 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEM: Training-Free Background Embedding Memory for False-Positive Suppression in Real-Time Fixed-Background Camera
Apr 13, 2026Pretrained detectors perform well on benchmarks but often suffer performance degradation in real-world deployments due to distribution gaps between training data and target environments. COCO-like benchmarks emphasize category diversity rather than instance density, causing detectors trained under per-class sparsity to struggle in dense, single- or few-class scenes such as surveillance and traffic monitoring. In fixed-camera environments, the quasi-static background provides a stable, label-free prior that can be exploited at inference to suppress spurious detections. To address the issue, we propose Background Embedding Memory (BEM), a lightweight, training-free, weight-frozen module that can be attached to pretrained detectors during inference. BEM estimates clean background embeddings, maintains a prototype memory, and re-scores detection logits with an inverse-similarity, rank-weighted penalty, effectively reducing false positives while maintaining recall. Empirically, background-frame cosine similarity correlates negatively with object count and positively with Precision-Confidence AUC (P-AUC), motivating its use as a training-free control signal. Across YOLO and RT-DETR families on LLVIP and simulated surveillance streams, BEM consistently reduces false positives while preserving real-time performance. Our code is available at https://github.com/Leo-Park1214/Background-Embedding-Memory.git
It's Time to Get It Right: Improving Analog Clock Reading and Clock-Hand Spatial Reasoning in Vision-Language Models
Mar 09, 2026Advances in vision-language models (VLMs) have achieved remarkable success on complex multimodal reasoning tasks, leading to the assumption that they should also excel at reading analog clocks. However, contrary to this expectation, our study reveals that reading analog clocks in real-world environments remains a significant challenge for state-of-the-art VLMs. Existing analog clock datasets are largely synthetic or planar with limited stylistic diversity and minimal background context, failing to capture the visual variability of real-world scenes. As a result, VLMs trained on such data exhibit weak spatial-temporal reasoning, frequently confusing the hour and minute hands and struggling under common visual conditions such as occlusion, lighting variation, and cluttered backgrounds. To address this issue, we introduce TickTockVQA, a human-annotated dataset containing analog clocks in diverse real-world scenarios. TickTockVQA provides explicit hour and minute annotations, and includes an AM/PM tag when it is inferable from the visual context. Furthermore, we propose Swap-DPO, a direct preference optimization based fine-tuning framework to align model reasoning toward accurate time interpretation. Experimental results demonstrate that our approach substantially enhances clock reading accuracy and robustness under real-world conditions, establishing a foundation for future research on spatial-temporal reasoning and visual understanding in VLMs.
SAMIRO: Spatial Attention Mutual Information Regularization with a Pre-trained Model as Oracle for Lane Detection
Nov 13, 2025



Lane detection is an important topic in the future mobility solutions. Real-world environmental challenges such as background clutter, varying illumination, and occlusions pose significant obstacles to effective lane detection, particularly when relying on data-driven approaches that require substantial effort and cost for data collection and annotation. To address these issues, lane detection methods must leverage contextual and global information from surrounding lanes and objects. In this paper, we propose a Spatial Attention Mutual Information Regularization with a pre-trained model as an Oracle, called SAMIRO. SAMIRO enhances lane detection performance by transferring knowledge from a pretrained model while preserving domain-agnostic spatial information. Leveraging SAMIRO's plug-and-play characteristic, we integrate it into various state-of-the-art lane detection approaches and conduct extensive experiments on major benchmarks such as CULane, Tusimple, and LLAMAS. The results demonstrate that SAMIRO consistently improves performance across different models and datasets. The code will be made available upon publication.
Frame-to-Frame Aggregation of Active Regions in Web Videos for Weakly Supervised Semantic Segmentation
Aug 13, 2019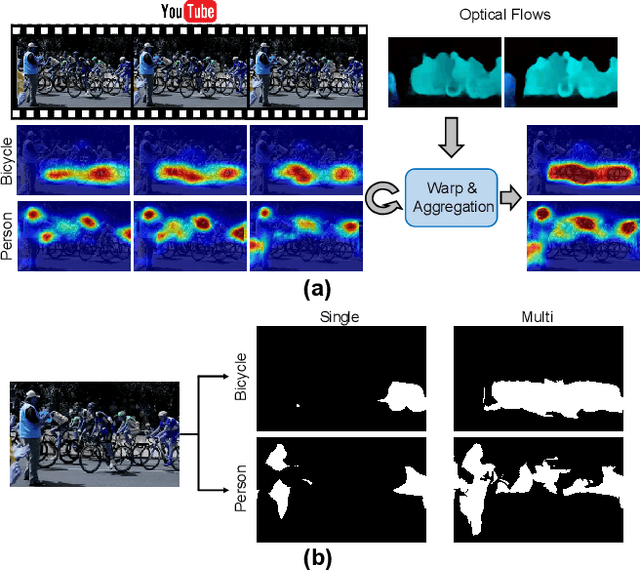
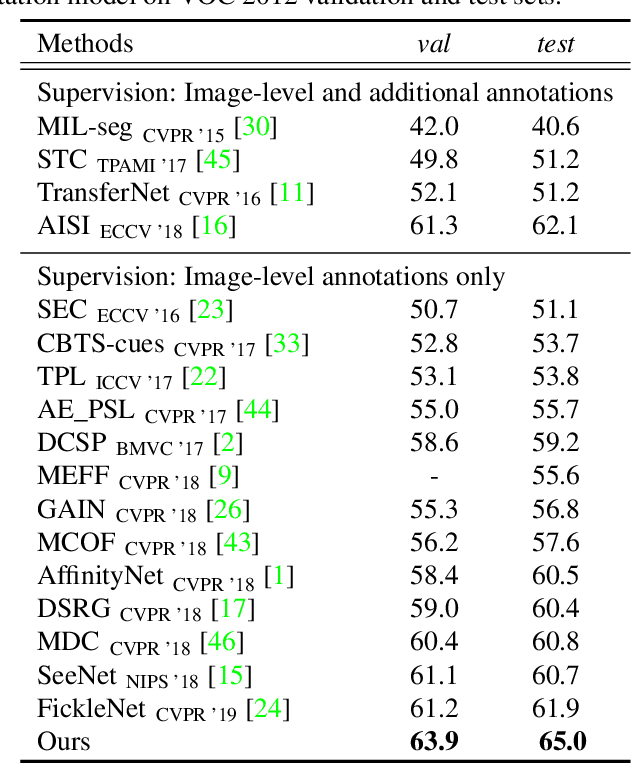
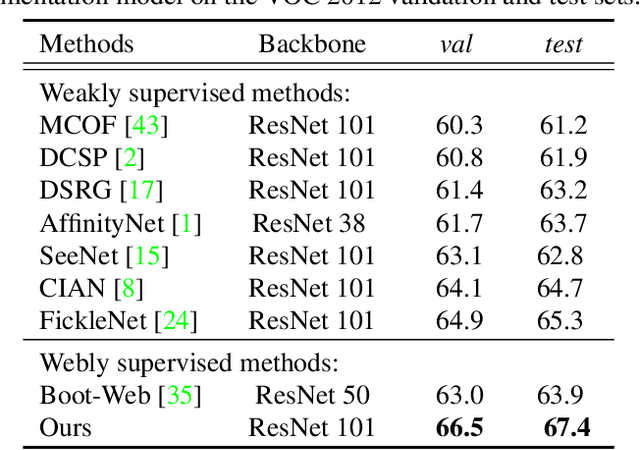
When a deep neural network is trained on data with only image-level labeling, the regions activated in each image tend to identify only a small region of the target object. We propose a method of using videos automatically harvested from the web to identify a larger region of the target object by using temporal information, which is not present in the static image. The temporal variations in a video allow different regions of the target object to be activated. We obtain an activated region in each frame of a video, and then aggregate the regions from successive frames into a single image, using a warping technique based on optical flow. The resulting localization maps cover more of the target object, and can then be used as proxy ground-truth to train a segmentation network. This simple approach outperforms existing methods under the same level of supervision, and even approaches relying on extra annotations. Based on VGG-16 and ResNet 101 backbones, our method achieves the mIoU of 65.0 and 67.4, respectively, on PASCAL VOC 2012 test images, which represents a new state-of-the-art.
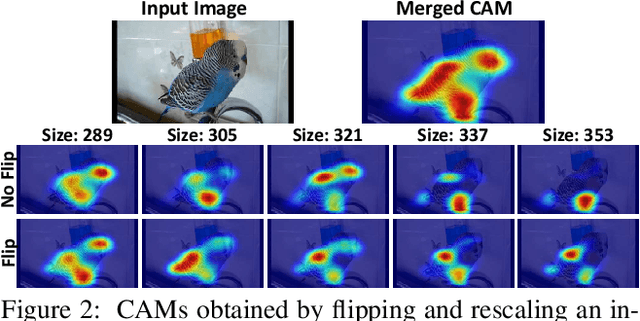
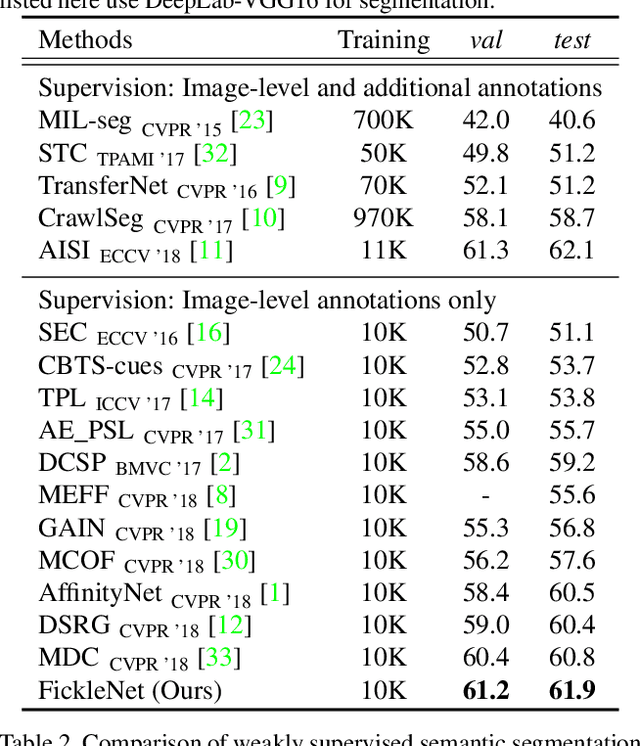
FickleNet: Weakly and Semi-supervised Semantic Image Segmentation using Stochastic Inference
Mar 02, 2019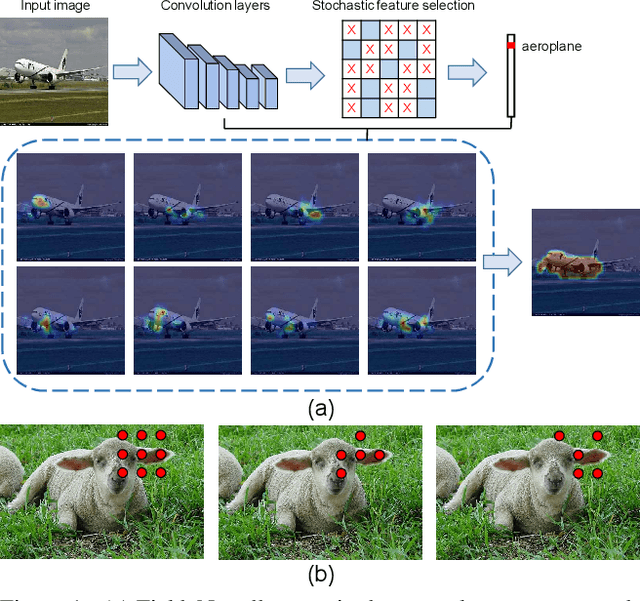
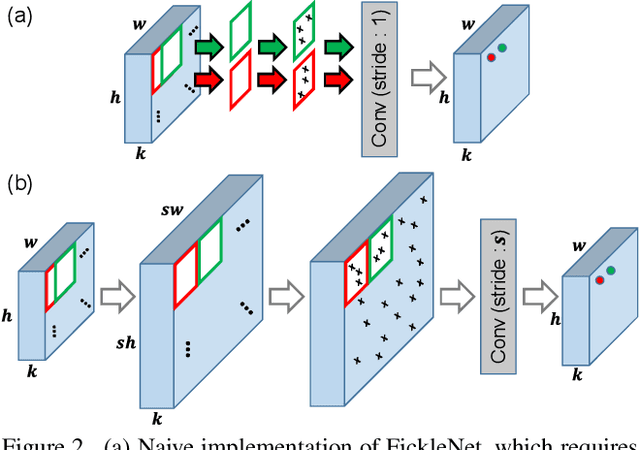

The main obstacle to weakly supervised semantic image segmentation is the difficulty of obtaining pixel-level information from coarse image-level annotations. Most methods based on image-level annotations use localization maps obtained from the classifier, but these only focus on the small discriminative parts of objects and do not capture precise boundaries. FickleNet explores diverse combinations of locations on feature maps created by generic deep neural networks. It selects hidden units randomly and then uses them to obtain activation scores for image classification. FickleNet implicitly learns the coherence of each location in the feature maps, resulting in a localization map which identifies both discriminative and other parts of objects. The ensemble effects are obtained from a single network by selecting random hidden unit pairs, which means that a variety of localization maps are generated from a single image. Our approach does not require any additional training steps and only adds a simple layer to a standard convolutional neural network; nevertheless it outperforms recent comparable techniques on the Pascal VOC 2012 benchmark in both weakly and semi-supervised settings.
Robust Tumor Localization with Pyramid Grad-CAM
May 29, 2018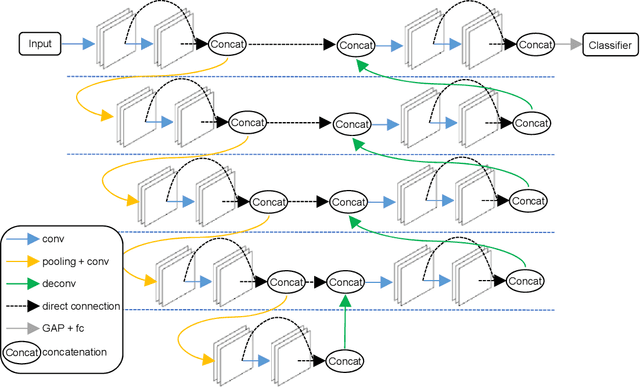
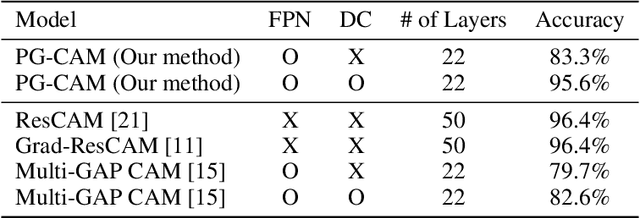
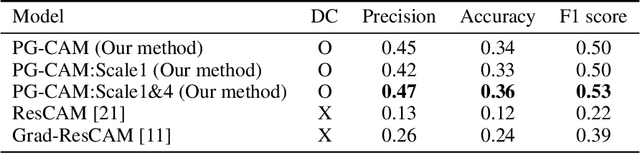
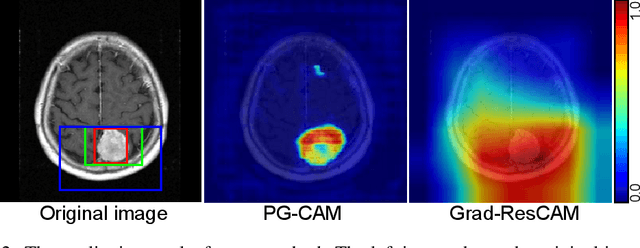
A meningioma is a type of brain tumor that requires tumor volume size follow ups in order to reach appropriate clinical decisions. A fully automated tool for meningioma detection is necessary for reliable and consistent tumor surveillance. There have been various studies concerning automated lesion detection. Studies on the application of convolutional neural network (CNN)-based methods, which have achieved a state-of-the-art level of performance in various computer vision tasks, have been carried out. However, the applicable diseases are limited, owing to a lack of strongly annotated data being present in medical image analysis. In order to resolve the above issue we propose pyramid gradient-based class activation mapping (PG-CAM) which is a novel method for tumor localization that can be trained in weakly supervised manner. PG-CAM uses a densely connected encoder-decoder-based feature pyramid network (DC-FPN) as a backbone structure, and extracts a multi-scale Grad-CAM that captures hierarchical features of a tumor. We tested our model using meningioma brain magnetic resonance (MR) data collected from the collaborating hospital. In our experiments, PG-CAM outperformed Grad-CAM by delivering a 23 percent higher localization accuracy for the validation set.
MSnet: Mutual Suppression Network for Disentangled Video Representations
Apr 13, 2018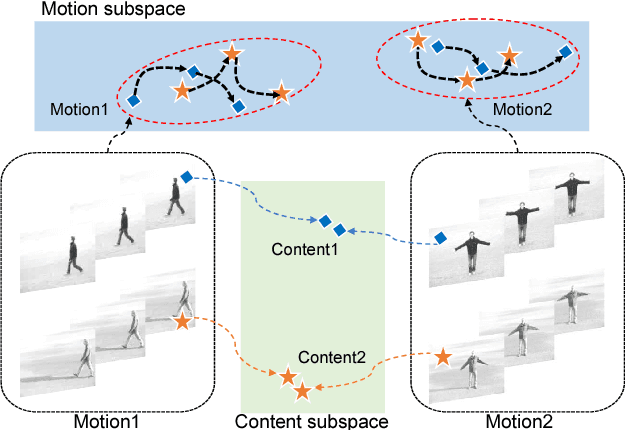
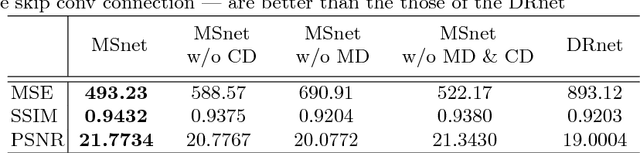
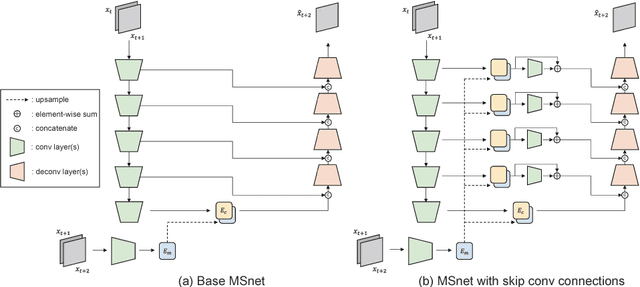

The extraction of meaningful features from videos is important as they can be used in various applications. Despite its importance, video representation learning has not been studied much, because it is challenging to deal with both content and motion information. We present a Mutual Suppression network (MSnet) to learn disentangled motion and content features in videos. The MSnet is trained in such way that content features do not contain motion information and motion features do not contain content information; this is done by suppressing each other with adversarial training. We utilize the disentangled features from the MSnet for several tasks, such as frame reproduction, pixel-level video frame prediction, and dense optical flow estimation, to demonstrate the strength of MSnet. The proposed model outperforms the state-of-the-art methods in pixel-level video frame prediction. The source code will be publicly available.
Training IBM Watson using Automatically Generated Question-Answer Pairs
Nov 12, 2016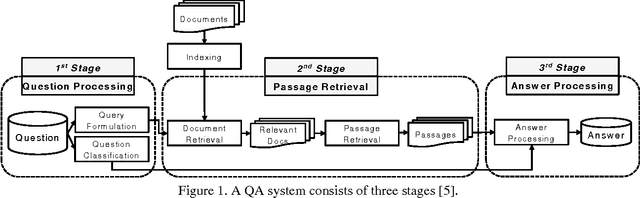
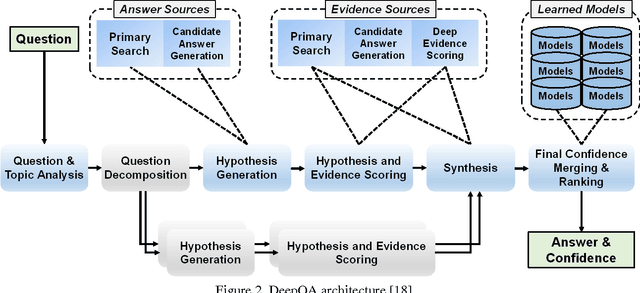
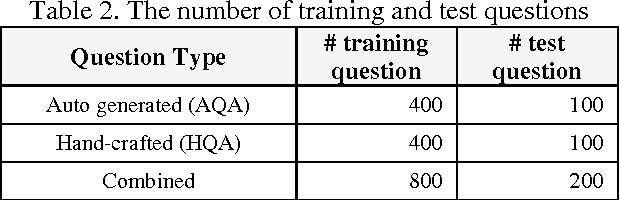
IBM Watson is a cognitive computing system capable of question answering in natural languages. It is believed that IBM Watson can understand large corpora and answer relevant questions more effectively than any other question-answering system currently available. To unleash the full power of Watson, however, we need to train its instance with a large number of well-prepared question-answer pairs. Obviously, manually generating such pairs in a large quantity is prohibitively time consuming and significantly limits the efficiency of Watson's training. Recently, a large-scale dataset of over 30 million question-answer pairs was reported. Under the assumption that using such an automatically generated dataset could relieve the burden of manual question-answer generation, we tried to use this dataset to train an instance of Watson and checked the training efficiency and accuracy. According to our experiments, using this auto-generated dataset was effective for training Watson, complementing manually crafted question-answer pairs. To the best of the authors' knowledge, this work is the first attempt to use a large-scale dataset of automatically generated question-answer pairs for training IBM Watson. We anticipate that the insights and lessons obtained from our experiments will be useful for researchers who want to expedite Watson training leveraged by automatically generated question-answer pairs.
LSTM-Based System-Call Language Modeling and Robust Ensemble Method for Designing Host-Based Intrusion Detection Systems
Nov 06, 2016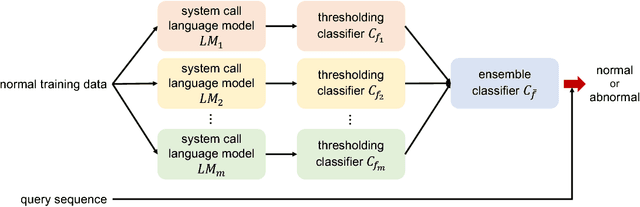
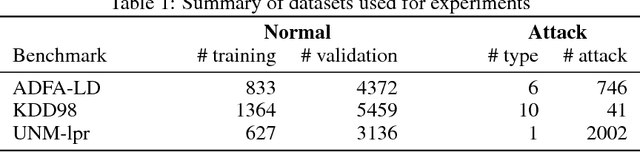

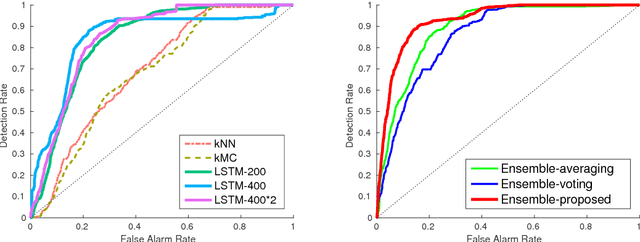
In computer security, designing a robust intrusion detection system is one of the most fundamental and important problems. In this paper, we propose a system-call language-modeling approach for designing anomaly-based host intrusion detection systems. To remedy the issue of high false-alarm rates commonly arising in conventional methods, we employ a novel ensemble method that blends multiple thresholding classifiers into a single one, making it possible to accumulate 'highly normal' sequences. The proposed system-call language model has various advantages leveraged by the fact that it can learn the semantic meaning and interactions of each system call that existing methods cannot effectively consider. Through diverse experiments on public benchmark datasets, we demonstrate the validity and effectiveness of the proposed method. Moreover, we show that our model possesses high portability, which is one of the key aspects of realizing successful intrusion detection systems.