 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymbol Distributions in Semantic Communications: A Source-Channel Equilibrium Perspective
Dec 16, 2025Semantic communication systems often use an end-to-end neural network to map input data into continuous symbols. These symbols, which are essentially neural network features, usually have fixed dimensions and heavy-tailed distributions. However, due to the end-to-end training nature of the neural network encoder, the underlying reason for the symbol distribution remains underexplored. We propose a new explanation for the semantic symbol distribution: an inherent trade-off between source coding and communications. Specifically, the encoder balances two objectives: allocating power for minimum \emph{effective codelength} (for source coding) and maximizing mutual information (for communications). We formalize this trade-off via an information-theoretic optimization framework, which yields a Student's $t$-distribution as the resulting symbol distribution. Through extensive studies on image-based semantic systems, we find that our formulation models the learned symbols and predicts how the symbol distribution's shape parameter changes with respect to (i) the use of variable-length coding and (ii) the dataset's entropy variability. Furthermore, we demonstrate how introducing a regularizer that enforces a target symbol distribution, which guides the encoder towards a target prior (e.g., Gaussian), improves training convergence and supports our hypothesis.
MoCoRP: Modeling Consistent Relations between Persona and Response for Persona-based Dialogue
Dec 08, 2025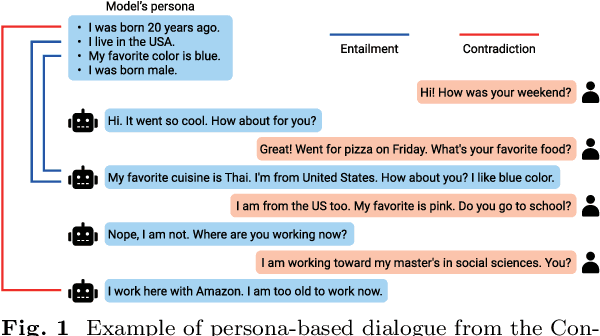



As dialogue systems become increasingly important across various domains, a key challenge in persona-based dialogue is generating engaging and context-specific interactions while ensuring the model acts with a coherent personality. However, existing persona-based dialogue datasets lack explicit relations between persona sentences and responses, which makes it difficult for models to effectively capture persona information. To address these issues, we propose MoCoRP (Modeling Consistent Relations between Persona and Response), a framework that incorporates explicit relations into language models. MoCoRP leverages an NLI expert to explicitly extract the NLI relations between persona sentences and responses, enabling the model to effectively incorporate appropriate persona information from the context into its responses. We applied this framework to pre-trained models like BART and further extended it to modern large language models (LLMs) through alignment tuning. Experimental results on the public datasets ConvAI2 and MPChat demonstrate that MoCoRP outperforms existing baselines, achieving superior persona consistency and engaging, context-aware dialogue generation. Furthermore, our model not only excels in quantitative metrics but also shows significant improvements in qualitative aspects. These results highlight the effectiveness of explicitly modeling persona-response relations in persona-based dialogue. The source codes of MoCoRP are available at https://github.com/DMCB-GIST/MoCoRP.
Bridging Neural Networks and Wireless Systems with MIMO-OFDM Semantic Communications
Jan 28, 2025Semantic communications aim to enhance transmission efficiency by jointly optimizing source coding, channel coding, and modulation. While prior research has demonstrated promising performance in simulations, real-world implementations often face significant challenges, including noise variability and nonlinear distortions, leading to performance gaps. This article investigates these challenges in a multiple-input multiple-output (MIMO) and orthogonal frequency division multiplexing (OFDM)-based semantic communication system, focusing on the practical impacts of power amplifier (PA) nonlinearity and peak-to-average power ratio (PAPR) variations. Our analysis identifies frequency selectivity of the actual channel as a critical factor in performance degradation and demonstrates that targeted mitigation strategies can enable semantic systems to approach theoretical performance. By addressing key limitations in existing designs, we provide actionable insights for advancing semantic communications in practical wireless environments. This work establishes a foundation for bridging the gap between theoretical models and real-world deployment, highlighting essential considerations for system design and optimization.
Extracting Chemical-Protein Interactions via Calibrated Deep Neural Network and Self-training
Nov 04, 2020
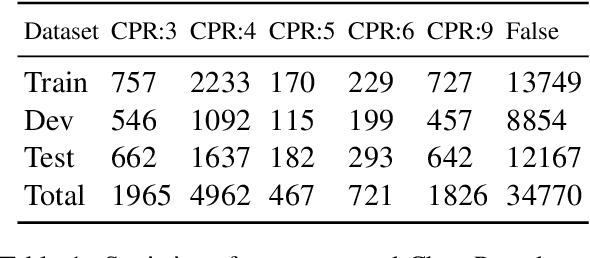
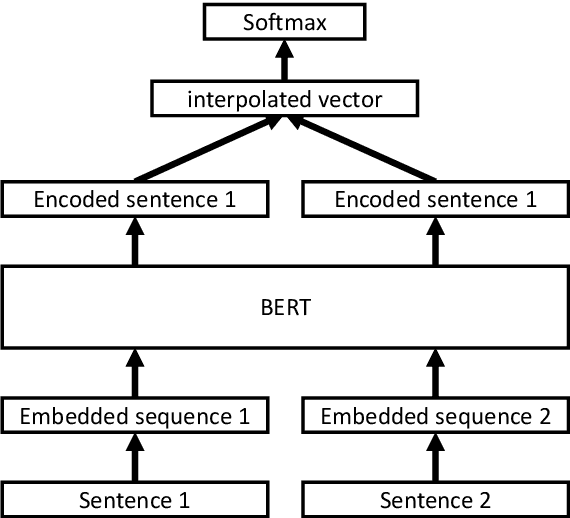
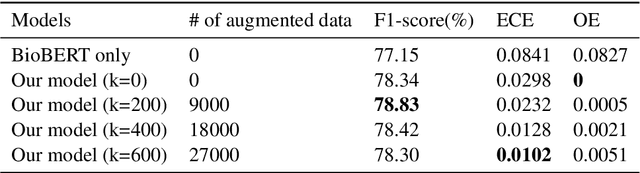
The extraction of interactions between chemicals and proteins from several biomedical articles is important in many fields of biomedical research such as drug development and prediction of drug side effects. Several natural language processing methods, including deep neural network (DNN) models, have been applied to address this problem. However, these methods were trained with hard-labeled data, which tend to become over-confident, leading to degradation of the model reliability. To estimate the data uncertainty and improve the reliability, "calibration" techniques have been applied to deep learning models. In this study, to extract chemical--protein interactions, we propose a DNN-based approach incorporating uncertainty information and calibration techniques. Our model first encodes the input sequence using a pre-trained language-understanding model, following which it is trained using two calibration methods: mixup training and addition of a confidence penalty loss. Finally, the model is re-trained with augmented data that are extracted using the estimated uncertainties. Our approach has achieved state-of-the-art performance with regard to the Biocreative VI ChemProt task, while preserving higher calibration abilities than those of previous approaches. Furthermore, our approach also presents the possibilities of using uncertainty estimation for performance improvement.