 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInter-domain Multi-relational Link Prediction
Jul 09, 2021
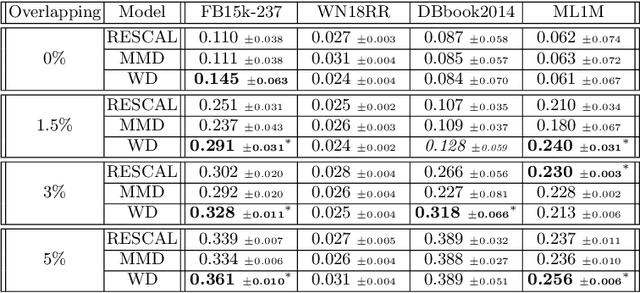
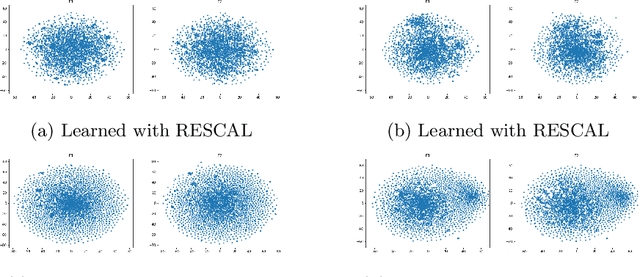
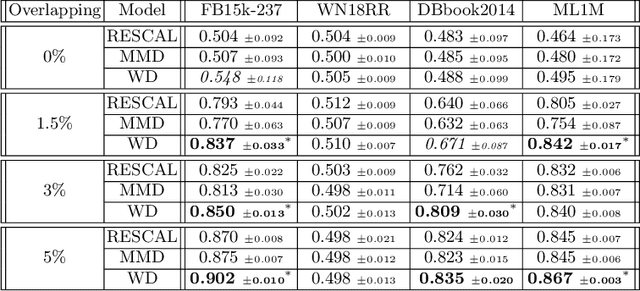
Multi-relational graph is a ubiquitous and important data structure, allowing flexible representation of multiple types of interactions and relations between entities. Similar to other graph-structured data, link prediction is one of the most important tasks on multi-relational graphs and is often used for knowledge completion. When related graphs coexist, it is of great benefit to build a larger graph via integrating the smaller ones. The integration requires predicting hidden relational connections between entities belonged to different graphs (inter-domain link prediction). However, this poses a real challenge to existing methods that are exclusively designed for link prediction between entities of the same graph only (intra-domain link prediction). In this study, we propose a new approach to tackle the inter-domain link prediction problem by softly aligning the entity distributions between different domains with optimal transport and maximum mean discrepancy regularizers. Experiments on real-world datasets show that optimal transport regularizer is beneficial and considerably improves the performance of baseline methods.
Crowdsourcing Evaluation of Saliency-based XAI Methods
Jun 27, 2021
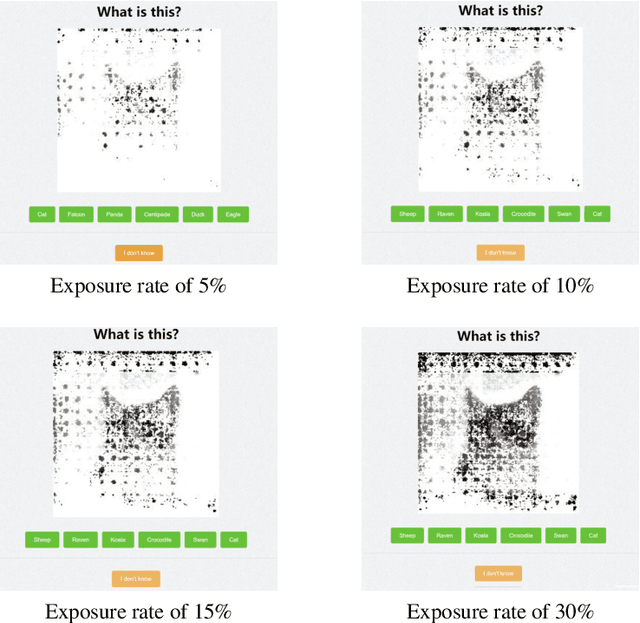

Understanding the reasons behind the predictions made by deep neural networks is critical for gaining human trust in many important applications, which is reflected in the increasing demand for explainability in AI (XAI) in recent years. Saliency-based feature attribution methods, which highlight important parts of images that contribute to decisions by classifiers, are often used as XAI methods, especially in the field of computer vision. In order to compare various saliency-based XAI methods quantitatively, several approaches for automated evaluation schemes have been proposed; however, there is no guarantee that such automated evaluation metrics correctly evaluate explainability, and a high rating by an automated evaluation scheme does not necessarily mean a high explainability for humans. In this study, instead of the automated evaluation, we propose a new human-based evaluation scheme using crowdsourcing to evaluate XAI methods. Our method is inspired by a human computation game, "Peek-a-boom", and can efficiently compare different XAI methods by exploiting the power of crowds. We evaluate the saliency maps of various XAI methods on two datasets with automated and crowd-based evaluation schemes. Our experiments show that the result of our crowd-based evaluation scheme is different from those of automated evaluation schemes. In addition, we regard the crowd-based evaluation results as ground truths and provide a quantitative performance measure to compare different automated evaluation schemes. We also discuss the impact of crowd workers on the results and show that the varying ability of crowd workers does not significantly impact the results.
A Multi-task Learning Framework for Grasping-Position Detection and Few-Shot Classification
Mar 12, 2020
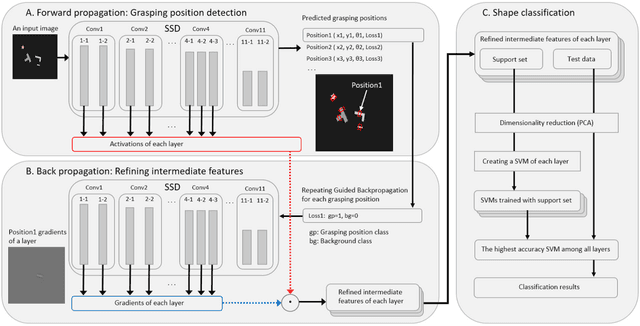
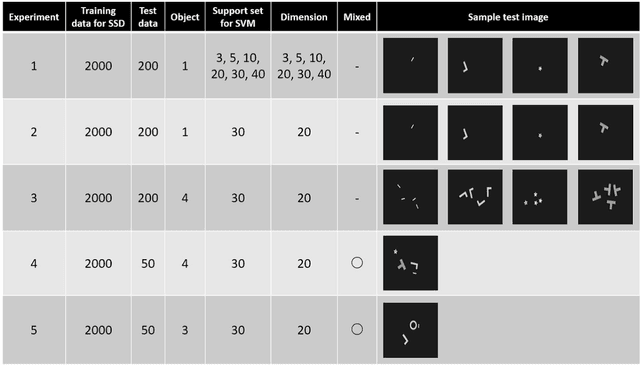

It is a big problem that a model of deep learning for a picking robot needs many labeled images. Operating costs of retraining a model becomes very expensive because the object shape of a product or a part often is changed in a factory. It is important to reduce the amount of labeled images required to train a model for a picking robot. In this study, we propose a multi-task learning framework for few-shot classification using feature vectors from an intermediate layer of a model that detects grasping positions. In the field of manufacturing, multitask for shape classification and grasping-position detection is often required for picking robots. Prior multi-task learning studies include methods to learn one task with feature vectors from a deep neural network (DNN) learned for another task. However, the DNN that was used to detect grasping positions has two problems with respect to extracting feature vectors from a layer for shape classification: (1) Because each layer of the grasping position detection DNN is activated by all objects in the input image, it is necessary to refine the features for each grasping position. (2) It is necessary to select a layer to extract the features suitable for shape classification. To tackle these issues, we propose a method to refine the features for each grasping position and to select features from the optimal layer of the DNN. We then evaluated the shape classification accuracy using these features from the grasping positions. Our results confirm that our proposed framework can classify object shapes even when the input image includes multiple objects and the number of images available for training is small.
Online Self-Supervised Learning for Object Picking: Detecting Optimum Grasping Position using a Metric Learning Approach
Mar 08, 2020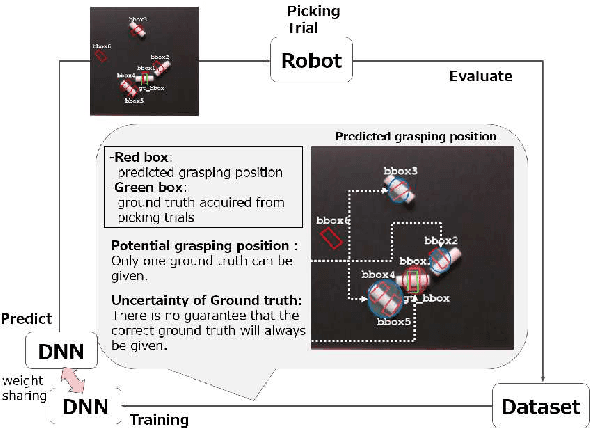
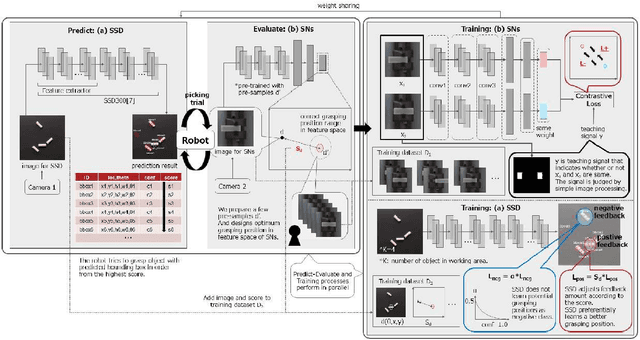
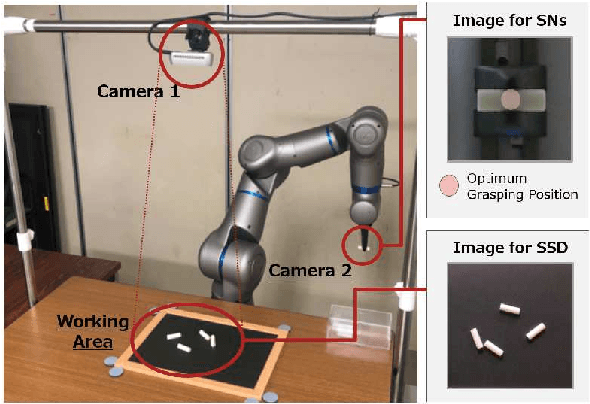
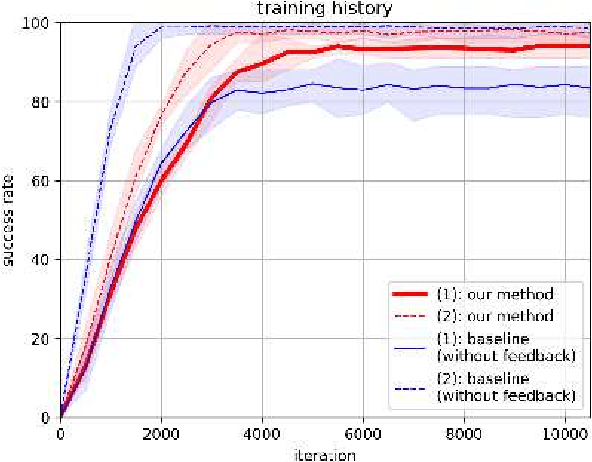
Self-supervised learning methods are attractive candidates for automatic object picking. However, the trial samples lack the complete ground truth because the observable parts of the agent are limited. That is, the information contained in the trial samples is often insufficient to learn the specific grasping position of each object. Consequently, the training falls into a local solution, and the grasp positions learned by the robot are independent of the state of the object. In this study, the optimal grasping position of an individual object is determined from the grasping score, defined as the distance in the feature space obtained using metric learning. The closeness of the solution to the pre-designed optimal grasping position was evaluated in trials. The proposed method incorporates two types of feedback control: one feedback enlarges the grasping score when the grasping position approaches the optimum; the other reduces the negative feedback of the potential grasping positions among the grasping candidates. The proposed online self-supervised learning method employs two deep neural networks. : SSD that detects the grasping position of an object, and Siamese networks (SNs) that evaluate the trial sample using the similarity of two input data in the feature space. Our method embeds the relation of each grasping position as feature vectors by training the trial samples and a few pre-samples indicating the optimum grasping position. By incorporating the grasping score based on the feature space of SNs into the SSD training process, the method preferentially trains the optimum grasping position. In the experiment, the proposed method achieved a higher success rate than the baseline method using simple teaching signals. And the grasping scores in the feature space of the SNs accurately represented the grasping positions of the objects.