 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemperature Scaling Attack Disrupting Model Confidence in Federated Learning
Feb 09, 2026Predictive confidence serves as a foundational control signal in mission-critical systems, directly governing risk-aware logic such as escalation, abstention, and conservative fallback. While prior federated learning attacks predominantly target accuracy or implant backdoors, we identify confidence calibration as a distinct attack objective. We present the Temperature Scaling Attack (TSA), a training-time attack that degrades calibration while preserving accuracy. By injecting temperature scaling with learning rate-temperature coupling during local training, malicious updates maintain benign-like optimization behavior, evading accuracy-based monitoring and similarity-based detection. We provide a convergence analysis under non-IID settings, showing that this coupling preserves standard convergence bounds while systematically distorting confidence. Across three benchmarks, TSA substantially shifts calibration (e.g., 145% error increase on CIFAR-100) with <2 accuracy change, and remains effective under robust aggregation and post-hoc calibration defenses. Case studies further show that confidence manipulation can cause up to 7.2x increases in missed critical cases (healthcare) or false alarms (autonomous driving), even when accuracy is unchanged. Overall, our results establish calibration integrity as a critical attack surface in federated learning.
Symbol Distributions in Semantic Communications: A Source-Channel Equilibrium Perspective
Dec 16, 2025Semantic communication systems often use an end-to-end neural network to map input data into continuous symbols. These symbols, which are essentially neural network features, usually have fixed dimensions and heavy-tailed distributions. However, due to the end-to-end training nature of the neural network encoder, the underlying reason for the symbol distribution remains underexplored. We propose a new explanation for the semantic symbol distribution: an inherent trade-off between source coding and communications. Specifically, the encoder balances two objectives: allocating power for minimum \emph{effective codelength} (for source coding) and maximizing mutual information (for communications). We formalize this trade-off via an information-theoretic optimization framework, which yields a Student's $t$-distribution as the resulting symbol distribution. Through extensive studies on image-based semantic systems, we find that our formulation models the learned symbols and predicts how the symbol distribution's shape parameter changes with respect to (i) the use of variable-length coding and (ii) the dataset's entropy variability. Furthermore, we demonstrate how introducing a regularizer that enforces a target symbol distribution, which guides the encoder towards a target prior (e.g., Gaussian), improves training convergence and supports our hypothesis.
Bridging Neural Networks and Wireless Systems with MIMO-OFDM Semantic Communications
Jan 28, 2025



Semantic communications aim to enhance transmission efficiency by jointly optimizing source coding, channel coding, and modulation. While prior research has demonstrated promising performance in simulations, real-world implementations often face significant challenges, including noise variability and nonlinear distortions, leading to performance gaps. This article investigates these challenges in a multiple-input multiple-output (MIMO) and orthogonal frequency division multiplexing (OFDM)-based semantic communication system, focusing on the practical impacts of power amplifier (PA) nonlinearity and peak-to-average power ratio (PAPR) variations. Our analysis identifies frequency selectivity of the actual channel as a critical factor in performance degradation and demonstrates that targeted mitigation strategies can enable semantic systems to approach theoretical performance. By addressing key limitations in existing designs, we provide actionable insights for advancing semantic communications in practical wireless environments. This work establishes a foundation for bridging the gap between theoretical models and real-world deployment, highlighting essential considerations for system design and optimization.
FLex&Chill: Improving Local Federated Learning Training with Logit Chilling
Jan 18, 2024



Federated learning are inherently hampered by data heterogeneity: non-iid distributed training data over local clients. We propose a novel model training approach for federated learning, FLex&Chill, which exploits the Logit Chilling method. Through extensive evaluations, we demonstrate that, in the presence of non-iid data characteristics inherent in federated learning systems, this approach can expedite model convergence and improve inference accuracy. Quantitatively, from our experiments, we observe up to 6X improvement in the global federated learning model convergence time, and up to 3.37% improvement in inference accuracy.
On the Role of ViT and CNN in Semantic Communications: Analysis and Prototype Validation
Jun 05, 2023



Semantic communications have shown promising advancements by optimizing source and channel coding jointly. However, the dynamics of these systems remain understudied, limiting research and performance gains. Inspired by the robustness of Vision Transformers (ViTs) in handling image nuisances, we propose a ViT-based model for semantic communications. Our approach achieves a peak signal-to-noise ratio (PSNR) gain of +0.5 dB over convolutional neural network variants. We introduce novel measures, average cosine similarity and Fourier analysis, to analyze the inner workings of semantic communications and optimize the system's performance. We also validate our approach through a real wireless channel prototype using software-defined radio (SDR). To the best of our knowledge, this is the first investigation of the fundamental workings of a semantic communications system, accompanied by the pioneering hardware implementation. To facilitate reproducibility and encourage further research, we provide open-source code, including neural network implementations and LabVIEW codes for SDR-based wireless transmission systems.
Curved Representation Space of Vision Transformers
Oct 11, 2022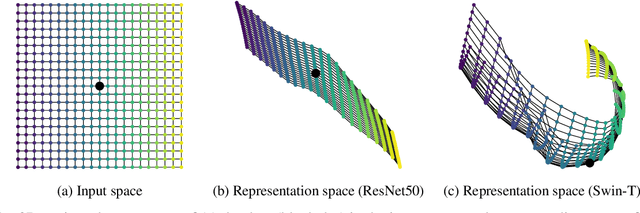
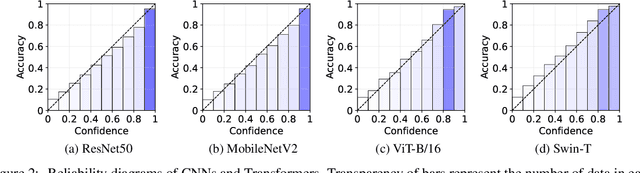
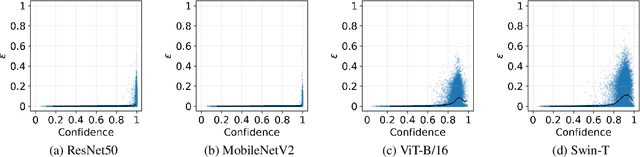
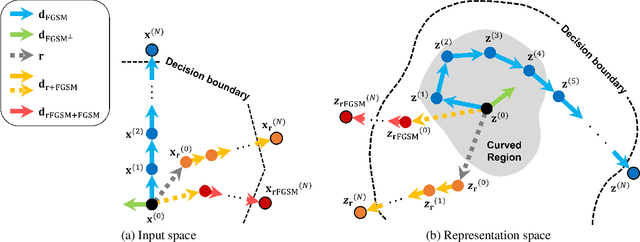
Neural networks with self-attention (a.k.a. Transformers) like ViT and Swin have emerged as a better alternative to traditional convolutional neural networks (CNNs) for computer vision tasks. However, our understanding of how the new architecture works is still limited. In this paper, we focus on the phenomenon that Transformers show higher robustness against corruptions than CNNs, while not being overconfident (in fact, we find Transformers are actually underconfident). This is contrary to the intuition that robustness increases with confidence. We resolve this contradiction by investigating how the output of the penultimate layer moves in the representation space as the input data moves within a small area. In particular, we show the following. (1) While CNNs exhibit fairly linear relationship between the input and output movements, Transformers show nonlinear relationship for some data. For those data, the output of Transformers moves in a curved trajectory as the input moves linearly. (2) When a data is located in a curved region, it is hard to move it out of the decision region since the output moves along a curved trajectory instead of a straight line to the decision boundary, resulting in high robustness of Transformers. (3) If a data is slightly modified to jump out of the curved region, the movements afterwards become linear and the output goes to the decision boundary directly. Thus, Transformers can be attacked easily after a small random jump and the perturbation in the final attacked data remains imperceptible, i.e., there does exist a decision boundary near the data. This also explains the underconfident prediction of Transformers. (4) The curved regions in the representation space start to form at an early training stage and grow throughout the training course. Some data are trapped in the regions, obstructing Transformers from reducing the training loss.
Demo: Real-Time Semantic Communications with a Vision Transformer
May 08, 2022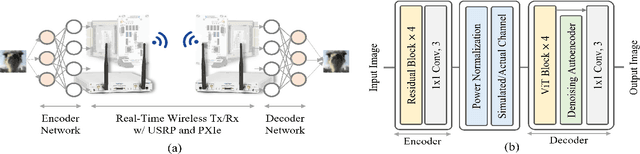
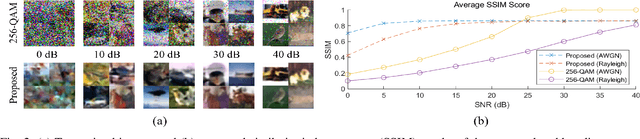
Semantic communications are expected to enable the more effective delivery of meaning rather than a precise transfer of symbols. In this paper, we propose an end-to-end deep neural network-based architecture for image transmission and demonstrate its feasibility in a real-time wireless channel by implementing a prototype based on a field-programmable gate array (FPGA). We demonstrate that this system outperforms the traditional 256-quadrature amplitude modulation system in the low signal-to-noise ratio regime with the popular CIFAR-10 dataset. To the best of our knowledge, this is the first work that implements and investigates real-time semantic communications with a vision transformer.
How Do Vision Transformers Work?
Feb 27, 2022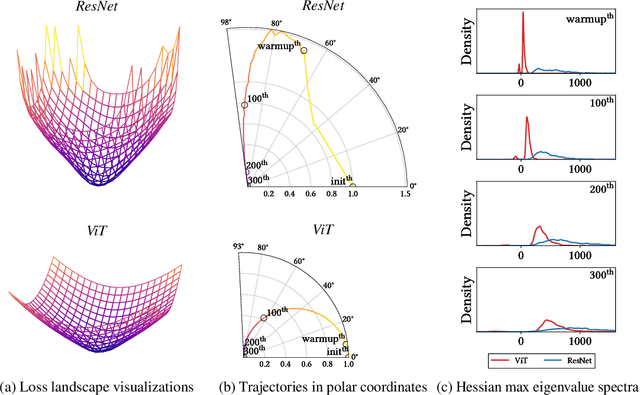
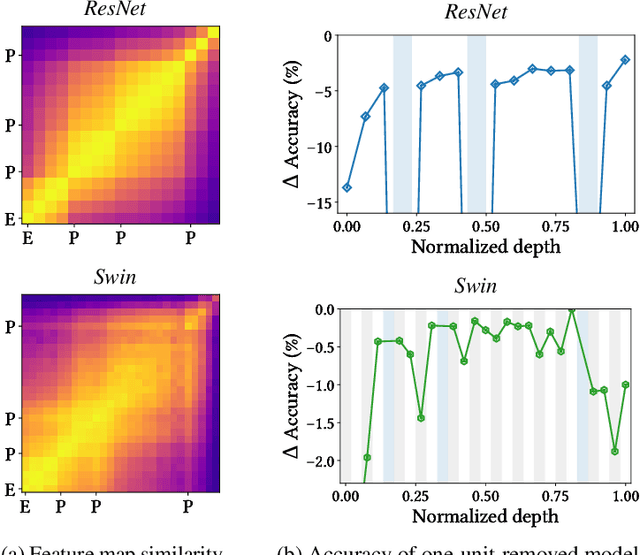


The success of multi-head self-attentions (MSAs) for computer vision is now indisputable. However, little is known about how MSAs work. We present fundamental explanations to help better understand the nature of MSAs. In particular, we demonstrate the following properties of MSAs and Vision Transformers (ViTs): (1) MSAs improve not only accuracy but also generalization by flattening the loss landscapes. Such improvement is primarily attributable to their data specificity, not long-range dependency. On the other hand, ViTs suffer from non-convex losses. Large datasets and loss landscape smoothing methods alleviate this problem; (2) MSAs and Convs exhibit opposite behaviors. For example, MSAs are low-pass filters, but Convs are high-pass filters. Therefore, MSAs and Convs are complementary; (3) Multi-stage neural networks behave like a series connection of small individual models. In addition, MSAs at the end of a stage play a key role in prediction. Based on these insights, we propose AlterNet, a model in which Conv blocks at the end of a stage are replaced with MSA blocks. AlterNet outperforms CNNs not only in large data regimes but also in small data regimes. The code is available at https://github.com/xxxnell/how-do-vits-work.
Blurs Make Results Clearer: Spatial Smoothings to Improve Accuracy, Uncertainty, and Robustness
May 26, 2021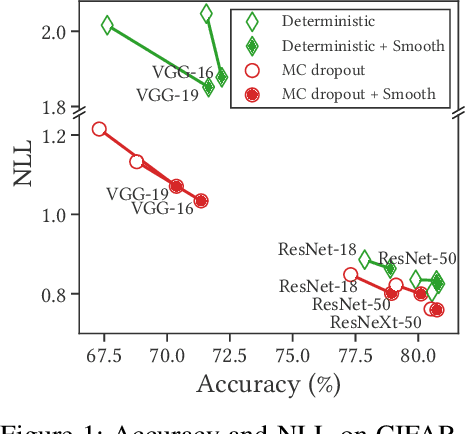
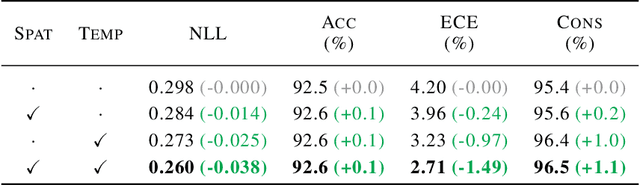
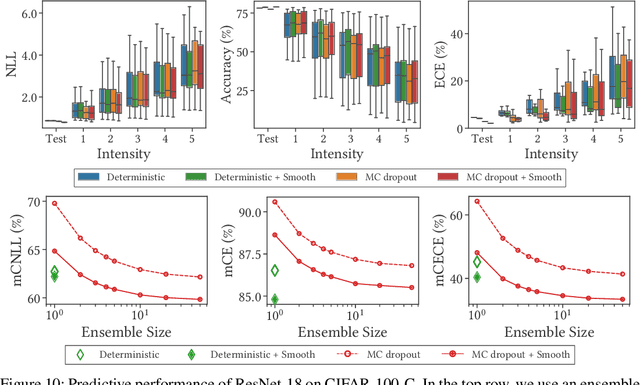
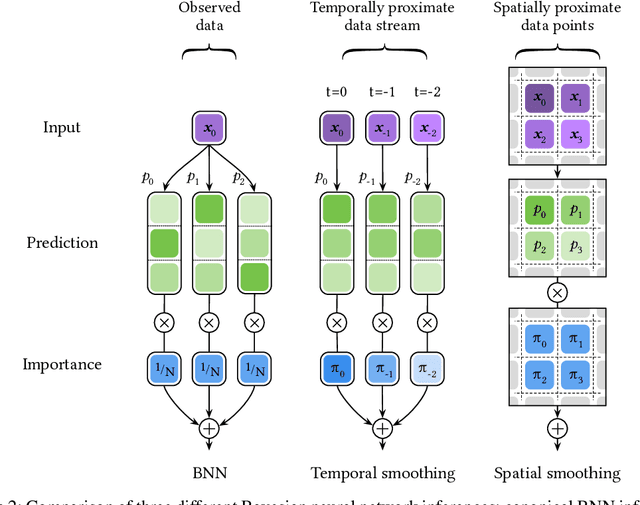
Bayesian neural networks (BNNs) have shown success in the areas of uncertainty estimation and robustness. However, a crucial challenge prohibits their use in practice: Bayesian NNs require a large number of predictions to produce reliable results, leading to a significant increase in computational cost. To alleviate this issue, we propose spatial smoothing, a method that ensembles neighboring feature map points of CNNs. By simply adding a few blur layers to the models, we empirically show that the spatial smoothing improves accuracy, uncertainty estimation, and robustness of BNNs across a whole range of ensemble sizes. In particular, BNNs incorporating the spatial smoothing achieve high predictive performance merely with a handful of ensembles. Moreover, this method also can be applied to canonical deterministic neural networks to improve the performances. A number of evidences suggest that the improvements can be attributed to the smoothing and flattening of the loss landscape. In addition, we provide a fundamental explanation for prior works - namely, global average pooling, pre-activation, and ReLU6 - by addressing to them as special cases of the spatial smoothing. These not only enhance accuracy, but also improve uncertainty estimation and robustness by making the loss landscape smoother in the same manner as the spatial smoothing. The code is available at https://github.com/xxxnell/spatial-smoothing.
Differentiable Bayesian Neural Network Inference for Data Streams
Jul 12, 2019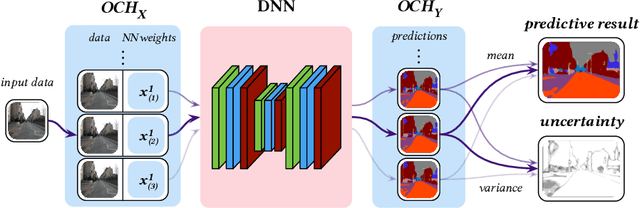
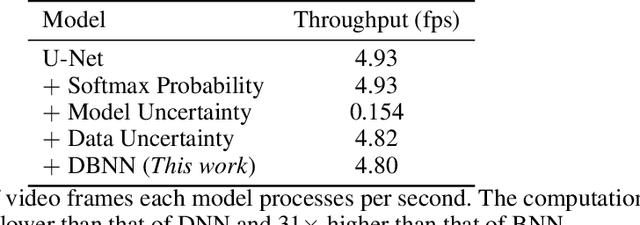
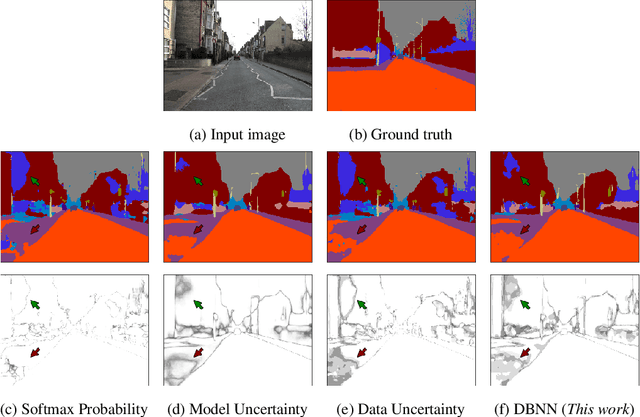
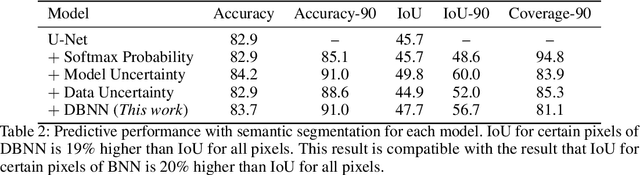
While deep neural networks (NNs) do not provide the confidence of its prediction, Bayesian neural network (BNN) can estimate the uncertainty of the prediction. However, BNNs have not been widely used in practice due to the computational cost of inference. This prohibitive computational cost is a hindrance especially when processing stream data with low-latency. To address this problem, we propose a novel model which approximate BNNs for data streams. Instead of generating separate prediction for each data sample independently, this model estimates the increments of prediction for a new data sample from the previous predictions. The computational cost of this model is almost the same as that of non-Bayesian NNs. Experiments with semantic segmentation on real-world data show that this model performs significantly faster than BNNs, estimating uncertainty comparable to the results of BNNs.