 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Camera Image Denoising on Mobile GPUs with Deep Learning, Mobile AI 2021 Challenge: Report
May 17, 2021

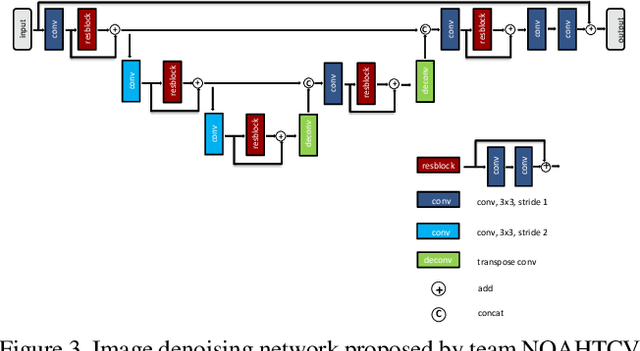
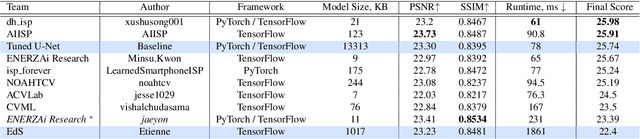
Image denoising is one of the most critical problems in mobile photo processing. While many solutions have been proposed for this task, they are usually working with synthetic data and are too computationally expensive to run on mobile devices. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop an end-to-end deep learning-based image denoising solution that can demonstrate high efficiency on smartphone GPUs. For this, the participants were provided with a novel large-scale dataset consisting of noisy-clean image pairs captured in the wild. The runtime of all models was evaluated on the Samsung Exynos 2100 chipset with a powerful Mali GPU capable of accelerating floating-point and quantized neural networks. The proposed solutions are fully compatible with any mobile GPU and are capable of processing 480p resolution images under 40-80 ms while achieving high fidelity results. A detailed description of all models developed in the challenge is provided in this paper.
Learned Smartphone ISP on Mobile NPUs with Deep Learning, Mobile AI 2021 Challenge: Report
May 17, 2021
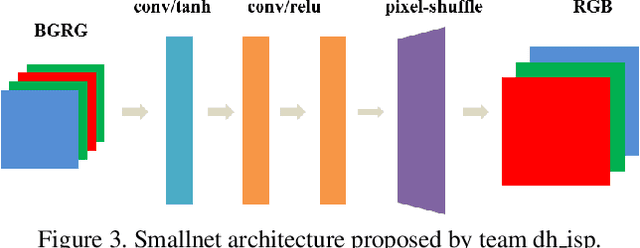
As the quality of mobile cameras starts to play a crucial role in modern smartphones, more and more attention is now being paid to ISP algorithms used to improve various perceptual aspects of mobile photos. In this Mobile AI challenge, the target was to develop an end-to-end deep learning-based image signal processing (ISP) pipeline that can replace classical hand-crafted ISPs and achieve nearly real-time performance on smartphone NPUs. For this, the participants were provided with a novel learned ISP dataset consisting of RAW-RGB image pairs captured with the Sony IMX586 Quad Bayer mobile sensor and a professional 102-megapixel medium format camera. The runtime of all models was evaluated on the MediaTek Dimensity 1000+ platform with a dedicated AI processing unit capable of accelerating both floating-point and quantized neural networks. The proposed solutions are fully compatible with the above NPU and are capable of processing Full HD photos under 60-100 milliseconds while achieving high fidelity results. A detailed description of all models developed in this challenge is provided in this paper.
Joint Contrastive Learning for Unsupervised Domain Adaptation
Jun 18, 2020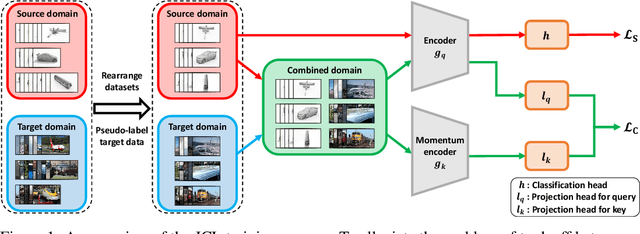
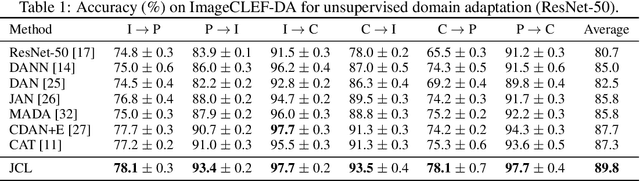
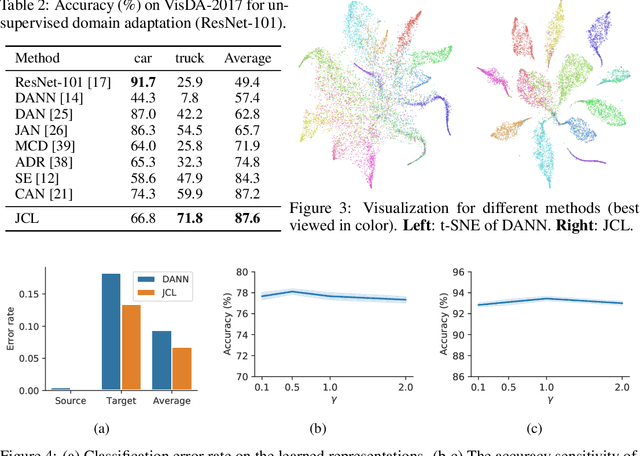

Enhancing feature transferability by matching marginal distributions has led to improvements in domain adaptation, although this is at the expense of feature discrimination. In particular, the ideal joint hypothesis error in the target error upper bound, which was previously considered to be minute, has been found to be significant, impairing its theoretical guarantee. In this paper, we propose an alternative upper bound on the target error that explicitly considers the joint error to render it more manageable. With the theoretical analysis, we suggest a joint optimization framework that combines the source and target domains. Further, we introduce Joint Contrastive Learning (JCL) to find class-level discriminative features, which is essential for minimizing the joint error. With a solid theoretical framework, JCL employs contrastive loss to maximize the mutual information between a feature and its label, which is equivalent to maximizing the Jensen-Shannon divergence between conditional distributions. Experiments on two real-world datasets demonstrate that JCL outperforms the state-of-the-art methods.
Learning Condensed and Aligned Features for Unsupervised Domain Adaptation Using Label Propagation
Mar 12, 2019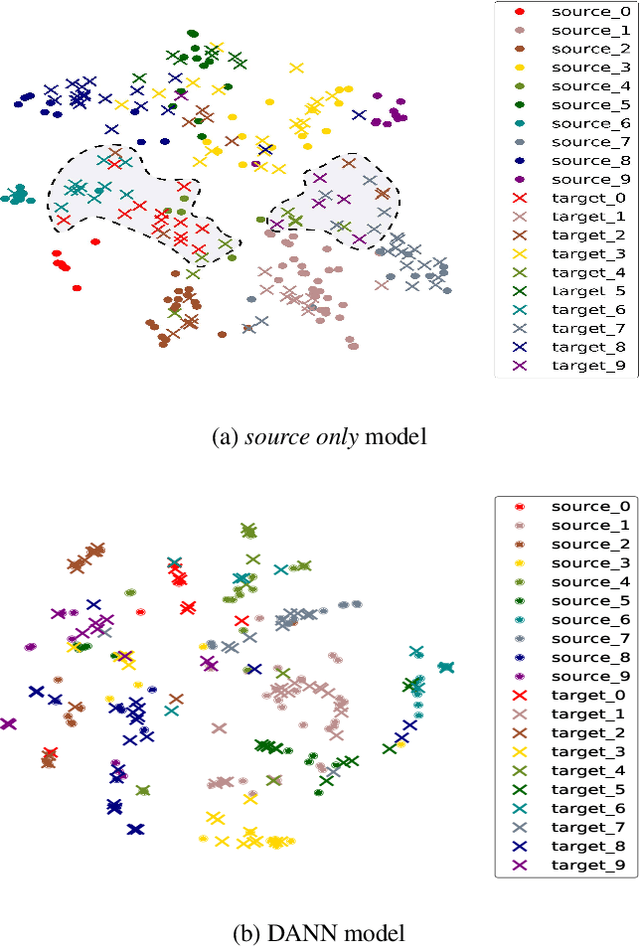
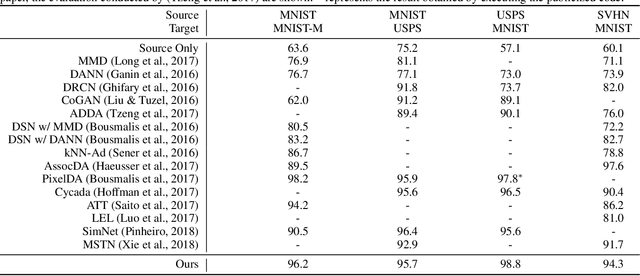
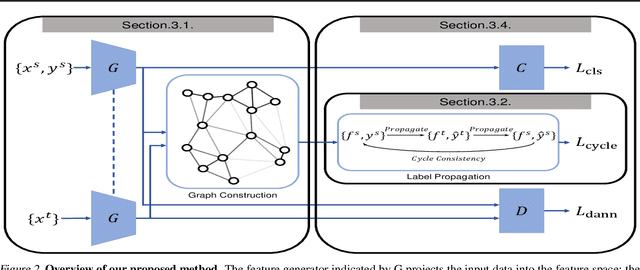
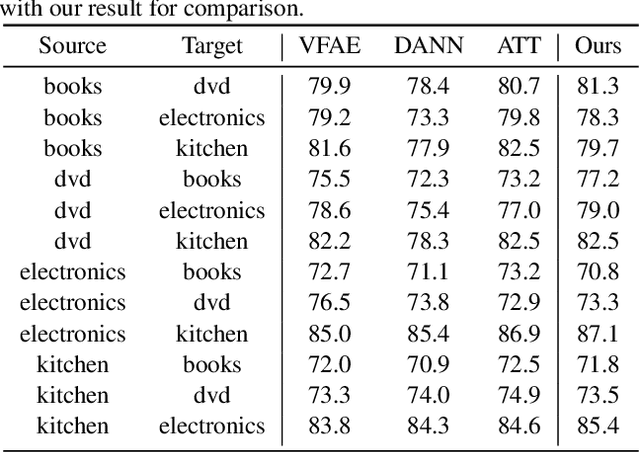
Unsupervised domain adaptation aiming to learn a specific task for one domain using another domain data has emerged to address the labeling issue in supervised learning, especially because it is difficult to obtain massive amounts of labeled data in practice. The existing methods have succeeded by reducing the difference between the embedded features of both domains, but the performance is still unsatisfactory compared to the supervised learning scheme. This is attributable to the embedded features that lay around each other but do not align perfectly and establish clearly separable clusters. We propose a novel domain adaptation method based on label propagation and cycle consistency to let the clusters of the features from the two domains overlap exactly and become clear for high accuracy. Specifically, we introduce cycle consistency to enforce the relationship between each cluster and exploit label propagation to achieve the association between the data from the perspective of the manifold structure instead of a one-to-one relation. Hence, we successfully formed aligned and discriminative clusters. We present the empirical results of our method for various domain adaptation scenarios and visualize the embedded features to prove that our method is critical for better domain adaptation.
How Generative Adversarial Networks and Their Variants Work: An Overview of GAN
Jul 27, 2018
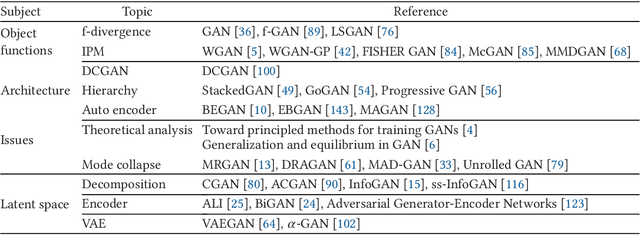

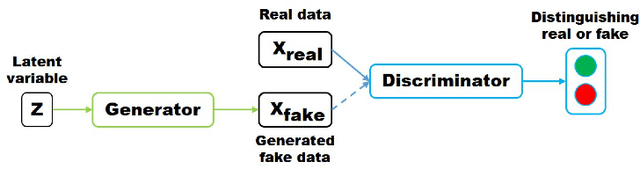
Generative Adversarial Networks (GAN) have received wide attention in the machine learning field for their potential to learn high-dimensional, complex real data distribution. Specifically, they do not rely on any assumptions about the distribution and can generate real-like samples from latent space in a simple manner. This powerful property leads GAN to be applied to various applications such as image synthesis, image attribute editing, image translation, domain adaptation and other academic fields. In this paper, we aim to discuss the details of GAN for those readers who are familiar with, but do not comprehend GAN deeply or who wish to view GAN from various perspectives. In addition, we explain how GAN operates and the fundamental meaning of various objective functions that have been suggested recently. We then focus on how the GAN can be combined with an autoencoder framework. Finally, we enumerate the GAN variants that are applied to various tasks and other fields for those who are interested in exploiting GAN for their research.
Domain Adaptation Using Adversarial Learning for Autonomous Navigation
May 22, 2018
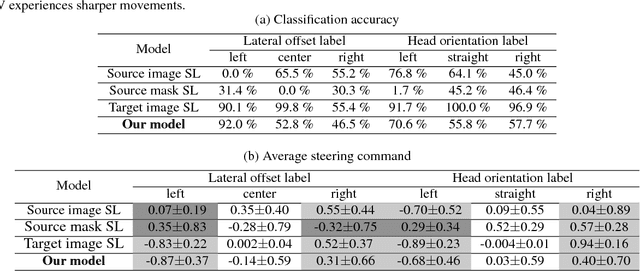
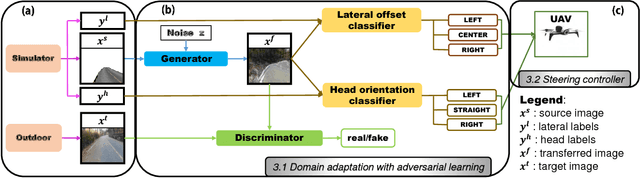

Autonomous navigation has become an increasingly popular machine learning application. Recent advances in deep learning have also resulted in great improvements to autonomous navigation. However, prior outdoor autonomous navigation depends on various expensive sensors or large amounts of real labeled data which is difficult to acquire and sometimes erroneous. The objective of this study is to train an autonomous navigation model that uses a simulator (instead of real labeled data) and an inexpensive monocular camera. In order to exploit the simulator satisfactorily, our proposed method is based on domain adaptation with adversarial learning. Specifically, we propose our model with 1) a dilated residual block in the generator, 2) cycle loss, and 3) style loss to improve the adversarial learning performance for satisfactory domain adaptation. In addition, we perform a theoretical analysis that supports the justification of our proposed method. We present empirical results of navigation in outdoor courses with various intersections using a commercial radio controlled car. We observe that our proposed method allows us to learn a favorable navigation model by generating images with realistic textures. To the best of our knowledge, this is the first work to apply domain adaptation with adversarial learning to autonomous navigation in real outdoor environments. Our proposed method can also be applied to precise image generation or other robotic tasks.
Energy-Based Sequence GANs for Recommendation and Their Connection to Imitation Learning
Jun 28, 2017
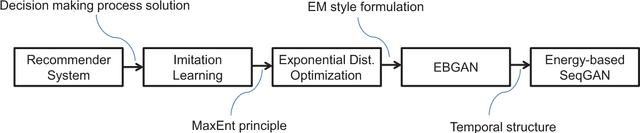
Recommender systems aim to find an accurate and efficient mapping from historic data of user-preferred items to a new item that is to be liked by a user. Towards this goal, energy-based sequence generative adversarial nets (EB-SeqGANs) are adopted for recommendation by learning a generative model for the time series of user-preferred items. By recasting the energy function as the feature function, the proposed EB-SeqGANs is interpreted as an instance of maximum-entropy imitation learning.
Training IBM Watson using Automatically Generated Question-Answer Pairs
Nov 12, 2016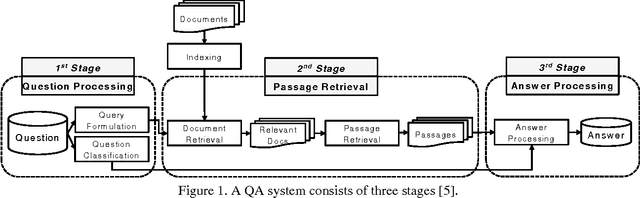
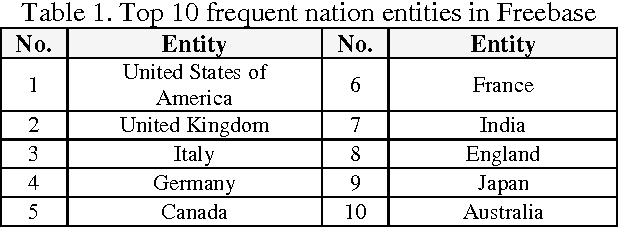
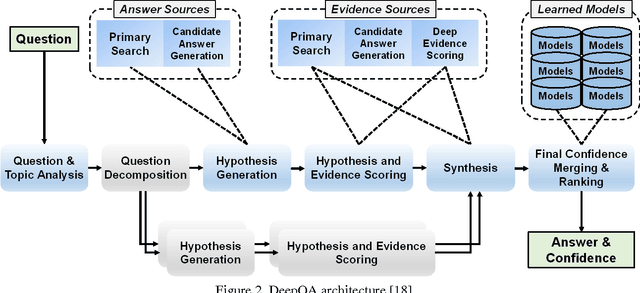
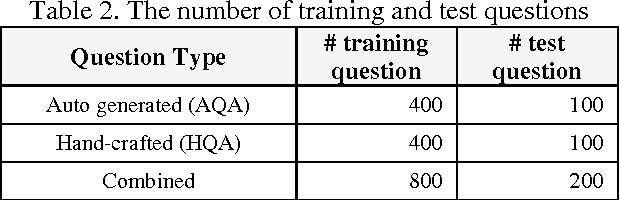
IBM Watson is a cognitive computing system capable of question answering in natural languages. It is believed that IBM Watson can understand large corpora and answer relevant questions more effectively than any other question-answering system currently available. To unleash the full power of Watson, however, we need to train its instance with a large number of well-prepared question-answer pairs. Obviously, manually generating such pairs in a large quantity is prohibitively time consuming and significantly limits the efficiency of Watson's training. Recently, a large-scale dataset of over 30 million question-answer pairs was reported. Under the assumption that using such an automatically generated dataset could relieve the burden of manual question-answer generation, we tried to use this dataset to train an instance of Watson and checked the training efficiency and accuracy. According to our experiments, using this auto-generated dataset was effective for training Watson, complementing manually crafted question-answer pairs. To the best of the authors' knowledge, this work is the first attempt to use a large-scale dataset of automatically generated question-answer pairs for training IBM Watson. We anticipate that the insights and lessons obtained from our experiments will be useful for researchers who want to expedite Watson training leveraged by automatically generated question-answer pairs.