 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMegapixel Image Generation with Step-Unrolled Denoising Autoencoders
Jun 24, 2022

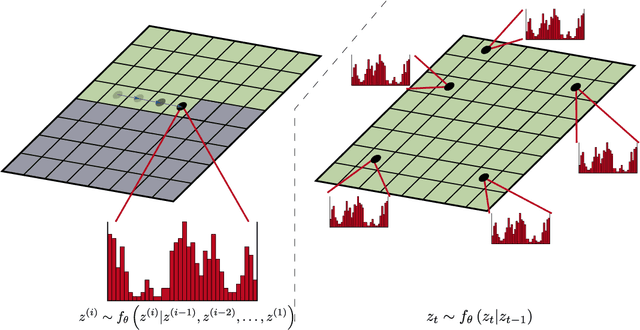

An ongoing trend in generative modelling research has been to push sample resolutions higher whilst simultaneously reducing computational requirements for training and sampling. We aim to push this trend further via the combination of techniques - each component representing the current pinnacle of efficiency in their respective areas. These include vector-quantized GAN (VQ-GAN), a vector-quantization (VQ) model capable of high levels of lossy - but perceptually insignificant - compression; hourglass transformers, a highly scaleable self-attention model; and step-unrolled denoising autoencoders (SUNDAE), a non-autoregressive (NAR) text generative model. Unexpectedly, our method highlights weaknesses in the original formulation of hourglass transformers when applied to multidimensional data. In light of this, we propose modifications to the resampling mechanism, applicable in any task applying hierarchical transformers to multidimensional data. Additionally, we demonstrate the scalability of SUNDAE to long sequence lengths - four times longer than prior work. Our proposed framework scales to high-resolutions ($1024 \times 1024$) and trains quickly (2-4 days). Crucially, the trained model produces diverse and realistic megapixel samples in approximately 2 seconds on a consumer-grade GPU (GTX 1080Ti). In general, the framework is flexible: supporting an arbitrary number of sampling steps, sample-wise self-stopping, self-correction capabilities, conditional generation, and a NAR formulation that allows for arbitrary inpainting masks. We obtain FID scores of 10.56 on FFHQ256 - close to the original VQ-GAN in less than half the sampling steps - and 21.85 on FFHQ1024 in only 100 sampling steps.
Non-Intrusive Binaural Speech Intelligibility Prediction from Discrete Latent Representations
Nov 24, 2021
Non-intrusive speech intelligibility (SI) prediction from binaural signals is useful in many applications. However, most existing signal-based measures are designed to be applied to single-channel signals. Measures specifically designed to take into account the binaural properties of the signal are often intrusive - characterised by requiring access to a clean speech signal - and typically rely on combining both channels into a single-channel signal before making predictions. This paper proposes a non-intrusive SI measure that computes features from a binaural input signal using a combination of vector quantization (VQ) and contrastive predictive coding (CPC) methods. VQ-CPC feature extraction does not rely on any model of the auditory system and is instead trained to maximise the mutual information between the input signal and output features. The computed VQ-CPC features are input to a predicting function parameterized by a neural network. Two predicting functions are considered in this paper. Both feature extractor and predicting functions are trained on simulated binaural signals with isotropic noise. They are tested on simulated signals with isotropic and real noise. For all signals, the ground truth scores are the (intrusive) deterministic binaural STOI. Results are presented in terms of correlations and MSE and demonstrate that VQ-CPC features are able to capture information relevant to modelling SI and outperform all the considered benchmarks - even when evaluating on data comprising of different noise field types.