noisy, and sparse topological space of logical functions. We show that abstract logical relationships can be effectively embedded within a neuro-symbolic paradigm, by representing data as logic programs and sets of logic rules. The embedding space captures highly varied textual information with similar semantic logical relations, but can also separate similar textual relations that have dissimilar logical relations. Experimental results demonstrate that our approach significantly improves the inference capabilities of the models in terms of generalisation and reasoning.
* In Proceedings ICLP 2024, arXiv:2502.08453
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Repeat and Concatenate: 2D to 3D Image Translation with 3D to 3D Generative Modeling
Jun 26, 2024



This paper investigates a 2D to 3D image translation method with a straightforward technique, enabling correlated 2D X-ray to 3D CT-like reconstruction. We observe that existing approaches, which integrate information across multiple 2D views in the latent space, lose valuable signal information during latent encoding. Instead, we simply repeat and concatenate the 2D views into higher-channel 3D volumes and approach the 3D reconstruction challenge as a straightforward 3D to 3D generative modeling problem, sidestepping several complex modeling issues. This method enables the reconstructed 3D volume to retain valuable information from the 2D inputs, which are passed between channel states in a Swin UNETR backbone. Our approach applies neural optimal transport, which is fast and stable to train, effectively integrating signal information across multiple views without the requirement for precise alignment; it produces non-collapsed reconstructions that are highly faithful to the 2D views, even after limited training. We demonstrate correlated results, both qualitatively and quantitatively, having trained our model on a single dataset and evaluated its generalization ability across six datasets, including out-of-distribution samples.
Unaligned 2D to 3D Translation with Conditional Vector-Quantized Code Diffusion using Transformers
Aug 27, 2023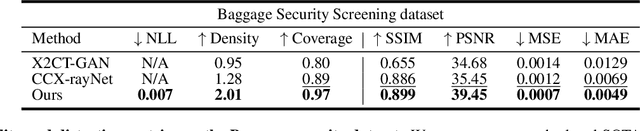
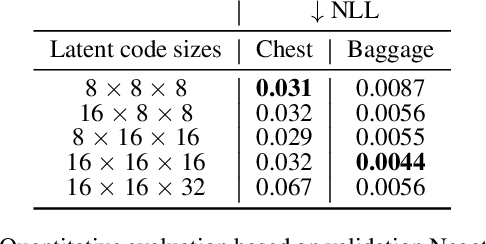

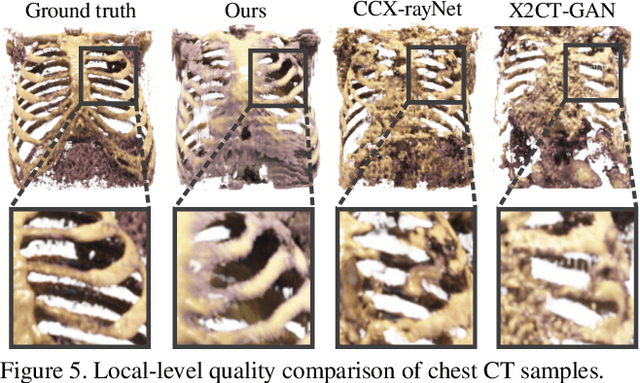
Generating 3D images of complex objects conditionally from a few 2D views is a difficult synthesis problem, compounded by issues such as domain gap and geometric misalignment. For instance, a unified framework such as Generative Adversarial Networks cannot achieve this unless they explicitly define both a domain-invariant and geometric-invariant joint latent distribution, whereas Neural Radiance Fields are generally unable to handle both issues as they optimize at the pixel level. By contrast, we propose a simple and novel 2D to 3D synthesis approach based on conditional diffusion with vector-quantized codes. Operating in an information-rich code space enables high-resolution 3D synthesis via full-coverage attention across the views. Specifically, we generate the 3D codes (e.g. for CT images) conditional on previously generated 3D codes and the entire codebook of two 2D views (e.g. 2D X-rays). Qualitative and quantitative results demonstrate state-of-the-art performance over specialized methods across varied evaluation criteria, including fidelity metrics such as density, coverage, and distortion metrics for two complex volumetric imagery datasets from in real-world scenarios.
$\infty$-Diff: Infinite Resolution Diffusion with Subsampled Mollified States
Mar 31, 2023



We introduce $\infty$-Diff, a generative diffusion model which directly operates on infinite resolution data. By randomly sampling subsets of coordinates during training and learning to denoise the content at those coordinates, a continuous function is learned that allows sampling at arbitrary resolutions. In contrast to other recent infinite resolution generative models, our approach operates directly on the raw data, not requiring latent vector compression for context, using hypernetworks, nor relying on discrete components. As such, our approach achieves significantly higher sample quality, as evidenced by lower FID scores, as well as being able to effectively scale to higher resolutions than the training data while retaining detail.
Exact-NeRF: An Exploration of a Precise Volumetric Parameterization for Neural Radiance Fields
Nov 22, 2022



Neural Radiance Fields (NeRF) have attracted significant attention due to their ability to synthesize novel scene views with great accuracy. However, inherent to their underlying formulation, the sampling of points along a ray with zero width may result in ambiguous representations that lead to further rendering artifacts such as aliasing in the final scene. To address this issue, the recent variant mip-NeRF proposes an Integrated Positional Encoding (IPE) based on a conical view frustum. Although this is expressed with an integral formulation, mip-NeRF instead approximates this integral as the expected value of a multivariate Gaussian distribution. This approximation is reliable for short frustums but degrades with highly elongated regions, which arises when dealing with distant scene objects under a larger depth of field. In this paper, we explore the use of an exact approach for calculating the IPE by using a pyramid-based integral formulation instead of an approximated conical-based one. We denote this formulation as Exact-NeRF and contribute the first approach to offer a precise analytical solution to the IPE within the NeRF domain. Our exploratory work illustrates that such an exact formulation Exact-NeRF matches the accuracy of mip-NeRF and furthermore provides a natural extension to more challenging scenarios without further modification, such as in the case of unbounded scenes. Our contribution aims to both address the hitherto unexplored issues of frustum approximation in earlier NeRF work and additionally provide insight into the potential future consideration of analytical solutions in future NeRF extensions.
Megapixel Image Generation with Step-Unrolled Denoising Autoencoders
Jun 24, 2022

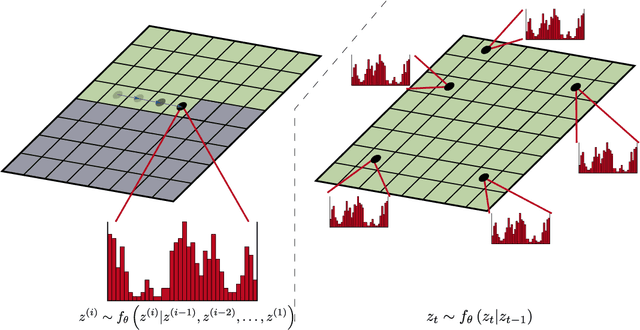

An ongoing trend in generative modelling research has been to push sample resolutions higher whilst simultaneously reducing computational requirements for training and sampling. We aim to push this trend further via the combination of techniques - each component representing the current pinnacle of efficiency in their respective areas. These include vector-quantized GAN (VQ-GAN), a vector-quantization (VQ) model capable of high levels of lossy - but perceptually insignificant - compression; hourglass transformers, a highly scaleable self-attention model; and step-unrolled denoising autoencoders (SUNDAE), a non-autoregressive (NAR) text generative model. Unexpectedly, our method highlights weaknesses in the original formulation of hourglass transformers when applied to multidimensional data. In light of this, we propose modifications to the resampling mechanism, applicable in any task applying hierarchical transformers to multidimensional data. Additionally, we demonstrate the scalability of SUNDAE to long sequence lengths - four times longer than prior work. Our proposed framework scales to high-resolutions ($1024 \times 1024$) and trains quickly (2-4 days). Crucially, the trained model produces diverse and realistic megapixel samples in approximately 2 seconds on a consumer-grade GPU (GTX 1080Ti). In general, the framework is flexible: supporting an arbitrary number of sampling steps, sample-wise self-stopping, self-correction capabilities, conditional generation, and a NAR formulation that allows for arbitrary inpainting masks. We obtain FID scores of 10.56 on FFHQ256 - close to the original VQ-GAN in less than half the sampling steps - and 21.85 on FFHQ1024 in only 100 sampling steps.
MedNeRF: Medical Neural Radiance Fields for Reconstructing 3D-aware CT-Projections from a Single X-ray
Feb 02, 2022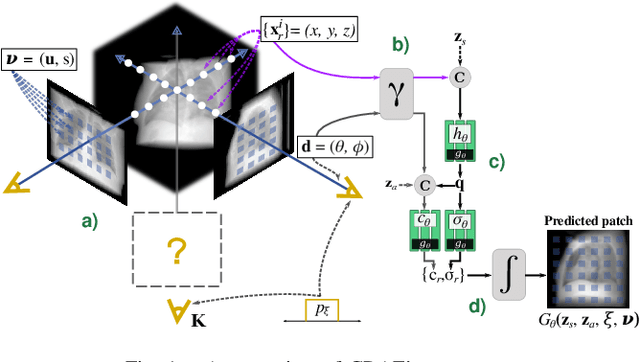
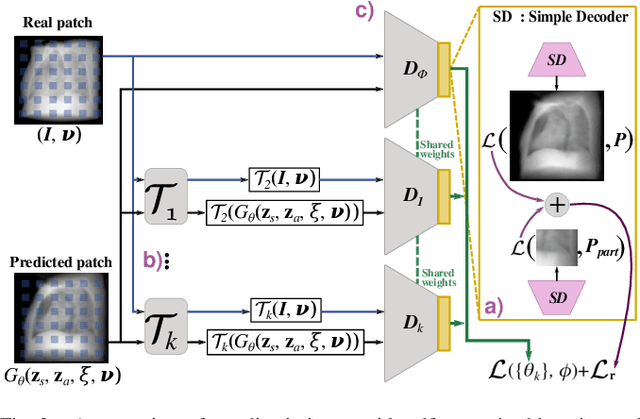
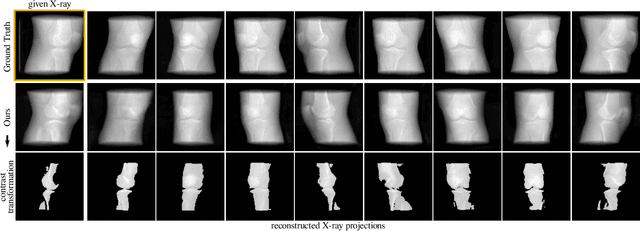
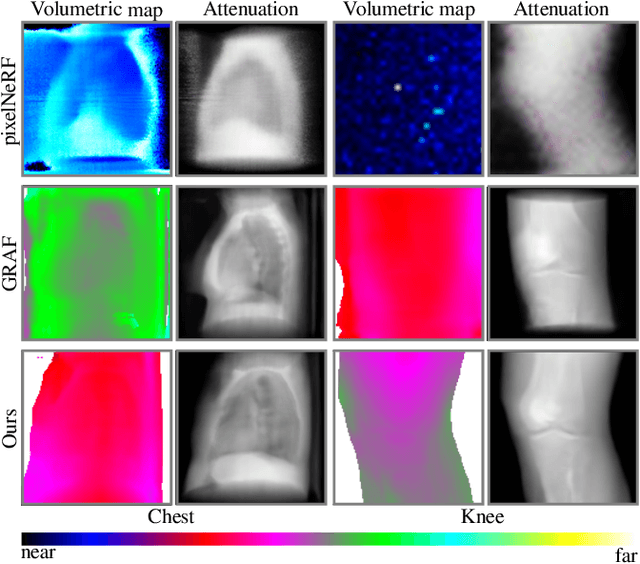
Computed tomography (CT) is an effective medical imaging modality, widely used in the field of clinical medicine for the diagnosis of various pathologies. Advances in Multidetector CT imaging technology have enabled additional functionalities, including generation of thin slice multiplanar cross-sectional body imaging and 3D reconstructions. However, this involves patients being exposed to a considerable dose of ionising radiation. Excessive ionising radiation can lead to deterministic and harmful effects on the body. This paper proposes a Deep Learning model that learns to reconstruct CT projections from a few or even a single-view X-ray. This is based on a novel architecture that builds from neural radiance fields, which learns a continuous representation of CT scans by disentangling the shape and volumetric depth of surface and internal anatomical structures from 2D images. Our model is trained on chest and knee datasets, and we demonstrate qualitative and quantitative high-fidelity renderings and compare our approach to other recent radiance field-based methods. Our code and link to our datasets will be available at our GitHub.
Unleashing Transformers: Parallel Token Prediction with Discrete Absorbing Diffusion for Fast High-Resolution Image Generation from Vector-Quantized Codes
Nov 24, 2021
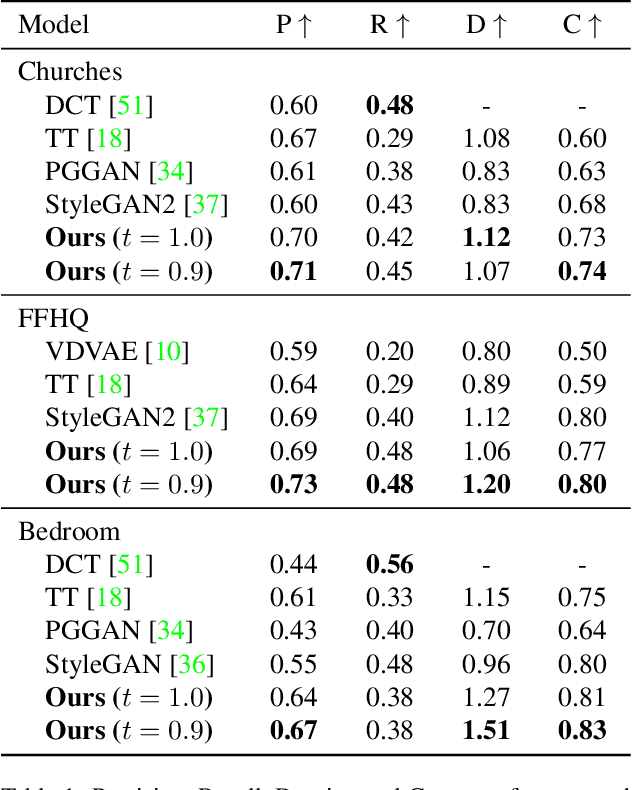
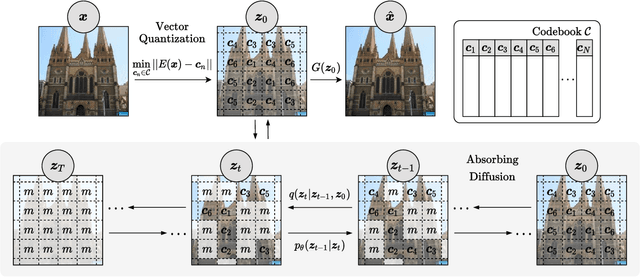
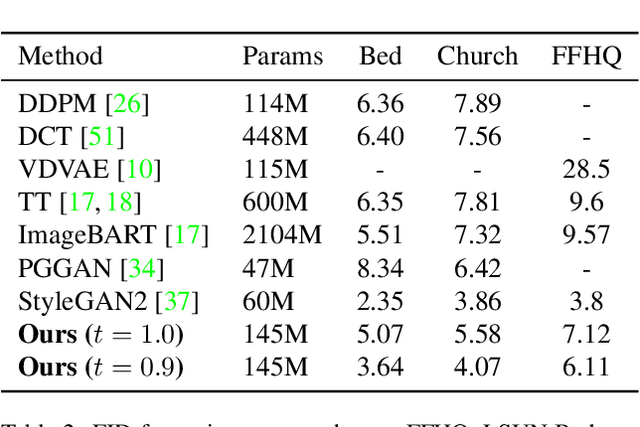
Whilst diffusion probabilistic models can generate high quality image content, key limitations remain in terms of both generating high-resolution imagery and their associated high computational requirements. Recent Vector-Quantized image models have overcome this limitation of image resolution but are prohibitively slow and unidirectional as they generate tokens via element-wise autoregressive sampling from the prior. By contrast, in this paper we propose a novel discrete diffusion probabilistic model prior which enables parallel prediction of Vector-Quantized tokens by using an unconstrained Transformer architecture as the backbone. During training, tokens are randomly masked in an order-agnostic manner and the Transformer learns to predict the original tokens. This parallelism of Vector-Quantized token prediction in turn facilitates unconditional generation of globally consistent high-resolution and diverse imagery at a fraction of the computational expense. In this manner, we can generate image resolutions exceeding that of the original training set samples whilst additionally provisioning per-image likelihood estimates (in a departure from generative adversarial approaches). Our approach achieves state-of-the-art results in terms of Density (LSUN Bedroom: 1.51; LSUN Churches: 1.12; FFHQ: 1.20) and Coverage (LSUN Bedroom: 0.83; LSUN Churches: 0.73; FFHQ: 0.80), and performs competitively on FID (LSUN Bedroom: 3.64; LSUN Churches: 4.07; FFHQ: 6.11) whilst offering advantages in terms of both computation and reduced training set requirements.
UNIT-DDPM: UNpaired Image Translation with Denoising Diffusion Probabilistic Models
Apr 12, 2021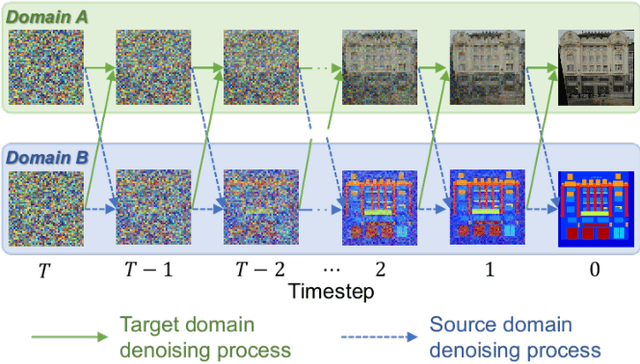
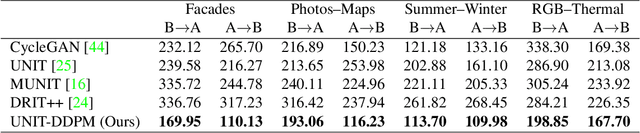


We propose a novel unpaired image-to-image translation method that uses denoising diffusion probabilistic models without requiring adversarial training. Our method, UNpaired Image Translation with Denoising Diffusion Probabilistic Models (UNIT-DDPM), trains a generative model to infer the joint distribution of images over both domains as a Markov chain by minimising a denoising score matching objective conditioned on the other domain. In particular, we update both domain translation models simultaneously, and we generate target domain images by a denoising Markov Chain Monte Carlo approach that is conditioned on the input source domain images, based on Langevin dynamics. Our approach provides stable model training for image-to-image translation and generates high-quality image outputs. This enables state-of-the-art Fr\'echet Inception Distance (FID) performance on several public datasets, including both colour and multispectral imagery, significantly outperforming the contemporary adversarial image-to-image translation methods.