 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTazza: Shuffling Neural Network Parameters for Secure and Private Federated Learning
Dec 10, 2024



Federated learning enables decentralized model training without sharing raw data, preserving data privacy. However, its vulnerability towards critical security threats, such as gradient inversion and model poisoning by malicious clients, remain unresolved. Existing solutions often address these issues separately, sacrificing either system robustness or model accuracy. This work introduces Tazza, a secure and efficient federated learning framework that simultaneously addresses both challenges. By leveraging the permutation equivariance and invariance properties of neural networks via weight shuffling and shuffled model validation, Tazza enhances resilience against diverse poisoning attacks, while ensuring data confidentiality and high model accuracy. Comprehensive evaluations on various datasets and embedded platforms show that Tazza achieves robust defense with up to 6.7x improved computational efficiency compared to alternative schemes, without compromising performance.
DeTrigger: A Gradient-Centric Approach to Backdoor Attack Mitigation in Federated Learning
Nov 19, 2024



Federated Learning (FL) enables collaborative model training across distributed devices while preserving local data privacy, making it ideal for mobile and embedded systems. However, the decentralized nature of FL also opens vulnerabilities to model poisoning attacks, particularly backdoor attacks, where adversaries implant trigger patterns to manipulate model predictions. In this paper, we propose DeTrigger, a scalable and efficient backdoor-robust federated learning framework that leverages insights from adversarial attack methodologies. By employing gradient analysis with temperature scaling, DeTrigger detects and isolates backdoor triggers, allowing for precise model weight pruning of backdoor activations without sacrificing benign model knowledge. Extensive evaluations across four widely used datasets demonstrate that DeTrigger achieves up to 251x faster detection than traditional methods and mitigates backdoor attacks by up to 98.9%, with minimal impact on global model accuracy. Our findings establish DeTrigger as a robust and scalable solution to protect federated learning environments against sophisticated backdoor threats.
Effective Heterogeneous Federated Learning via Efficient Hypernetwork-based Weight Generation
Jul 03, 2024While federated learning leverages distributed client resources, it faces challenges due to heterogeneous client capabilities. This necessitates allocating models suited to clients' resources and careful parameter aggregation to accommodate this heterogeneity. We propose HypeMeFed, a novel federated learning framework for supporting client heterogeneity by combining a multi-exit network architecture with hypernetwork-based model weight generation. This approach aligns the feature spaces of heterogeneous model layers and resolves per-layer information disparity during weight aggregation. To practically realize HypeMeFed, we also propose a low-rank factorization approach to minimize computation and memory overhead associated with hypernetworks. Our evaluations on a real-world heterogeneous device testbed indicate that HypeMeFed enhances accuracy by 5.12% over FedAvg, reduces the hypernetwork memory requirements by 98.22%, and accelerates its operations by 1.86 times compared to a naive hypernetwork approach. These results demonstrate HypeMeFed's effectiveness in leveraging and engaging heterogeneous clients for federated learning.
FLex&Chill: Improving Local Federated Learning Training with Logit Chilling
Jan 18, 2024



Federated learning are inherently hampered by data heterogeneity: non-iid distributed training data over local clients. We propose a novel model training approach for federated learning, FLex&Chill, which exploits the Logit Chilling method. Through extensive evaluations, we demonstrate that, in the presence of non-iid data characteristics inherent in federated learning systems, this approach can expedite model convergence and improve inference accuracy. Quantitatively, from our experiments, we observe up to 6X improvement in the global federated learning model convergence time, and up to 3.37% improvement in inference accuracy.
FedAIoT: A Federated Learning Benchmark for Artificial Intelligence of Things
Sep 29, 2023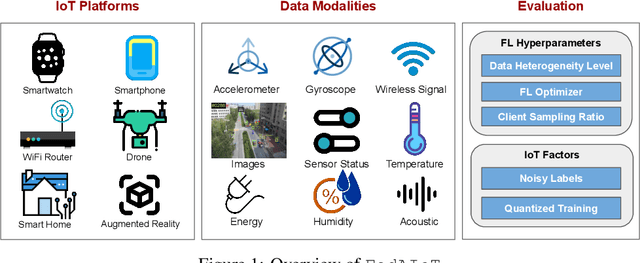

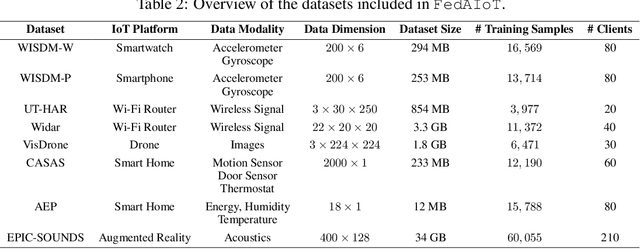
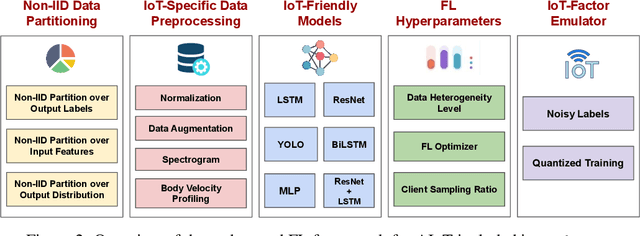
There is a significant relevance of federated learning (FL) in the realm of Artificial Intelligence of Things (AIoT). However, most existing FL works are not conducted on datasets collected from authentic IoT devices that capture unique modalities and inherent challenges of IoT data. In this work, we introduce FedAIoT, an FL benchmark for AIoT to fill this critical gap. FedAIoT includes eight datatsets collected from a wide range of IoT devices. These datasets cover unique IoT modalities and target representative applications of AIoT. FedAIoT also includes a unified end-to-end FL framework for AIoT that simplifies benchmarking the performance of the datasets. Our benchmark results shed light on the opportunities and challenges of FL for AIoT. We hope FedAIoT could serve as an invaluable resource to foster advancements in the important field of FL for AIoT. The repository of FedAIoT is maintained at https://github.com/AIoT-MLSys-Lab/FedAIoT.
On-device Training: A First Overview on Existing Systems
Dec 01, 2022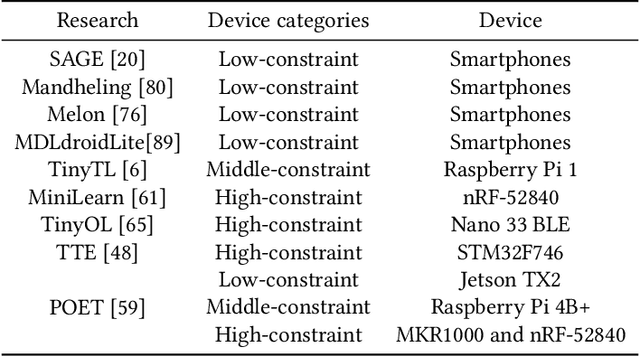
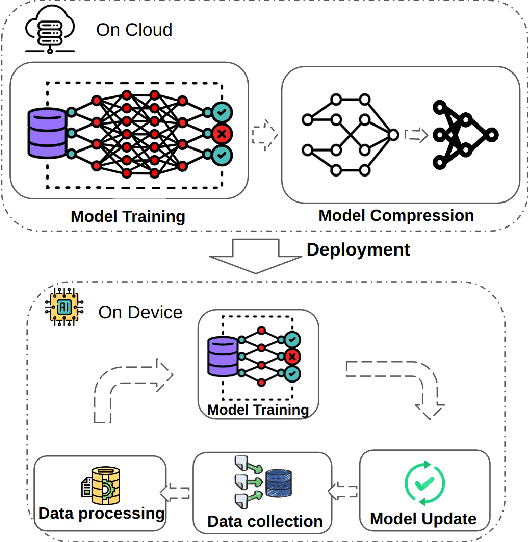
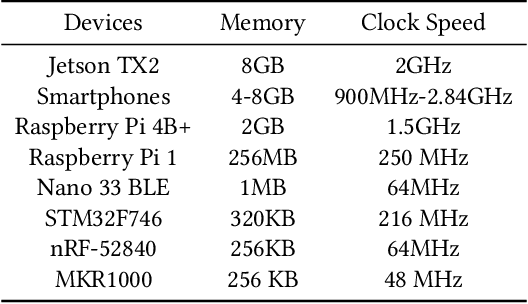

The recent breakthroughs in machine learning (ML) and deep learning (DL) have enabled many new capabilities across plenty of application domains. While most existing machine learning models require large memory and computing power, efforts have been made to deploy some models on resource-constrained devices as well. There are several systems that perform inference on the device, while direct training on the device still remains a challenge. On-device training, however, is attracting more and more interest because: (1) it enables training models on local data without needing to share data over the cloud, thus enabling privacy preserving computation by design; (2) models can be refined on devices to provide personalized services and cope with model drift in order to adapt to the changes of the real-world environment; and (3) it enables the deployment of models in remote, hardly accessible locations or places without stable internet connectivity. We summarize and analyze the-state-of-art systems research to provide the first survey of on-device training from a systems perspective.
Fast Monte-Carlo Approximation of the Attention Mechanism
Jan 30, 2022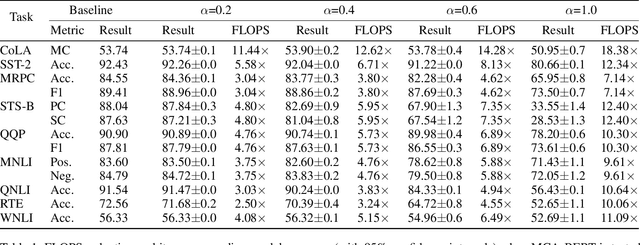
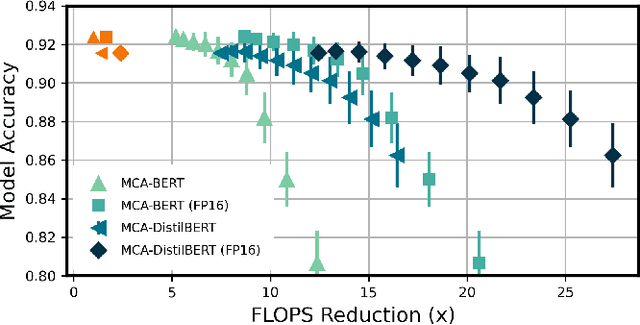
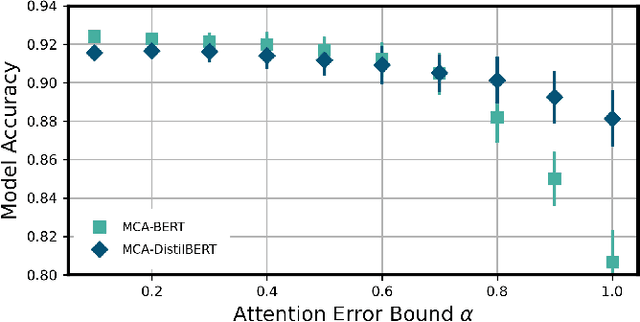
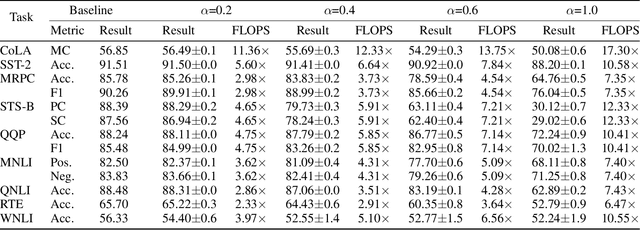
We introduce Monte-Carlo Attention (MCA), a randomized approximation method for reducing the computational cost of self-attention mechanisms in Transformer architectures. MCA exploits the fact that the importance of each token in an input sequence varies with respect to their attention scores; thus, some degree of error can be tolerable when encoding tokens with low attention. Using approximate matrix multiplication, MCA applies different error bounds to encode input tokens such that those with low attention scores are computed with relaxed precision, whereas errors of salient elements are minimized. MCA can operate in parallel with other attention optimization schemes and does not require model modification. We study the theoretical error bounds and demonstrate that MCA reduces attention complexity (in FLOPS) for various Transformer models by up to 11$\times$ in GLUE benchmarks without compromising model accuracy.