 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Lives in Sparse Dimensions: Toward Interpretable and Efficient Multilingual Control for Large Language Models
Oct 08, 2025Large language models exhibit strong multilingual capabilities despite limited exposure to non-English data. Prior studies show that English-centric large language models map multilingual content into English-aligned representations at intermediate layers and then project them back into target-language token spaces in the final layer. From this observation, we hypothesize that this cross-lingual transition is governed by a small and sparse set of dimensions, which occur at consistent indices across the intermediate to final layers. Building on this insight, we introduce a simple, training-free method to identify and manipulate these dimensions, requiring only as few as 50 sentences of either parallel or monolingual data. Experiments on a multilingual generation control task reveal the interpretability of these dimensions, demonstrating that the interventions in these dimensions can switch the output language while preserving semantic content, and that it surpasses the performance of prior neuron-based approaches at a substantially lower cost.
Boosting Illuminant Estimation in Deep Color Constancy through Enhancing Brightness Robustness
Feb 18, 2025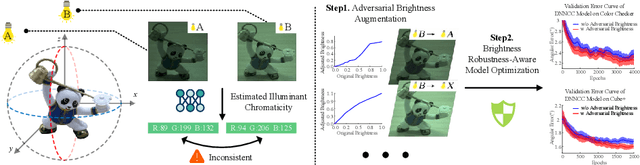
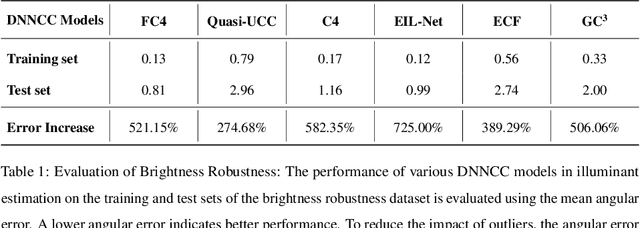

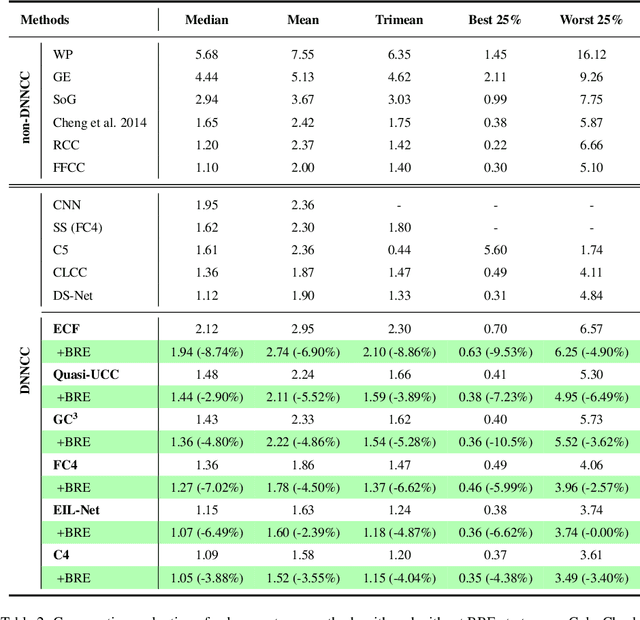
Color constancy estimates illuminant chromaticity to correct color-biased images. Recently, Deep Neural Network-driven Color Constancy (DNNCC) models have made substantial advancements. Nevertheless, the potential risks in DNNCC due to the vulnerability of deep neural networks have not yet been explored. In this paper, we conduct the first investigation into the impact of a key factor in color constancy-brightness-on DNNCC from a robustness perspective. Our evaluation reveals that several mainstream DNNCC models exhibit high sensitivity to brightness despite their focus on chromaticity estimation. This sheds light on a potential limitation of existing DNNCC models: their sensitivity to brightness may hinder performance given the widespread brightness variations in real-world datasets. From the insights of our analysis, we propose a simple yet effective brightness robustness enhancement strategy for DNNCC models, termed BRE. The core of BRE is built upon the adaptive step-size adversarial brightness augmentation technique, which identifies high-risk brightness variation and generates augmented images via explicit brightness adjustment. Subsequently, BRE develops a brightness-robustness-aware model optimization strategy that integrates adversarial brightness training and brightness contrastive loss, significantly bolstering the brightness robustness of DNNCC models. BRE is hyperparameter-free and can be integrated into existing DNNCC models, without incurring additional overhead during the testing phase. Experiments on two public color constancy datasets-ColorChecker and Cube+-demonstrate that the proposed BRE consistently enhances the illuminant estimation performance of existing DNNCC models, reducing the estimation error by an average of 5.04% across six mainstream DNNCC models, underscoring the critical role of enhancing brightness robustness in these models.
Beyond English-Centric LLMs: What Language Do Multilingual Language Models Think in?
Aug 20, 2024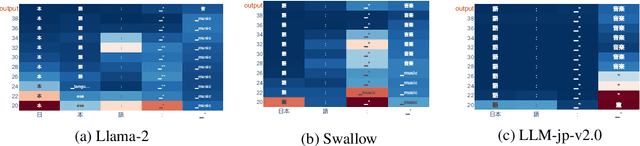

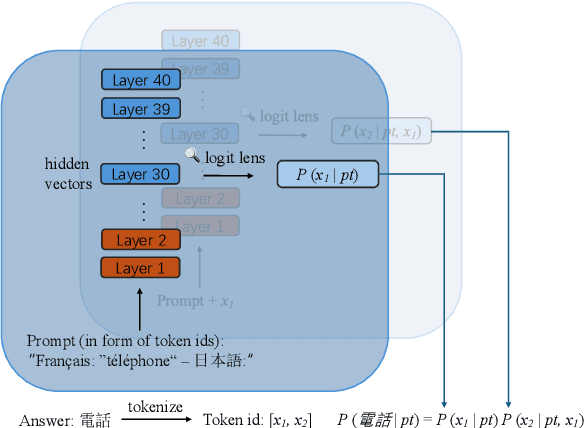
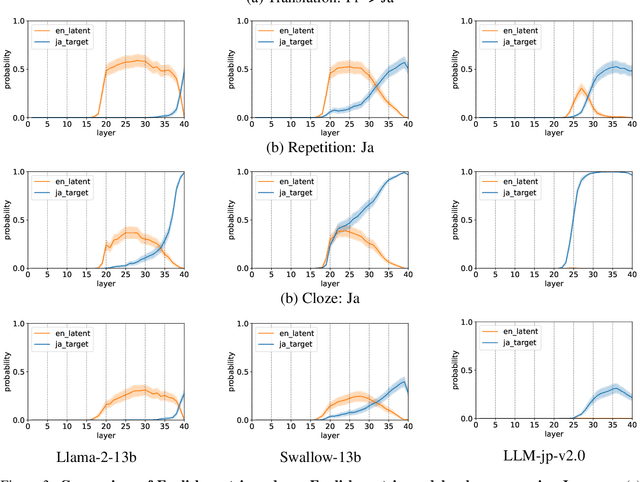
In this study, we investigate whether non-English-centric LLMs, despite their strong performance, `think' in their respective dominant language: more precisely, `think' refers to how the representations of intermediate layers, when un-embedded into the vocabulary space, exhibit higher probabilities for certain dominant languages during generation. We term such languages as internal $\textbf{latent languages}$. We examine the latent language of three typical categories of models for Japanese processing: Llama2, an English-centric model; Swallow, an English-centric model with continued pre-training in Japanese; and LLM-jp, a model pre-trained on balanced English and Japanese corpora. Our empirical findings reveal that, unlike Llama2 which relies exclusively on English as the internal latent language, Japanese-specific Swallow and LLM-jp employ both Japanese and English, exhibiting dual internal latent languages. For any given target language, the model preferentially activates the latent language most closely related to it. In addition, we explore how intermediate layers respond to questions involving cultural conflicts between latent internal and target output languages. We further explore how the language identity shifts across layers while keeping consistent semantic meaning reflected in the intermediate layer representations. This study deepens the understanding of non-English-centric large language models, highlighting the intricate dynamics of language representation within their intermediate layers.