 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAReT: Cross-view Video Geolocalization with Adapters and Auto-Regressive Transformers
Paper and Code
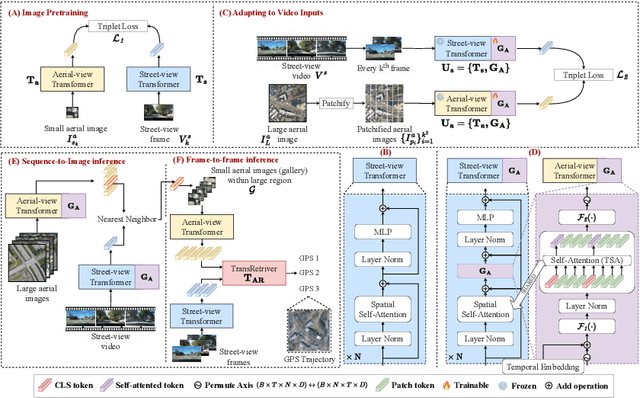
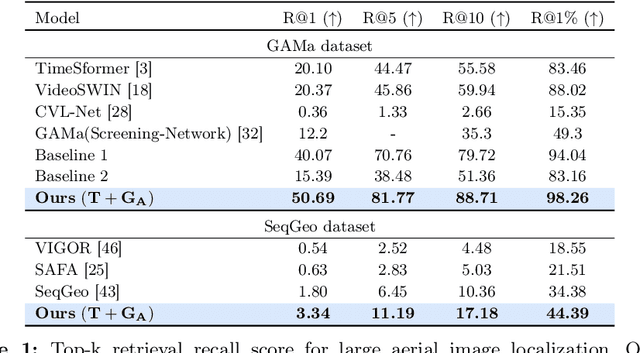
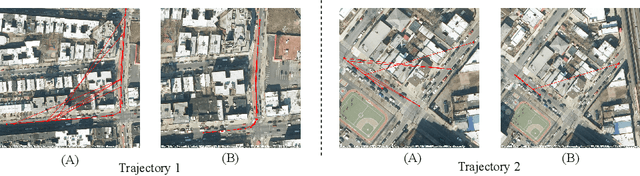
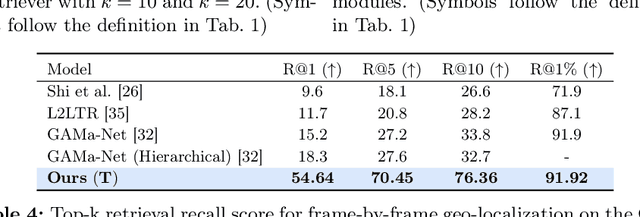
Cross-view video geo-localization (CVGL) aims to derive GPS trajectories from street-view videos by aligning them with aerial-view images. Despite their promising performance, current CVGL methods face significant challenges. These methods use camera and odometry data, typically absent in real-world scenarios. They utilize multiple adjacent frames and various encoders for feature extraction, resulting in high computational costs. Moreover, these approaches independently predict each street-view frame's location, resulting in temporally inconsistent GPS trajectories. To address these challenges, in this work, we propose GAReT, a fully transformer-based method for CVGL that does not require camera and odometry data. We introduce GeoAdapter, a transformer-adapter module designed to efficiently aggregate image-level representations and adapt them for video inputs. Specifically, we train a transformer encoder on video frames and aerial images, then freeze the encoder to optimize the GeoAdapter module to obtain video-level representation. To address temporally inconsistent trajectories, we introduce TransRetriever, an encoder-decoder transformer model that predicts GPS locations of street-view frames by encoding top-k nearest neighbor predictions per frame and auto-regressively decoding the best neighbor based on the previous frame's predictions. Our method's effectiveness is validated through extensive experiments, demonstrating state-of-the-art performance on benchmark datasets. Our code is available at https://github.com/manupillai308/GAReT.