 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJSynFlow: Japanese Synthesised Flowchart Visual Question Answering Dataset built with Large Language Models
Feb 05, 2026Vision and language models (VLMs) are expected to analyse complex documents, such as those containing flowcharts, through a question-answering (QA) interface. The ability to recognise and interpret these flowcharts is in high demand, as they provide valuable insights unavailable in text-only explanations. However, developing VLMs with precise flowchart understanding requires large-scale datasets of flowchart images and corresponding text, the creation of which is highly time-consuming. To address this challenge, we introduce JSynFlow, a synthesised visual QA dataset for Japanese flowcharts, generated using large language models (LLMs). Our dataset comprises task descriptions for various business occupations, the corresponding flowchart images rendered from domain-specific language (DSL) code, and related QA pairs. This paper details the dataset's synthesis procedure and demonstrates that fine-tuning with JSynFlow significantly improves VLM performance on flowchart-based QA tasks. Our dataset is publicly available at https://huggingface.co/datasets/jri-advtechlab/jsynflow.
* 7 pages, 1 figure
Unleashing Transformers: Parallel Token Prediction with Discrete Absorbing Diffusion for Fast High-Resolution Image Generation from Vector-Quantized Codes
Nov 24, 2021
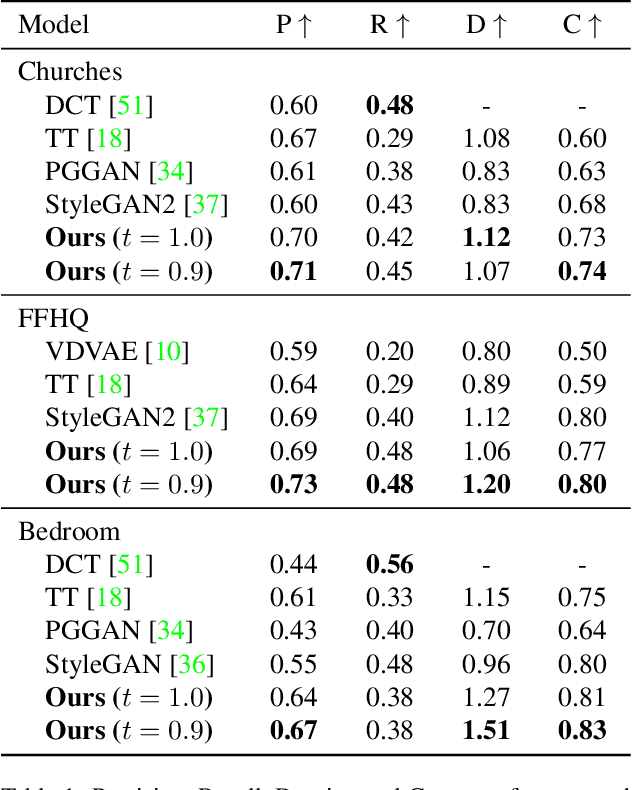
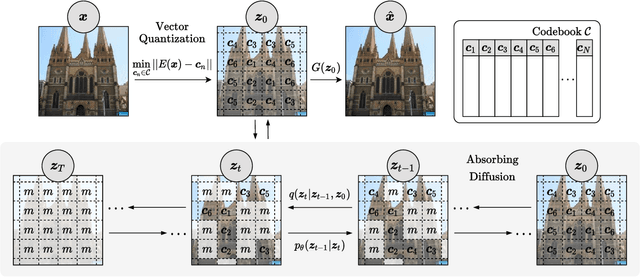
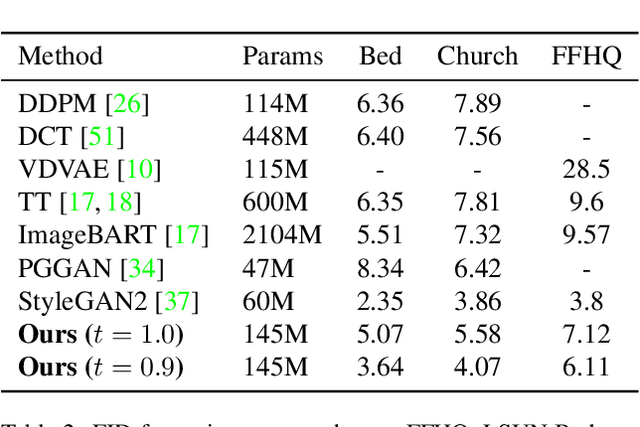
Whilst diffusion probabilistic models can generate high quality image content, key limitations remain in terms of both generating high-resolution imagery and their associated high computational requirements. Recent Vector-Quantized image models have overcome this limitation of image resolution but are prohibitively slow and unidirectional as they generate tokens via element-wise autoregressive sampling from the prior. By contrast, in this paper we propose a novel discrete diffusion probabilistic model prior which enables parallel prediction of Vector-Quantized tokens by using an unconstrained Transformer architecture as the backbone. During training, tokens are randomly masked in an order-agnostic manner and the Transformer learns to predict the original tokens. This parallelism of Vector-Quantized token prediction in turn facilitates unconditional generation of globally consistent high-resolution and diverse imagery at a fraction of the computational expense. In this manner, we can generate image resolutions exceeding that of the original training set samples whilst additionally provisioning per-image likelihood estimates (in a departure from generative adversarial approaches). Our approach achieves state-of-the-art results in terms of Density (LSUN Bedroom: 1.51; LSUN Churches: 1.12; FFHQ: 1.20) and Coverage (LSUN Bedroom: 0.83; LSUN Churches: 0.73; FFHQ: 0.80), and performs competitively on FID (LSUN Bedroom: 3.64; LSUN Churches: 4.07; FFHQ: 6.11) whilst offering advantages in terms of both computation and reduced training set requirements.
UNIT-DDPM: UNpaired Image Translation with Denoising Diffusion Probabilistic Models
Apr 12, 2021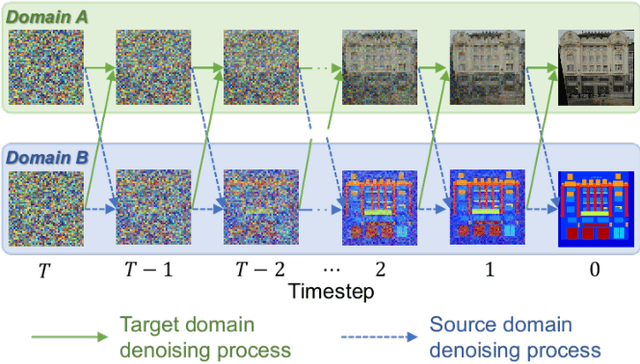
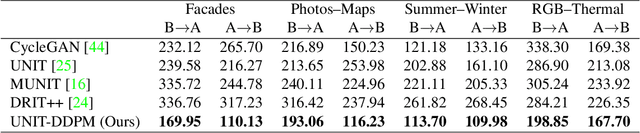


We propose a novel unpaired image-to-image translation method that uses denoising diffusion probabilistic models without requiring adversarial training. Our method, UNpaired Image Translation with Denoising Diffusion Probabilistic Models (UNIT-DDPM), trains a generative model to infer the joint distribution of images over both domains as a Markov chain by minimising a denoising score matching objective conditioned on the other domain. In particular, we update both domain translation models simultaneously, and we generate target domain images by a denoising Markov Chain Monte Carlo approach that is conditioned on the input source domain images, based on Langevin dynamics. Our approach provides stable model training for image-to-image translation and generates high-quality image outputs. This enables state-of-the-art Fr\'echet Inception Distance (FID) performance on several public datasets, including both colour and multispectral imagery, significantly outperforming the contemporary adversarial image-to-image translation methods.
Model-based approach for analyzing prevalence of nuclear cataracts in elderly residents
Sep 17, 2020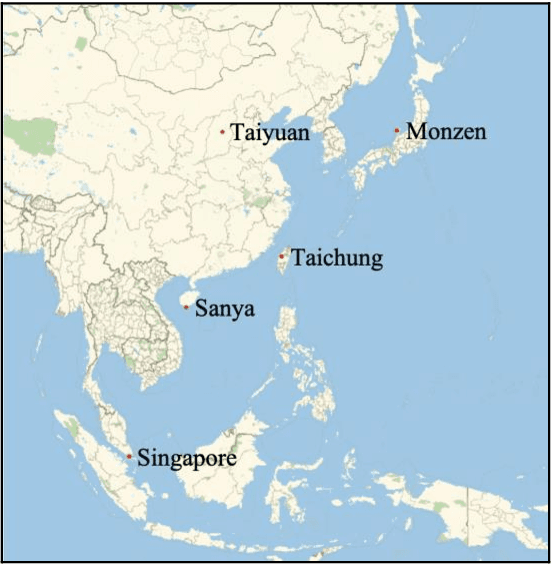

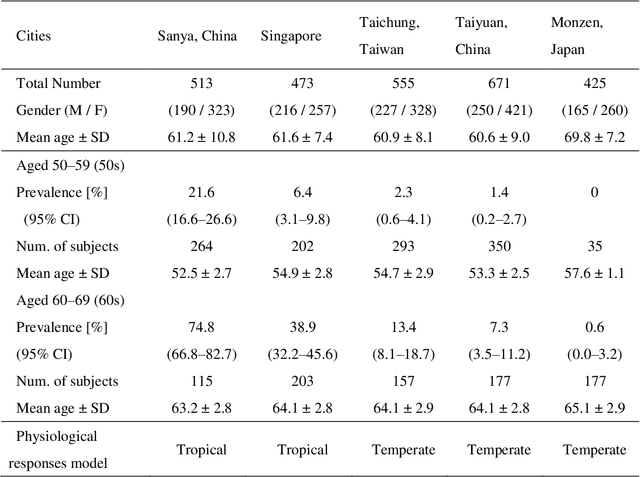

Recent epidemiological studies have hypothesized that the prevalence of cortical cataracts is closely related to ultraviolet radiation. However, the prevalence of nuclear cataracts is higher in elderly people in tropical areas than in temperate areas. The dominant factors inducing nuclear cataracts have been widely debated. In this study, the temperature increase in the lens due to exposure to ambient conditions was computationally quantified in subjects of 50-60 years of age in tropical and temperate areas, accounting for differences in thermoregulation. A thermoregulatory response model was extended to consider elderly people in tropical areas. The time course of lens temperature for different weather conditions in five cities in Asia was computed. The temperature was higher around the mid and posterior part of the lens, which coincides with the position of the nuclear cataract. The duration of higher temperatures in the lens varied, although the daily maximum temperatures were comparable. A strong correlation (adjusted R2 > 0.85) was observed between the prevalence of nuclear cataract and the computed cumulative thermal dose in the lens. We propose the use of a cumulative thermal dose to assess the prevalence of nuclear cataracts. Cumulative wet-bulb globe temperature, a new metric computed from weather data, would be useful for practical assessment in different cities.
Data Augmentation via Mixed Class Interpolation using Cycle-Consistent Generative Adversarial Networks Applied to Cross-Domain Imagery
May 05, 2020
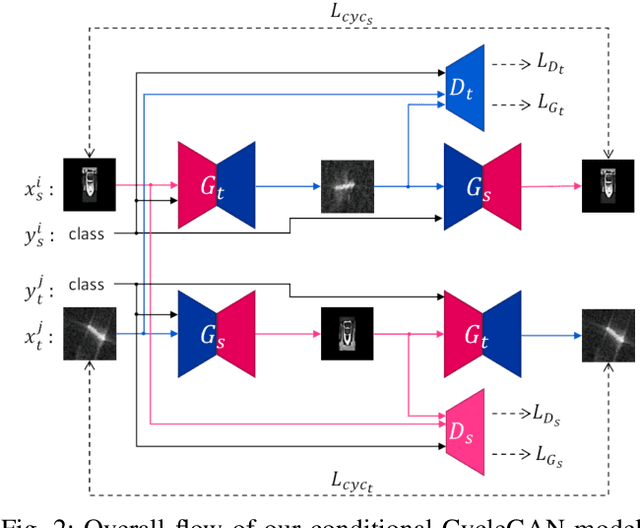


Machine learning driven object detection and classification within non-visible imagery has an important role in many fields such as night vision, all-weather surveillance and aviation security. However, such applications often suffer due to the limited quantity and variety of non-visible spectral domain imagery, where by contrast the high data availability in visible-band imagery readily enables contemporary deep learning driven detection and classification approaches. To address this problem, this paper proposes and evaluates a novel data augmentation approach that leverages the more readily available visible-band imagery via a generative domain transfer model. The model can synthesise large volumes of non-visible domain imagery by image translation from the visible image domain. Furthermore, we show that the generation of interpolated mixed class (non-visible domain) image examples via our novel Conditional CycleGAN Mixup Augmentation (C2GMA) methodology can lead to a significant improvement in the quality for non-visible domain classification tasks that otherwise suffer due to limited data availability. Focusing on classification within the Synthetic Aperture Radar (SAR) domain, our approach is evaluated on a variation of the Statoil/C-CORE Iceberg Classifier Challenge dataset and achieves 75.4% accuracy, demonstrating a significant improvement when compared against traditional data augmentation strategies.