 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAHP-Powered LLM Reasoning for Multi-Criteria Evaluation of Open-Ended Responses
Oct 02, 2024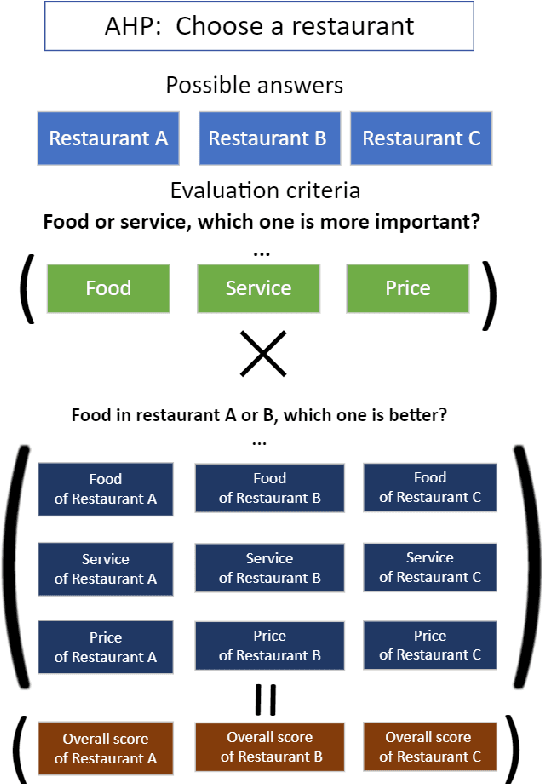



Question answering (QA) tasks have been extensively studied in the field of natural language processing (NLP). Answers to open-ended questions are highly diverse and difficult to quantify, and cannot be simply evaluated as correct or incorrect, unlike close-ended questions with definitive answers. While large language models (LLMs) have demonstrated strong capabilities across various tasks, they exhibit relatively weaker performance in evaluating answers to open-ended questions. In this study, we propose a method that leverages LLMs and the analytic hierarchy process (AHP) to assess answers to open-ended questions. We utilized LLMs to generate multiple evaluation criteria for a question. Subsequently, answers were subjected to pairwise comparisons under each criterion with LLMs, and scores for each answer were calculated in the AHP. We conducted experiments on four datasets using both ChatGPT-3.5-turbo and GPT-4. Our results indicate that our approach more closely aligns with human judgment compared to the four baselines. Additionally, we explored the impact of the number of criteria, variations in models, and differences in datasets on the results.
Evaluating Saliency Explanations in NLP by Crowdsourcing
May 17, 2024
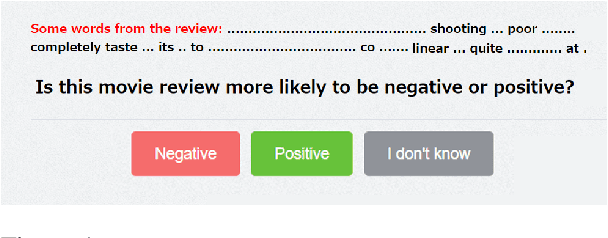


Deep learning models have performed well on many NLP tasks. However, their internal mechanisms are typically difficult for humans to understand. The development of methods to explain models has become a key issue in the reliability of deep learning models in many important applications. Various saliency explanation methods, which give each feature of input a score proportional to the contribution of output, have been proposed to determine the part of the input which a model values most. Despite a considerable body of work on the evaluation of saliency methods, whether the results of various evaluation metrics agree with human cognition remains an open question. In this study, we propose a new human-based method to evaluate saliency methods in NLP by crowdsourcing. We recruited 800 crowd workers and empirically evaluated seven saliency methods on two datasets with the proposed method. We analyzed the performance of saliency methods, compared our results with existing automated evaluation methods, and identified notable differences between NLP and computer vision (CV) fields when using saliency methods. The instance-level data of our crowdsourced experiments and the code to reproduce the explanations are available at https://github.com/xtlu/lreccoling_evaluation.
Estimating Treatment Effects Under Heterogeneous Interference
Sep 25, 2023Treatment effect estimation can assist in effective decision-making in e-commerce, medicine, and education. One popular application of this estimation lies in the prediction of the impact of a treatment (e.g., a promotion) on an outcome (e.g., sales) of a particular unit (e.g., an item), known as the individual treatment effect (ITE). In many online applications, the outcome of a unit can be affected by the treatments of other units, as units are often associated, which is referred to as interference. For example, on an online shopping website, sales of an item will be influenced by an advertisement of its co-purchased item. Prior studies have attempted to model interference to estimate the ITE accurately, but they often assume a homogeneous interference, i.e., relationships between units only have a single view. However, in real-world applications, interference may be heterogeneous, with multi-view relationships. For instance, the sale of an item is usually affected by the treatment of its co-purchased and co-viewed items. We hypothesize that ITE estimation will be inaccurate if this heterogeneous interference is not properly modeled. Therefore, we propose a novel approach to model heterogeneous interference by developing a new architecture to aggregate information from diverse neighbors. Our proposed method contains graph neural networks that aggregate same-view information, a mechanism that aggregates information from different views, and attention mechanisms. In our experiments on multiple datasets with heterogeneous interference, the proposed method significantly outperforms existing methods for ITE estimation, confirming the importance of modeling heterogeneous interference.
Taming Small-sample Bias in Low-budget Active Learning
Jun 19, 2023



Active learning (AL) aims to minimize the annotation cost by only querying a few informative examples for each model training stage. However, training a model on a few queried examples suffers from the small-sample bias. In this paper, we address this small-sample bias issue in low-budget AL by exploring a regularizer called Firth bias reduction, which can provably reduce the bias during the model training process but might hinder learning if its coefficient is not adaptive to the learning progress. Instead of tuning the coefficient for each query round, which is sensitive and time-consuming, we propose the curriculum Firth bias reduction (CHAIN) that can automatically adjust the coefficient to be adaptive to the training process. Under both deep learning and linear model settings, experiments on three benchmark datasets with several widely used query strategies and hyperparameter searching methods show that CHAIN can be used to build more efficient AL and can substantially improve the progress made by each active learning query.
Multiview Representation Learning from Crowdsourced Triplet Comparisons
Feb 08, 2023



Crowdsourcing has been used to collect data at scale in numerous fields. Triplet similarity comparison is a type of crowdsourcing task, in which crowd workers are asked the question ``among three given objects, which two are more similar?'', which is relatively easy for humans to answer. However, the comparison can be sometimes based on multiple views, i.e., different independent attributes such as color and shape. Each view may lead to different results for the same three objects. Although an algorithm was proposed in prior work to produce multiview embeddings, it involves at least two problems: (1) the existing algorithm cannot independently predict multiview embeddings for a new sample, and (2) different people may prefer different views. In this study, we propose an end-to-end inductive deep learning framework to solve the multiview representation learning problem. The results show that our proposed method can obtain multiview embeddings of any object, in which each view corresponds to an independent attribute of the object. We collected two datasets from a crowdsourcing platform to experimentally investigate the performance of our proposed approach compared to conventional baseline methods.
Crowdsourcing Evaluation of Saliency-based XAI Methods
Jun 27, 2021
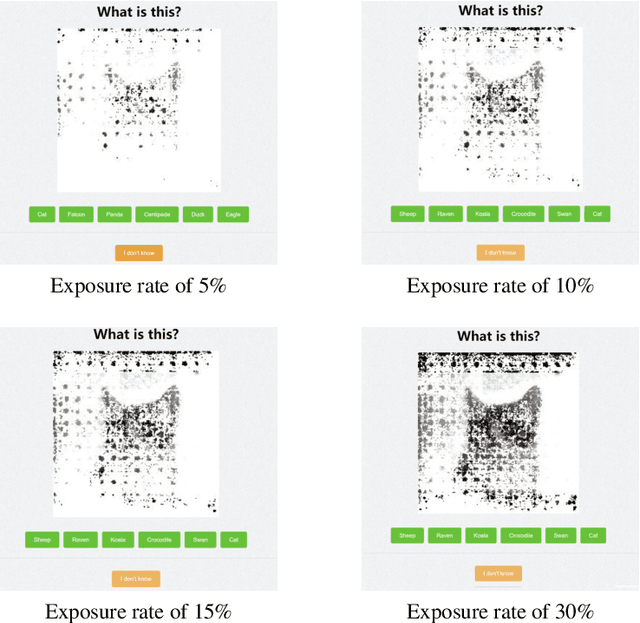

Understanding the reasons behind the predictions made by deep neural networks is critical for gaining human trust in many important applications, which is reflected in the increasing demand for explainability in AI (XAI) in recent years. Saliency-based feature attribution methods, which highlight important parts of images that contribute to decisions by classifiers, are often used as XAI methods, especially in the field of computer vision. In order to compare various saliency-based XAI methods quantitatively, several approaches for automated evaluation schemes have been proposed; however, there is no guarantee that such automated evaluation metrics correctly evaluate explainability, and a high rating by an automated evaluation scheme does not necessarily mean a high explainability for humans. In this study, instead of the automated evaluation, we propose a new human-based evaluation scheme using crowdsourcing to evaluate XAI methods. Our method is inspired by a human computation game, "Peek-a-boom", and can efficiently compare different XAI methods by exploiting the power of crowds. We evaluate the saliency maps of various XAI methods on two datasets with automated and crowd-based evaluation schemes. Our experiments show that the result of our crowd-based evaluation scheme is different from those of automated evaluation schemes. In addition, we regard the crowd-based evaluation results as ground truths and provide a quantitative performance measure to compare different automated evaluation schemes. We also discuss the impact of crowd workers on the results and show that the varying ability of crowd workers does not significantly impact the results.