 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePHOTON: Hierarchical Autoregressive Modeling for Lightspeed and Memory-Efficient Language Generation
Dec 22, 2025Transformers operate as horizontal token-by-token scanners; at each generation step, the model attends to an ever-growing sequence of token-level states. This access pattern increases prefill latency and makes long-context decoding increasingly memory-bound, as KV-cache reads and writes dominate inference throughput rather than arithmetic computation. We propose Parallel Hierarchical Operation for Top-down Networks (PHOTON), a hierarchical autoregressive model that replaces flat scanning with vertical, multi-resolution context access. PHOTON maintains a hierarchy of latent streams: a bottom-up encoder progressively compresses tokens into low-rate contextual states, while lightweight top-down decoders reconstruct fine-grained token representations. Experimental results show that PHOTON is superior to competitive Transformer-based language models regarding the throughput-quality trade-off, offering significant advantages in long-context and multi-query tasks. This reduces decode-time KV-cache traffic, yielding up to $10^{3}\times$ higher throughput per unit memory.
A Multi-task Learning Framework for Grasping-Position Detection and Few-Shot Classification
Mar 12, 2020
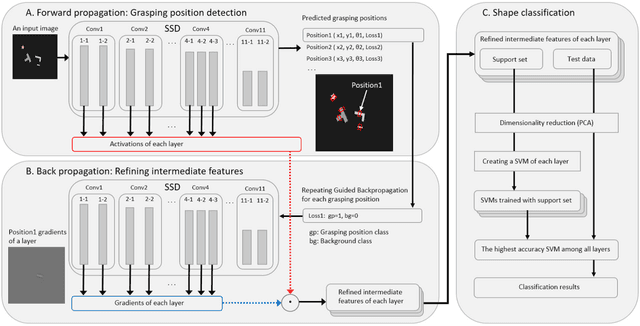
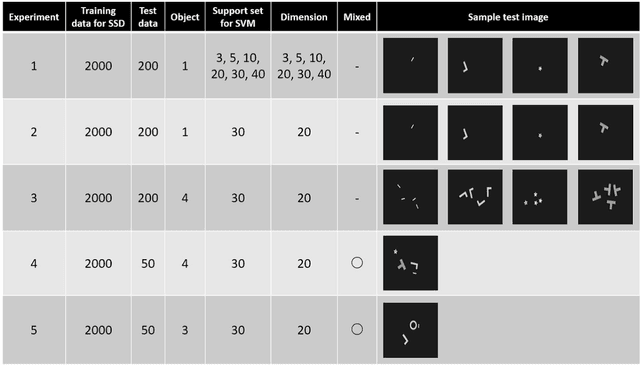

It is a big problem that a model of deep learning for a picking robot needs many labeled images. Operating costs of retraining a model becomes very expensive because the object shape of a product or a part often is changed in a factory. It is important to reduce the amount of labeled images required to train a model for a picking robot. In this study, we propose a multi-task learning framework for few-shot classification using feature vectors from an intermediate layer of a model that detects grasping positions. In the field of manufacturing, multitask for shape classification and grasping-position detection is often required for picking robots. Prior multi-task learning studies include methods to learn one task with feature vectors from a deep neural network (DNN) learned for another task. However, the DNN that was used to detect grasping positions has two problems with respect to extracting feature vectors from a layer for shape classification: (1) Because each layer of the grasping position detection DNN is activated by all objects in the input image, it is necessary to refine the features for each grasping position. (2) It is necessary to select a layer to extract the features suitable for shape classification. To tackle these issues, we propose a method to refine the features for each grasping position and to select features from the optimal layer of the DNN. We then evaluated the shape classification accuracy using these features from the grasping positions. Our results confirm that our proposed framework can classify object shapes even when the input image includes multiple objects and the number of images available for training is small.
Online Self-Supervised Learning for Object Picking: Detecting Optimum Grasping Position using a Metric Learning Approach
Mar 08, 2020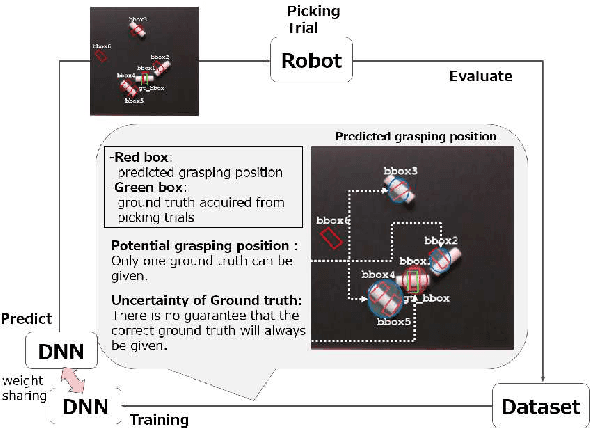
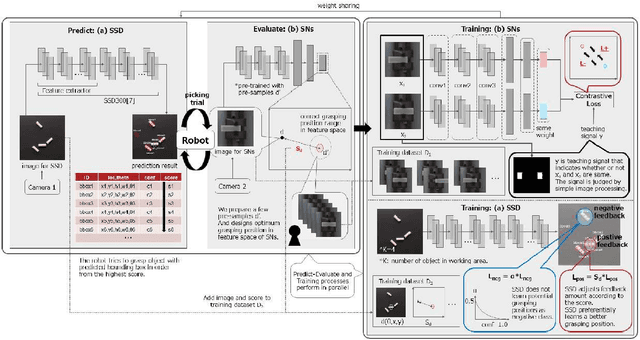
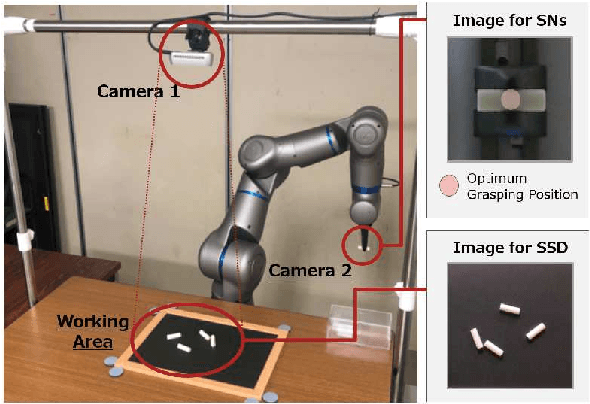
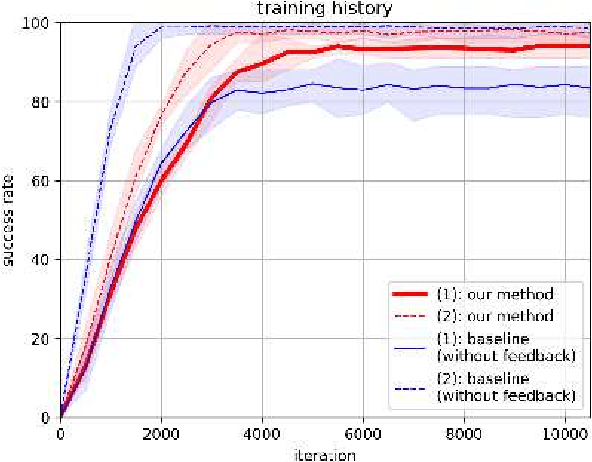
Self-supervised learning methods are attractive candidates for automatic object picking. However, the trial samples lack the complete ground truth because the observable parts of the agent are limited. That is, the information contained in the trial samples is often insufficient to learn the specific grasping position of each object. Consequently, the training falls into a local solution, and the grasp positions learned by the robot are independent of the state of the object. In this study, the optimal grasping position of an individual object is determined from the grasping score, defined as the distance in the feature space obtained using metric learning. The closeness of the solution to the pre-designed optimal grasping position was evaluated in trials. The proposed method incorporates two types of feedback control: one feedback enlarges the grasping score when the grasping position approaches the optimum; the other reduces the negative feedback of the potential grasping positions among the grasping candidates. The proposed online self-supervised learning method employs two deep neural networks. : SSD that detects the grasping position of an object, and Siamese networks (SNs) that evaluate the trial sample using the similarity of two input data in the feature space. Our method embeds the relation of each grasping position as feature vectors by training the trial samples and a few pre-samples indicating the optimum grasping position. By incorporating the grasping score based on the feature space of SNs into the SSD training process, the method preferentially trains the optimum grasping position. In the experiment, the proposed method achieved a higher success rate than the baseline method using simple teaching signals. And the grasping scores in the feature space of the SNs accurately represented the grasping positions of the objects.