 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Saliency Explanations in NLP by Crowdsourcing
Paper and Code

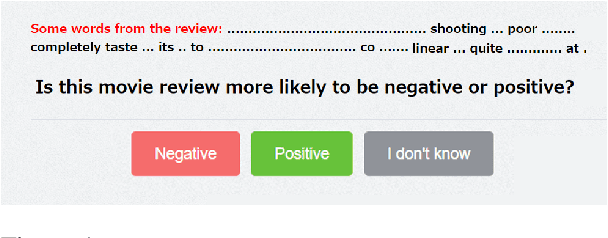


Deep learning models have performed well on many NLP tasks. However, their internal mechanisms are typically difficult for humans to understand. The development of methods to explain models has become a key issue in the reliability of deep learning models in many important applications. Various saliency explanation methods, which give each feature of input a score proportional to the contribution of output, have been proposed to determine the part of the input which a model values most. Despite a considerable body of work on the evaluation of saliency methods, whether the results of various evaluation metrics agree with human cognition remains an open question. In this study, we propose a new human-based method to evaluate saliency methods in NLP by crowdsourcing. We recruited 800 crowd workers and empirically evaluated seven saliency methods on two datasets with the proposed method. We analyzed the performance of saliency methods, compared our results with existing automated evaluation methods, and identified notable differences between NLP and computer vision (CV) fields when using saliency methods. The instance-level data of our crowdsourced experiments and the code to reproduce the explanations are available at https://github.com/xtlu/lreccoling_evaluation.