 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotif-2-12.7B-Reasoning: A Practitioner's Guide to RL Training Recipes
Dec 11, 2025We introduce Motif-2-12.7B-Reasoning, a 12.7B parameter language model designed to bridge the gap between open-weight systems and proprietary frontier models in complex reasoning and long-context understanding. Addressing the common challenges of model collapse and training instability in reasoning adaptation, we propose a comprehensive, reproducible training recipe spanning system, data, and algorithmic optimizations. Our approach combines memory-efficient infrastructure for 64K-token contexts using hybrid parallelism and kernel-level optimizations with a two-stage Supervised Fine-Tuning (SFT) curriculum that mitigates distribution mismatch through verified, aligned synthetic data. Furthermore, we detail a robust Reinforcement Learning Fine-Tuning (RLFT) pipeline that stabilizes training via difficulty-aware data filtering and mixed-policy trajectory reuse. Empirical results demonstrate that Motif-2-12.7B-Reasoning achieves performance comparable to models with significantly larger parameter counts across mathematics, coding, and agentic benchmarks, offering the community a competitive open model and a practical blueprint for scaling reasoning capabilities under realistic compute constraints.
Motif 2 12.7B technical report
Nov 07, 2025We introduce Motif-2-12.7B, a new open-weight foundation model that pushes the efficiency frontier of large language models by combining architectural innovation with system-level optimization. Designed for scalable language understanding and robust instruction generalization under constrained compute budgets, Motif-2-12.7B builds upon Motif-2.6B with the integration of Grouped Differential Attention (GDA), which improves representational efficiency by disentangling signal and noise-control attention pathways. The model is pre-trained on 5.5 trillion tokens spanning diverse linguistic, mathematical, scientific, and programming domains using a curriculum-driven data scheduler that gradually changes the data composition ratio. The training system leverages the MuonClip optimizer alongside custom high-performance kernels, including fused PolyNorm activations and the Parallel Muon algorithm, yielding significant throughput and memory efficiency gains in large-scale distributed environments. Post-training employs a three-stage supervised fine-tuning pipeline that successively enhances general instruction adherence, compositional understanding, and linguistic precision. Motif-2-12.7B demonstrates competitive performance across diverse benchmarks, showing that thoughtful architectural scaling and optimized training design can rival the capabilities of much larger models.
Grouped Differential Attention
Oct 08, 2025The self-attention mechanism, while foundational to modern Transformer architectures, suffers from a critical inefficiency: it frequently allocates substantial attention to redundant or noisy context. Differential Attention addressed this by using subtractive attention maps for signal and noise, but its required balanced head allocation imposes rigid constraints on representational flexibility and scalability. To overcome this, we propose Grouped Differential Attention (GDA), a novel approach that introduces unbalanced head allocation between signal-preserving and noise-control groups. GDA significantly enhances signal focus by strategically assigning more heads to signal extraction and fewer to noise-control, stabilizing the latter through controlled repetition (akin to GQA). This design achieves stronger signal fidelity with minimal computational overhead. We further extend this principle to group-differentiated growth, a scalable strategy that selectively replicates only the signal-focused heads, thereby ensuring efficient capacity expansion. Through large-scale pretraining and continual training experiments, we demonstrate that moderate imbalance ratios in GDA yield substantial improvements in generalization and stability compared to symmetric baselines. Our results collectively establish that ratio-aware head allocation and selective expansion offer an effective and practical path toward designing scalable, computation-efficient Transformer architectures.
Expanding Foundational Language Capabilities in Open-Source LLMs through a Korean Case Study
Sep 04, 2025We introduce Llama-3-Motif, a language model consisting of 102 billion parameters, specifically designed to enhance Korean capabilities while retaining strong performance in English. Developed on the Llama 3 architecture, Llama-3-Motif employs advanced training techniques, including LlamaPro and Masked Structure Growth, to effectively scale the model without altering its core Transformer architecture. Using the MoAI platform for efficient training across hyperscale GPU clusters, we optimized Llama-3-Motif using a carefully curated dataset that maintains a balanced ratio of Korean and English data. Llama-3-Motif shows decent performance on Korean-specific benchmarks, outperforming existing models and achieving results comparable to GPT-4.
Effective Heterogeneous Federated Learning via Efficient Hypernetwork-based Weight Generation
Jul 03, 2024



While federated learning leverages distributed client resources, it faces challenges due to heterogeneous client capabilities. This necessitates allocating models suited to clients' resources and careful parameter aggregation to accommodate this heterogeneity. We propose HypeMeFed, a novel federated learning framework for supporting client heterogeneity by combining a multi-exit network architecture with hypernetwork-based model weight generation. This approach aligns the feature spaces of heterogeneous model layers and resolves per-layer information disparity during weight aggregation. To practically realize HypeMeFed, we also propose a low-rank factorization approach to minimize computation and memory overhead associated with hypernetworks. Our evaluations on a real-world heterogeneous device testbed indicate that HypeMeFed enhances accuracy by 5.12% over FedAvg, reduces the hypernetwork memory requirements by 98.22%, and accelerates its operations by 1.86 times compared to a naive hypernetwork approach. These results demonstrate HypeMeFed's effectiveness in leveraging and engaging heterogeneous clients for federated learning.
The Spatial Selective Auditory Attention of Cochlear Implant Users in Different Conversational Sound Levels
Mar 03, 2021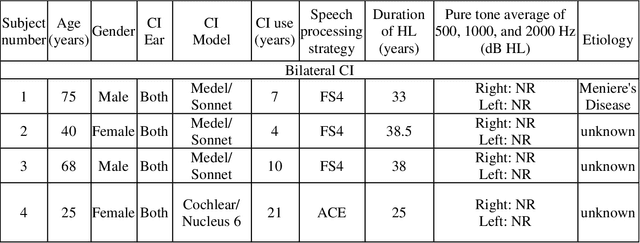
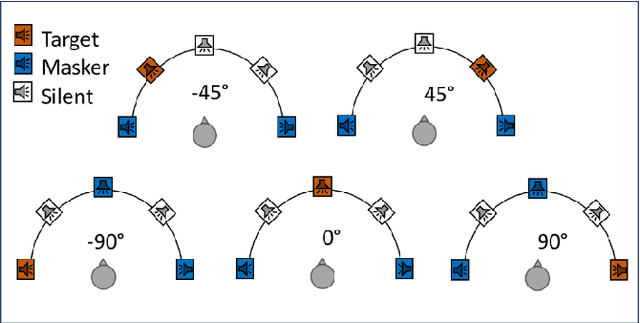
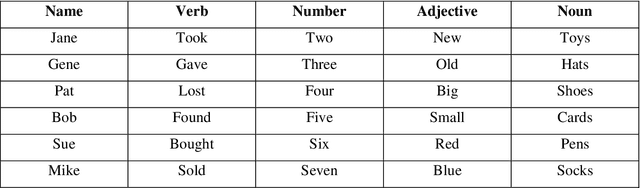
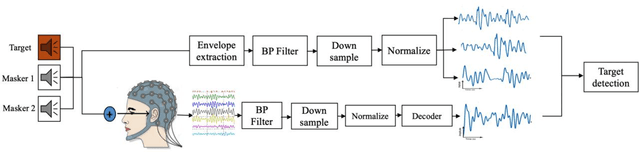
In multi speakers environments, cochlear implant (CI) users may attend to a target sound source in a different manner from the normal hearing (NH) individuals during a conversation. This study attempted to investigate the effect of conversational sound levels on the mechanisms adopted by CI and NH listeners in selective auditory attention and how it affects their daily conversation. Nine CI users (five bilateral, three unilateral, and one bimodal) and eight NH listeners participated in this study. The behavioral speech recognition scores were collected using a matrix sentences test and neural tracking to speech envelope was recorded using electroencephalography (EEG). Speech stimuli were presented at three different levels (75, 65, and 55 dB SPL) in the presence of two maskers from three spatially separated speakers. Different combinations of assisted/impaired hearing modes were evaluated for CI users and the outcomes were analyzed in three categories: electric hearing only, acoustic hearing only, and electric+acoustic hearing. Our results showed that increasing the conversational sound level degraded the selective auditory attention in electrical hearing. On the other hand, increasing the sound level improved the selective auditory attention for the acoustic hearing group. In NH listeners, however, increasing the sound level did not cause a significant change in the auditory attention. Our result implies that the effect of the sound level on the selective auditory attention varies depending on hearing modes and the loudness control is necessary for the ease of attending to the conversation by CI users.
The effect of speech and noise levels on the quality perceived by cochlear implant and normal hearing listeners
Mar 03, 2021
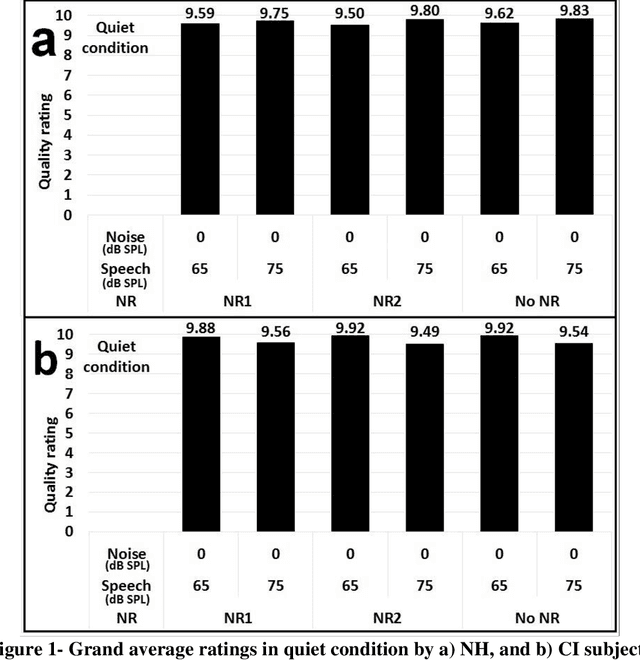
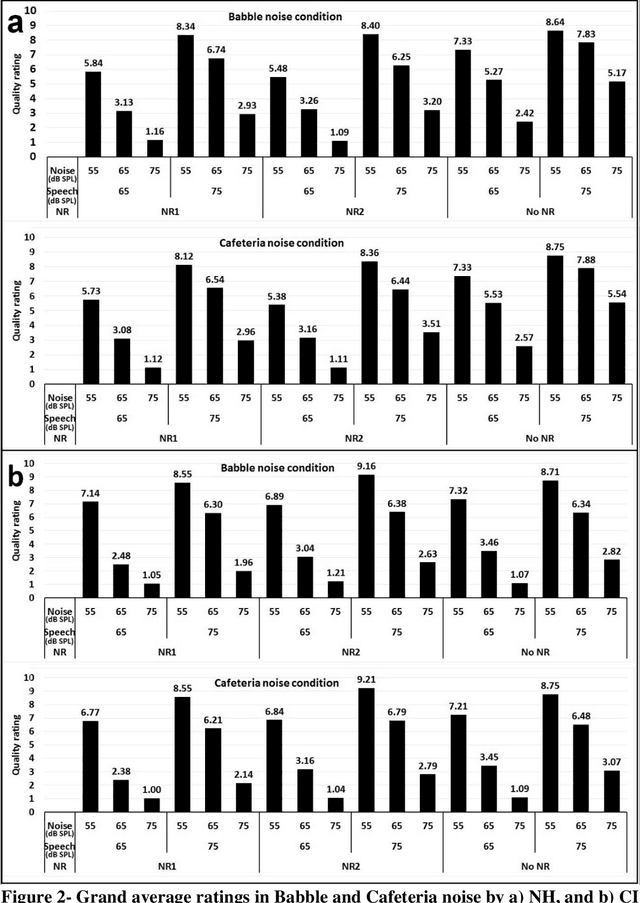

Electrical hearing by cochlear implants (CIs) may be fundamentally different from acoustic hearing by normal-hearing (NH) listeners, presumably showing unequal speech quality perception in various noise environments. Noise reduction (NR) algorithms used in CI reduce the noise in favor of signal-to-noise ratio (SNR), regardless of plausible accompanying distortions that may degrade the speech quality perception. To gain better understanding of CI speech quality perception, the present work aimed investigating speech quality perception in a diverse noise conditions, including factors of speech/noise levels, type of noise, and distortions caused by NR models. Fifteen NH and seven CI subjects participated in this study. Speech sentences were set to two different levels (65 and 75 dB SPL). Two types of noise (Cafeteria and Babble) at three levels (55, 65, and 75 dB SPL) were used. Sentences were processed using two NR algorithms to investigate the perceptual sensitivity of CI and NH listeners to the distortion. All sentences processed with the combinations of these sets were presented to CI and NH listeners, and they were asked to rate the sound quality of speech as they perceived. The effect of each factor on the perceived speech quality was investigated based on the group averaged quality rated by CI and NH listeners. Consistent with previous studies, CI listeners were not as sensitive as NH to the distortion made by NR algorithms. Statistical analysis showed that the speech level has significant effect on quality perception. At the same SNR, the quality of 65 dB speech was rated higher than that of 75 dB for CI users, but vice versa for NH listeners. Therefore, the present study showed that the perceived speech quality patterns were different between CI and NH listeners in terms of their sensitivity to distortion and speech level in complex listening environment.
Prominent Attribute Modification using Attribute Dependent Generative Adversarial Network
Apr 24, 2020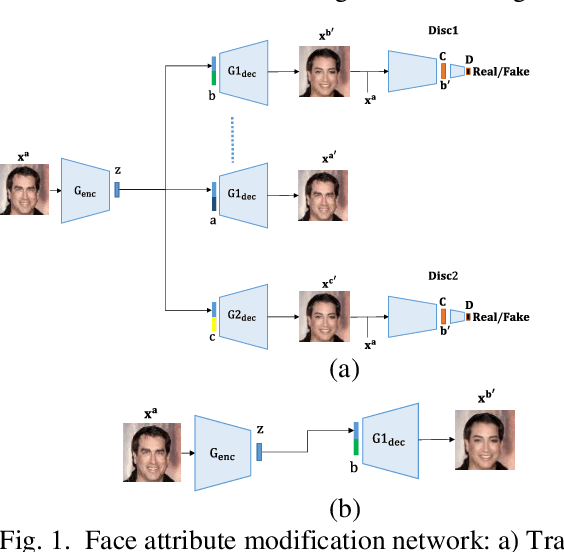



Modifying the facial images with desired attributes is important, though challenging tasks in computer vision, where it aims to modify single or multiple attributes of the face image. Some of the existing methods are either based on attribute independent approaches where the modification is done in the latent representation or attribute dependent approaches. The attribute independent methods are limited in performance as they require the desired paired data for changing the desired attributes. Secondly, the attribute independent constraint may result in the loss of information and, hence, fail in generating the required attributes in the face image. In contrast, the attribute dependent approaches are effective as these approaches are capable of modifying the required features along with preserving the information in the given image. However, attribute dependent approaches are sensitive and require a careful model design in generating high-quality results. To address this problem, we propose an attribute dependent face modification approach. The proposed approach is based on two generators and two discriminators that utilize the binary as well as the real representation of the attributes and, in return, generate high-quality attribute modification results. Experiments on the CelebA dataset show that our method effectively performs the multiple attribute editing with preserving other facial details intactly.
Frame-to-Frame Aggregation of Active Regions in Web Videos for Weakly Supervised Semantic Segmentation
Aug 13, 2019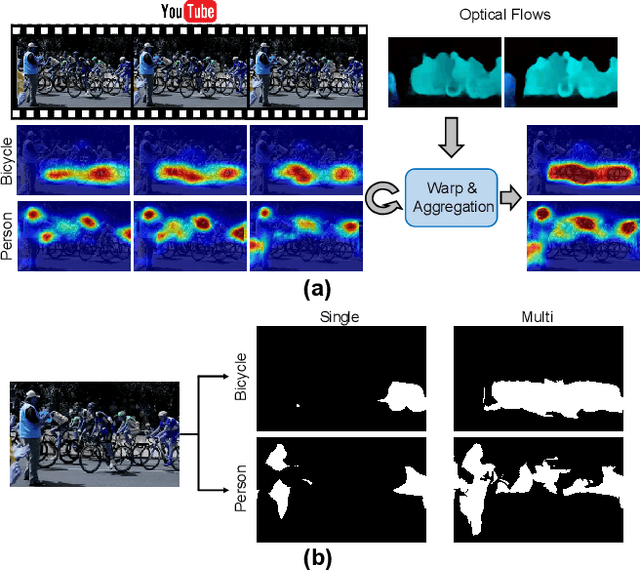
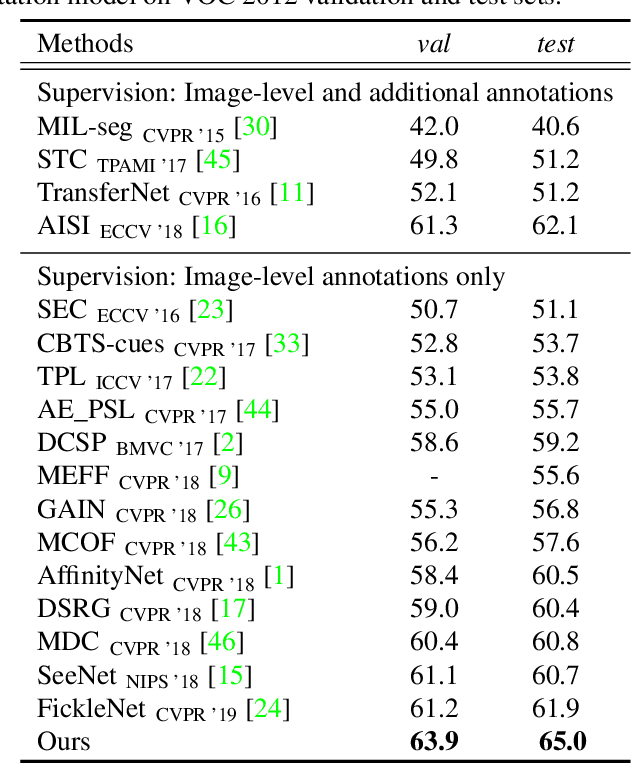
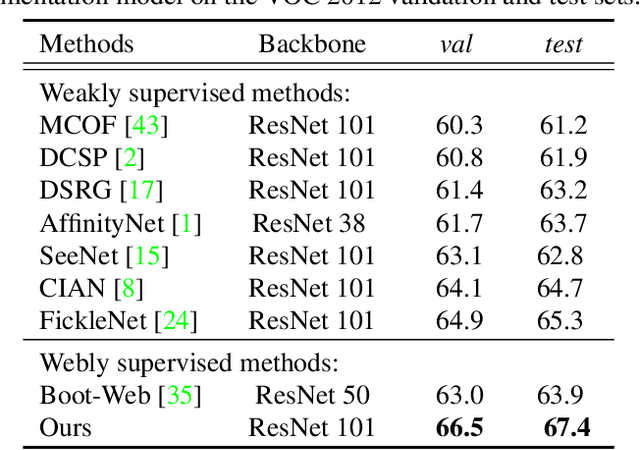
When a deep neural network is trained on data with only image-level labeling, the regions activated in each image tend to identify only a small region of the target object. We propose a method of using videos automatically harvested from the web to identify a larger region of the target object by using temporal information, which is not present in the static image. The temporal variations in a video allow different regions of the target object to be activated. We obtain an activated region in each frame of a video, and then aggregate the regions from successive frames into a single image, using a warping technique based on optical flow. The resulting localization maps cover more of the target object, and can then be used as proxy ground-truth to train a segmentation network. This simple approach outperforms existing methods under the same level of supervision, and even approaches relying on extra annotations. Based on VGG-16 and ResNet 101 backbones, our method achieves the mIoU of 65.0 and 67.4, respectively, on PASCAL VOC 2012 test images, which represents a new state-of-the-art.
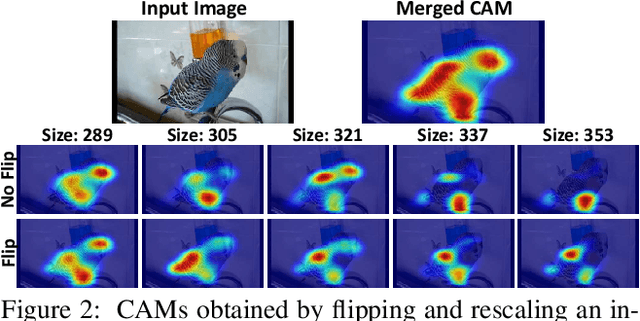
FickleNet: Weakly and Semi-supervised Semantic Image Segmentation using Stochastic Inference
Mar 02, 2019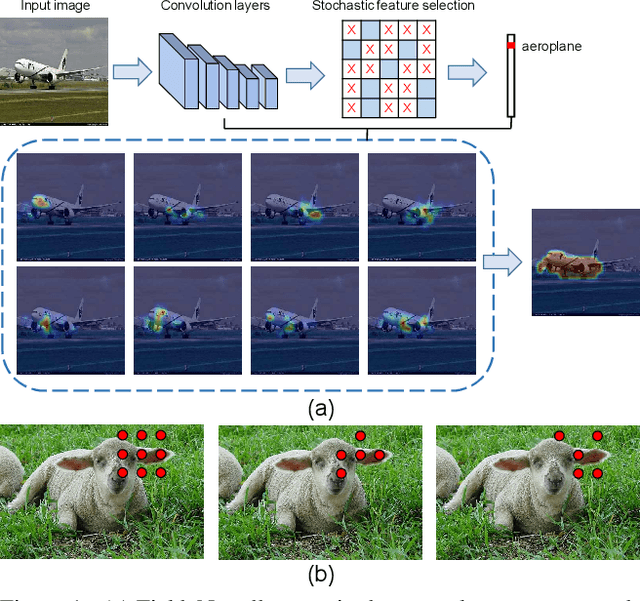
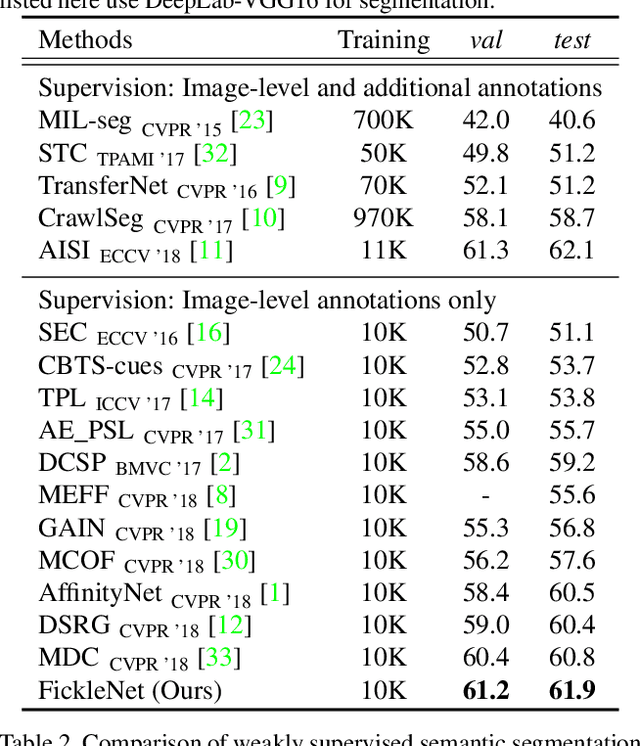
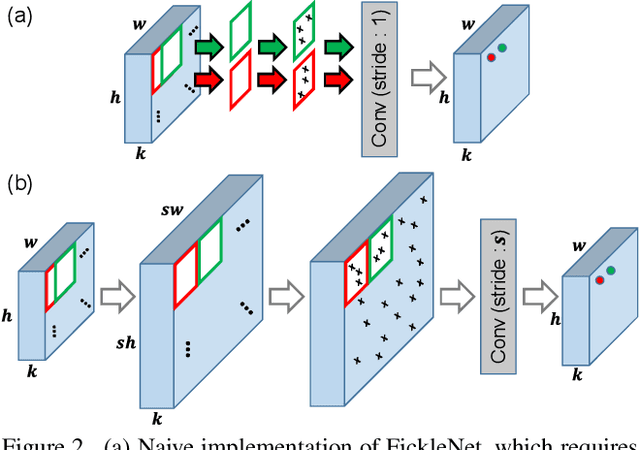

The main obstacle to weakly supervised semantic image segmentation is the difficulty of obtaining pixel-level information from coarse image-level annotations. Most methods based on image-level annotations use localization maps obtained from the classifier, but these only focus on the small discriminative parts of objects and do not capture precise boundaries. FickleNet explores diverse combinations of locations on feature maps created by generic deep neural networks. It selects hidden units randomly and then uses them to obtain activation scores for image classification. FickleNet implicitly learns the coherence of each location in the feature maps, resulting in a localization map which identifies both discriminative and other parts of objects. The ensemble effects are obtained from a single network by selecting random hidden unit pairs, which means that a variety of localization maps are generated from a single image. Our approach does not require any additional training steps and only adds a simple layer to a standard convolutional neural network; nevertheless it outperforms recent comparable techniques on the Pascal VOC 2012 benchmark in both weakly and semi-supervised settings.