 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Condensed and Aligned Features for Unsupervised Domain Adaptation Using Label Propagation
Mar 12, 2019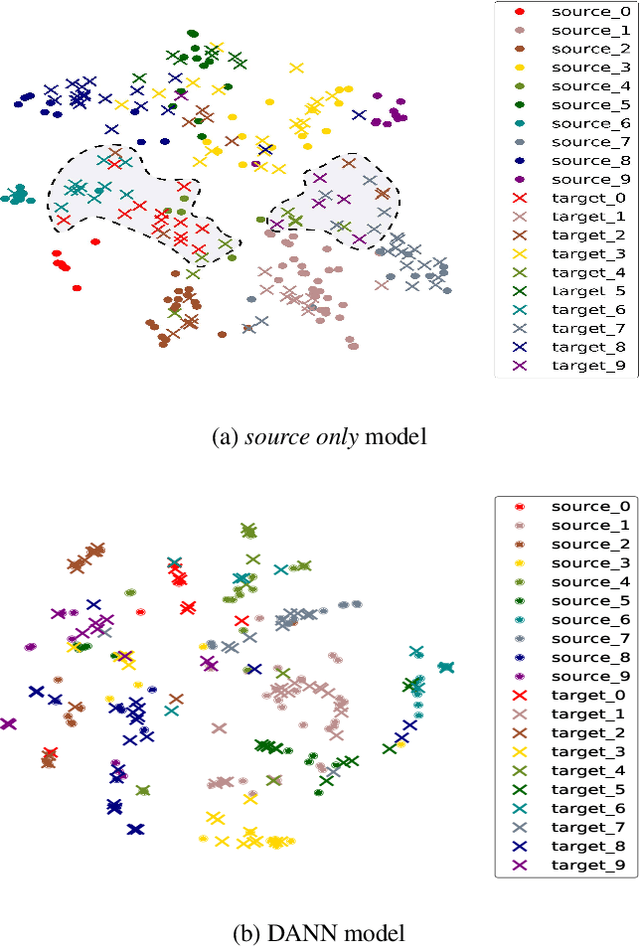
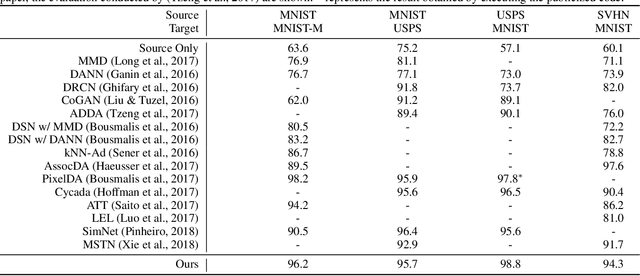
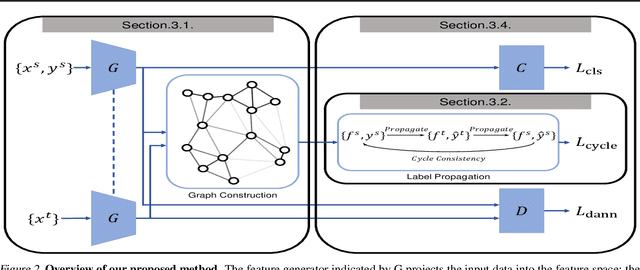
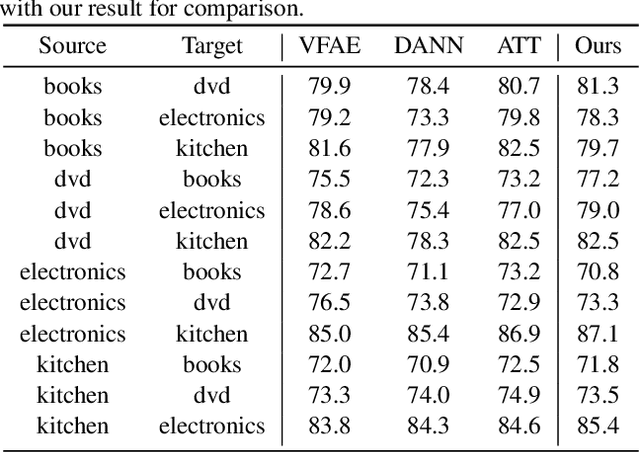
Unsupervised domain adaptation aiming to learn a specific task for one domain using another domain data has emerged to address the labeling issue in supervised learning, especially because it is difficult to obtain massive amounts of labeled data in practice. The existing methods have succeeded by reducing the difference between the embedded features of both domains, but the performance is still unsatisfactory compared to the supervised learning scheme. This is attributable to the embedded features that lay around each other but do not align perfectly and establish clearly separable clusters. We propose a novel domain adaptation method based on label propagation and cycle consistency to let the clusters of the features from the two domains overlap exactly and become clear for high accuracy. Specifically, we introduce cycle consistency to enforce the relationship between each cluster and exploit label propagation to achieve the association between the data from the perspective of the manifold structure instead of a one-to-one relation. Hence, we successfully formed aligned and discriminative clusters. We present the empirical results of our method for various domain adaptation scenarios and visualize the embedded features to prove that our method is critical for better domain adaptation.
Memory-Augmented Neural Networks for Knowledge Tracing from the Perspective of Learning and Forgetting
Oct 01, 2018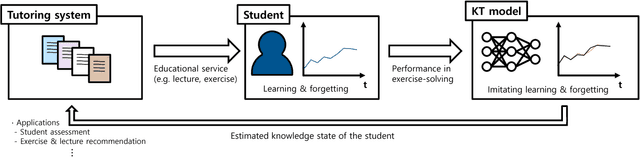



Knowledge tracing (KT) refers to a machine learning technique to assess a student's level of understanding (or knowledge state) based on the student's past performance in exercise-solving. KT accepts a series of question-answer pairs as an input and iteratively updates the knowledge state of the student, eventually returning the probability of the student solving a given question. To estimate the accurate knowledge state, a KT model should imitate the learning and forgetting mechanisms of the student. Deep learning-based KT models, proposed recently, show a higher predictive performance than traditional machine learning-based KT models due to the representative power of neural networks. The dynamic key value memory network (DKVMN), a kind of memory augmented neural network (MANN), is a state-of-the-art KT model, but it has some limitations. DKVMN does not utilize information from a current knowledge state and overestimates the amount of forgetting when updating the knowledge state. To improve the learning and forgetting mechanism of the DKVMN, we propose a knowledge tracing model that incorporates: (1) an adaptive knowledge growth depending on the current knowledge state, and (2) an additional loss term that can regularize the degree of forgetting. To measure the degree of forgetting of the KT model, we define a positive update ratio (PUR) that can complement the predictive performance metric (AUC). According to our experiments using four public benchmarks, the proposed approaches outperform the original DKVMN in terms of both AUC (predictive performance) and PUR (degree of forgetting).
How Generative Adversarial Networks and Their Variants Work: An Overview of GAN
Jul 27, 2018

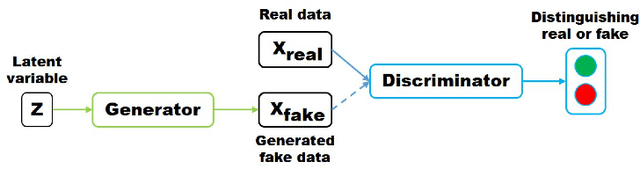
Generative Adversarial Networks (GAN) have received wide attention in the machine learning field for their potential to learn high-dimensional, complex real data distribution. Specifically, they do not rely on any assumptions about the distribution and can generate real-like samples from latent space in a simple manner. This powerful property leads GAN to be applied to various applications such as image synthesis, image attribute editing, image translation, domain adaptation and other academic fields. In this paper, we aim to discuss the details of GAN for those readers who are familiar with, but do not comprehend GAN deeply or who wish to view GAN from various perspectives. In addition, we explain how GAN operates and the fundamental meaning of various objective functions that have been suggested recently. We then focus on how the GAN can be combined with an autoencoder framework. Finally, we enumerate the GAN variants that are applied to various tasks and other fields for those who are interested in exploiting GAN for their research.
Domain Adaptation Using Adversarial Learning for Autonomous Navigation
May 22, 2018
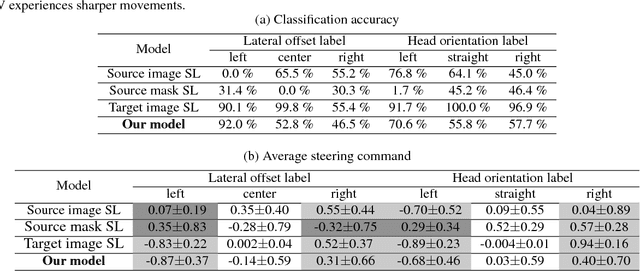
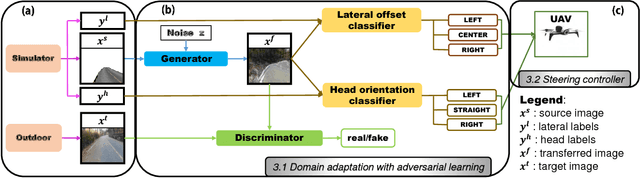

Autonomous navigation has become an increasingly popular machine learning application. Recent advances in deep learning have also resulted in great improvements to autonomous navigation. However, prior outdoor autonomous navigation depends on various expensive sensors or large amounts of real labeled data which is difficult to acquire and sometimes erroneous. The objective of this study is to train an autonomous navigation model that uses a simulator (instead of real labeled data) and an inexpensive monocular camera. In order to exploit the simulator satisfactorily, our proposed method is based on domain adaptation with adversarial learning. Specifically, we propose our model with 1) a dilated residual block in the generator, 2) cycle loss, and 3) style loss to improve the adversarial learning performance for satisfactory domain adaptation. In addition, we perform a theoretical analysis that supports the justification of our proposed method. We present empirical results of navigation in outdoor courses with various intersections using a commercial radio controlled car. We observe that our proposed method allows us to learn a favorable navigation model by generating images with realistic textures. To the best of our knowledge, this is the first work to apply domain adaptation with adversarial learning to autonomous navigation in real outdoor environments. Our proposed method can also be applied to precise image generation or other robotic tasks.