 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSnet: Mutual Suppression Network for Disentangled Video Representations
Paper and Code
Apr 13, 2018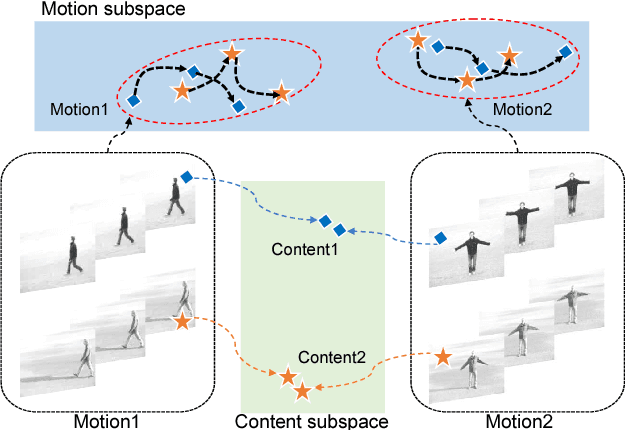
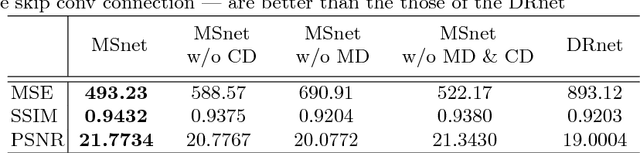
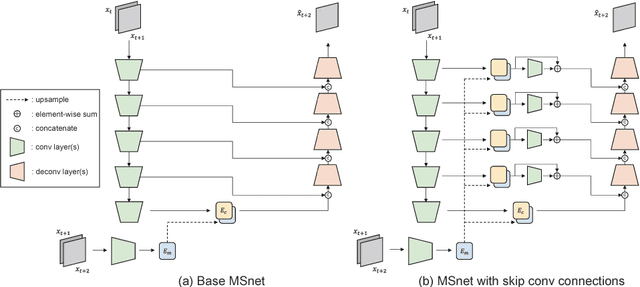

The extraction of meaningful features from videos is important as they can be used in various applications. Despite its importance, video representation learning has not been studied much, because it is challenging to deal with both content and motion information. We present a Mutual Suppression network (MSnet) to learn disentangled motion and content features in videos. The MSnet is trained in such way that content features do not contain motion information and motion features do not contain content information; this is done by suppressing each other with adversarial training. We utilize the disentangled features from the MSnet for several tasks, such as frame reproduction, pixel-level video frame prediction, and dense optical flow estimation, to demonstrate the strength of MSnet. The proposed model outperforms the state-of-the-art methods in pixel-level video frame prediction. The source code will be publicly available.