 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-jp: A Cross-organizational Project for the Research and Development of Fully Open Japanese LLMs
Jul 04, 2024



This paper introduces LLM-jp, a cross-organizational project for the research and development of Japanese large language models (LLMs). LLM-jp aims to develop open-source and strong Japanese LLMs, and as of this writing, more than 1,500 participants from academia and industry are working together for this purpose. This paper presents the background of the establishment of LLM-jp, summaries of its activities, and technical reports on the LLMs developed by LLM-jp. For the latest activities, visit https://llm-jp.nii.ac.jp/en/.
Inter-domain Multi-relational Link Prediction
Jul 09, 2021
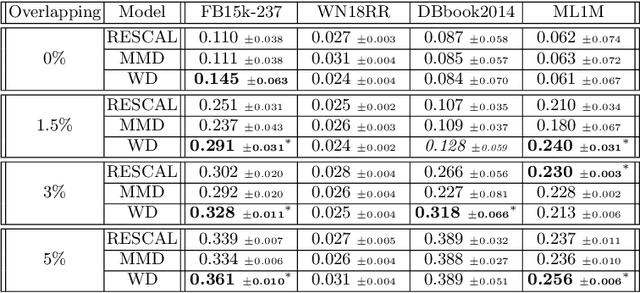
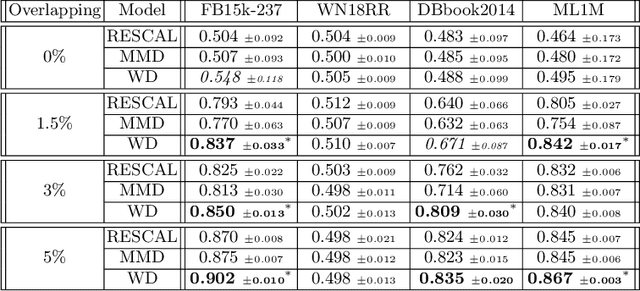
Multi-relational graph is a ubiquitous and important data structure, allowing flexible representation of multiple types of interactions and relations between entities. Similar to other graph-structured data, link prediction is one of the most important tasks on multi-relational graphs and is often used for knowledge completion. When related graphs coexist, it is of great benefit to build a larger graph via integrating the smaller ones. The integration requires predicting hidden relational connections between entities belonged to different graphs (inter-domain link prediction). However, this poses a real challenge to existing methods that are exclusively designed for link prediction between entities of the same graph only (intra-domain link prediction). In this study, we propose a new approach to tackle the inter-domain link prediction problem by softly aligning the entity distributions between different domains with optimal transport and maximum mean discrepancy regularizers. Experiments on real-world datasets show that optimal transport regularizer is beneficial and considerably improves the performance of baseline methods.
Crowdsourcing Evaluation of Saliency-based XAI Methods
Jun 27, 2021
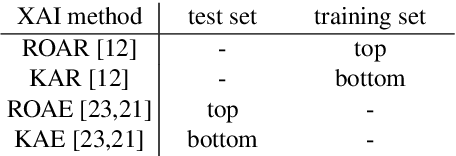
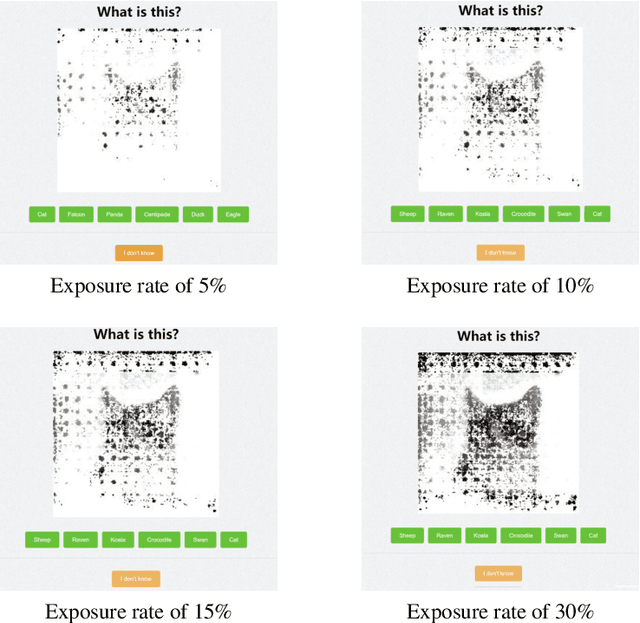

Understanding the reasons behind the predictions made by deep neural networks is critical for gaining human trust in many important applications, which is reflected in the increasing demand for explainability in AI (XAI) in recent years. Saliency-based feature attribution methods, which highlight important parts of images that contribute to decisions by classifiers, are often used as XAI methods, especially in the field of computer vision. In order to compare various saliency-based XAI methods quantitatively, several approaches for automated evaluation schemes have been proposed; however, there is no guarantee that such automated evaluation metrics correctly evaluate explainability, and a high rating by an automated evaluation scheme does not necessarily mean a high explainability for humans. In this study, instead of the automated evaluation, we propose a new human-based evaluation scheme using crowdsourcing to evaluate XAI methods. Our method is inspired by a human computation game, "Peek-a-boom", and can efficiently compare different XAI methods by exploiting the power of crowds. We evaluate the saliency maps of various XAI methods on two datasets with automated and crowd-based evaluation schemes. Our experiments show that the result of our crowd-based evaluation scheme is different from those of automated evaluation schemes. In addition, we regard the crowd-based evaluation results as ground truths and provide a quantitative performance measure to compare different automated evaluation schemes. We also discuss the impact of crowd workers on the results and show that the varying ability of crowd workers does not significantly impact the results.
Bermuda Triangles: GNNs Fail to Detect Simple Topological Structures
May 01, 2021

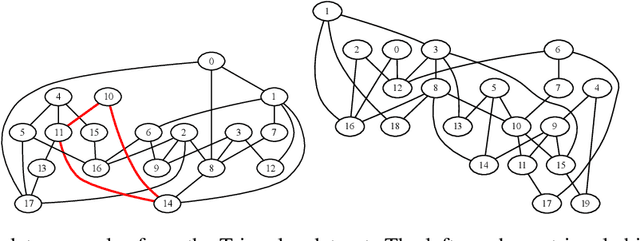

Most graph neural network architectures work by message-passing node vector embeddings over the adjacency matrix, and it is assumed that they capture graph topology by doing that. We design two synthetic tasks, focusing purely on topological problems -- triangle detection and clique distance -- on which graph neural networks perform surprisingly badly, failing to detect those "bermuda" triangles. Datasets and their generation scripts are publicly available on github.com/FujitsuLaboratories/bermudatriangles and dataset.labs.fujitsu.com.