 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVFLIP: A Backdoor Defense for Vertical Federated Learning via Identification and Purification
Aug 29, 2024Vertical Federated Learning (VFL) focuses on handling vertically partitioned data over FL participants. Recent studies have discovered a significant vulnerability in VFL to backdoor attacks which specifically target the distinct characteristics of VFL. Therefore, these attacks may neutralize existing defense mechanisms designed primarily for Horizontal Federated Learning (HFL) and deep neural networks. In this paper, we present the first backdoor defense, called VFLIP, specialized for VFL. VFLIP employs the identification and purification techniques that operate at the inference stage, consequently improving the robustness against backdoor attacks to a great extent. VFLIP first identifies backdoor-triggered embeddings by adopting a participant-wise anomaly detection approach. Subsequently, VFLIP conducts purification which removes the embeddings identified as malicious and reconstructs all the embeddings based on the remaining embeddings. We conduct extensive experiments on CIFAR10, CINIC10, Imagenette, NUS-WIDE, and BankMarketing to demonstrate that VFLIP can effectively mitigate backdoor attacks in VFL. https://github.com/blingcho/VFLIP-esorics24
Precise Extraction of Deep Learning Models via Side-Channel Attacks on Edge/Endpoint Devices
Mar 05, 2024With growing popularity, deep learning (DL) models are becoming larger-scale, and only the companies with vast training datasets and immense computing power can manage their business serving such large models. Most of those DL models are proprietary to the companies who thus strive to keep their private models safe from the model extraction attack (MEA), whose aim is to steal the model by training surrogate models. Nowadays, companies are inclined to offload the models from central servers to edge/endpoint devices. As revealed in the latest studies, adversaries exploit this opportunity as new attack vectors to launch side-channel attack (SCA) on the device running victim model and obtain various pieces of the model information, such as the model architecture (MA) and image dimension (ID). Our work provides a comprehensive understanding of such a relationship for the first time and would benefit future MEA studies in both offensive and defensive sides in that they may learn which pieces of information exposed by SCA are more important than the others. Our analysis additionally reveals that by grasping the victim model information from SCA, MEA can get highly effective and successful even without any prior knowledge of the model. Finally, to evince the practicality of our analysis results, we empirically apply SCA, and subsequently, carry out MEA under realistic threat assumptions. The results show up to 5.8 times better performance than when the adversary has no model information about the victim model.
FLGuard: Byzantine-Robust Federated Learning via Ensemble of Contrastive Models
Mar 05, 2024Federated Learning (FL) thrives in training a global model with numerous clients by only sharing the parameters of their local models trained with their private training datasets. Therefore, without revealing the private dataset, the clients can obtain a deep learning (DL) model with high performance. However, recent research proposed poisoning attacks that cause a catastrophic loss in the accuracy of the global model when adversaries, posed as benign clients, are present in a group of clients. Therefore, recent studies suggested byzantine-robust FL methods that allow the server to train an accurate global model even with the adversaries present in the system. However, many existing methods require the knowledge of the number of malicious clients or the auxiliary (clean) dataset or the effectiveness reportedly decreased hugely when the private dataset was non-independently and identically distributed (non-IID). In this work, we propose FLGuard, a novel byzantine-robust FL method that detects malicious clients and discards malicious local updates by utilizing the contrastive learning technique, which showed a tremendous improvement as a self-supervised learning method. With contrastive models, we design FLGuard as an ensemble scheme to maximize the defensive capability. We evaluate FLGuard extensively under various poisoning attacks and compare the accuracy of the global model with existing byzantine-robust FL methods. FLGuard outperforms the state-of-the-art defense methods in most cases and shows drastic improvement, especially in non-IID settings. https://github.com/201younghanlee/FLGuard
LSTM-Based System-Call Language Modeling and Robust Ensemble Method for Designing Host-Based Intrusion Detection Systems
Nov 06, 2016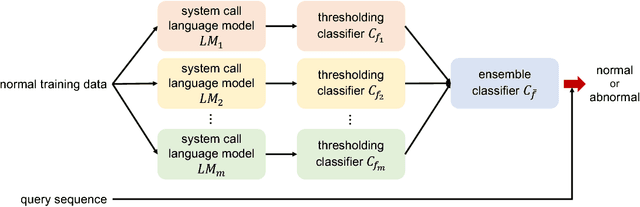
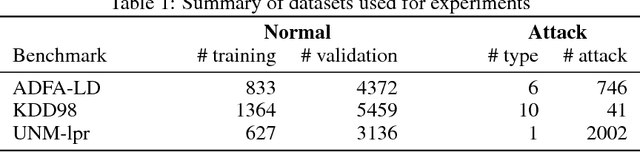

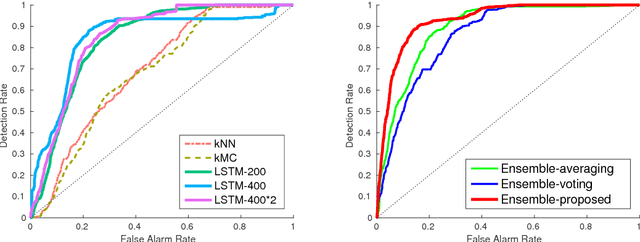
In computer security, designing a robust intrusion detection system is one of the most fundamental and important problems. In this paper, we propose a system-call language-modeling approach for designing anomaly-based host intrusion detection systems. To remedy the issue of high false-alarm rates commonly arising in conventional methods, we employ a novel ensemble method that blends multiple thresholding classifiers into a single one, making it possible to accumulate 'highly normal' sequences. The proposed system-call language model has various advantages leveraged by the fact that it can learn the semantic meaning and interactions of each system call that existing methods cannot effectively consider. Through diverse experiments on public benchmark datasets, we demonstrate the validity and effectiveness of the proposed method. Moreover, we show that our model possesses high portability, which is one of the key aspects of realizing successful intrusion detection systems.