 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemoving Undesirable Feature Contributions Using Out-of-Distribution Data
Jan 17, 2021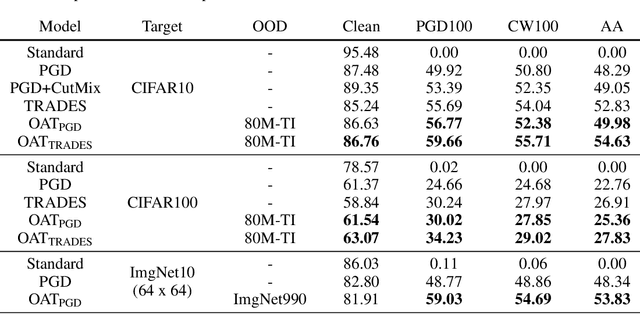
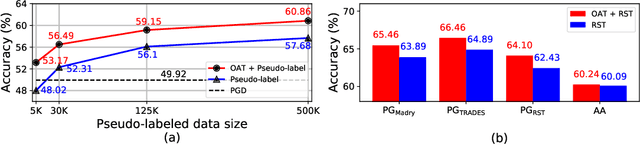

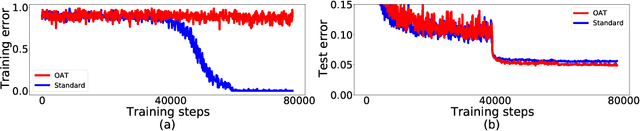
Several data augmentation methods deploy unlabeled-in-distribution (UID) data to bridge the gap between the training and inference of neural networks. However, these methods have clear limitations in terms of availability of UID data and dependence of algorithms on pseudo-labels. Herein, we propose a data augmentation method to improve generalization in both adversarial and standard learning by using out-of-distribution (OOD) data that are devoid of the abovementioned issues. We show how to improve generalization theoretically using OOD data in each learning scenario and complement our theoretical analysis with experiments on CIFAR-10, CIFAR-100, and a subset of ImageNet. The results indicate that undesirable features are shared even among image data that seem to have little correlation from a human point of view. We also present the advantages of the proposed method through comparison with other data augmentation methods, which can be used in the absence of UID data. Furthermore, we demonstrate that the proposed method can further improve the existing state-of-the-art adversarial training.
Joint Contrastive Learning for Unsupervised Domain Adaptation
Jun 18, 2020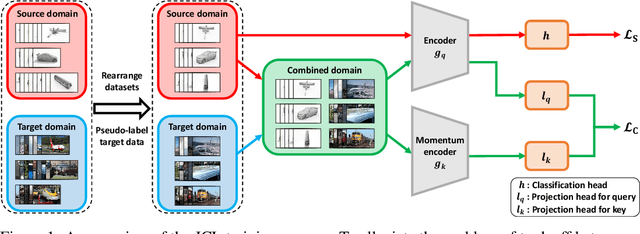
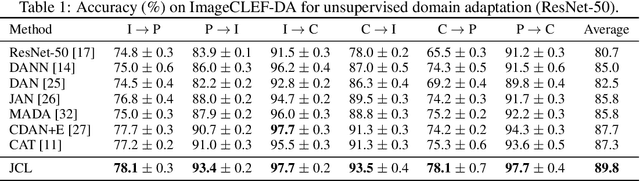
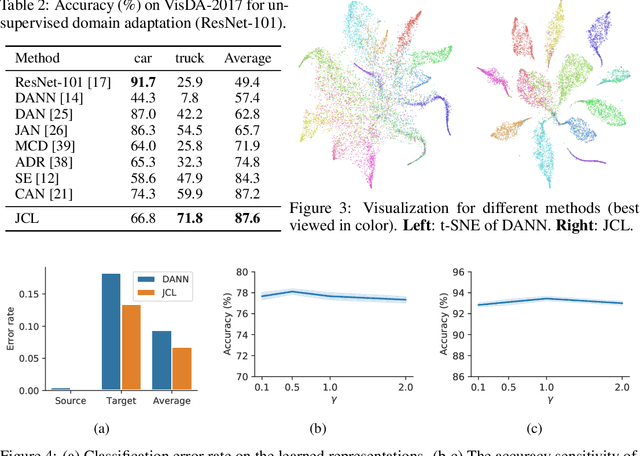

Enhancing feature transferability by matching marginal distributions has led to improvements in domain adaptation, although this is at the expense of feature discrimination. In particular, the ideal joint hypothesis error in the target error upper bound, which was previously considered to be minute, has been found to be significant, impairing its theoretical guarantee. In this paper, we propose an alternative upper bound on the target error that explicitly considers the joint error to render it more manageable. With the theoretical analysis, we suggest a joint optimization framework that combines the source and target domains. Further, we introduce Joint Contrastive Learning (JCL) to find class-level discriminative features, which is essential for minimizing the joint error. With a solid theoretical framework, JCL employs contrastive loss to maximize the mutual information between a feature and its label, which is equivalent to maximizing the Jensen-Shannon divergence between conditional distributions. Experiments on two real-world datasets demonstrate that JCL outperforms the state-of-the-art methods.
Learning Condensed and Aligned Features for Unsupervised Domain Adaptation Using Label Propagation
Mar 12, 2019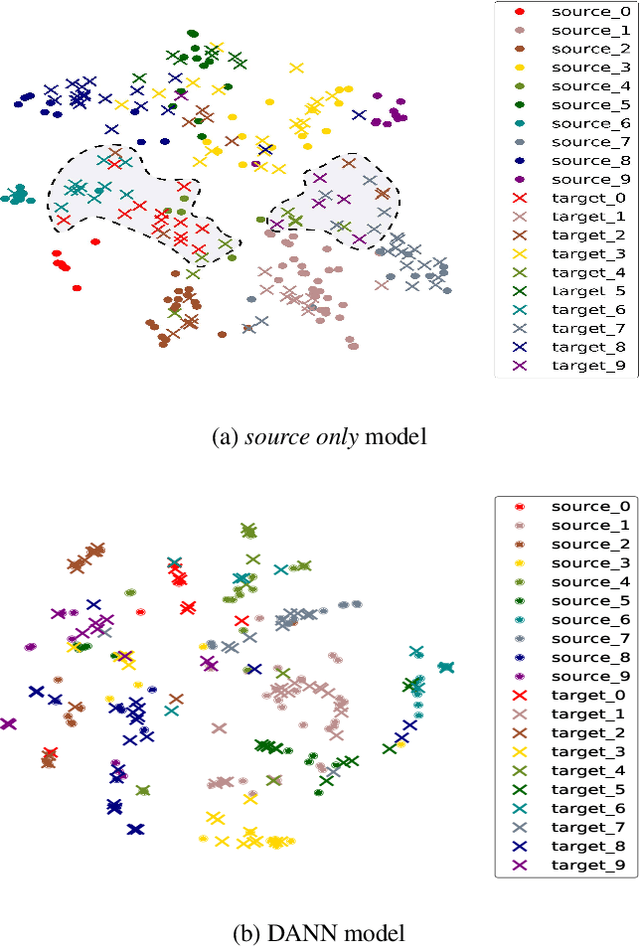
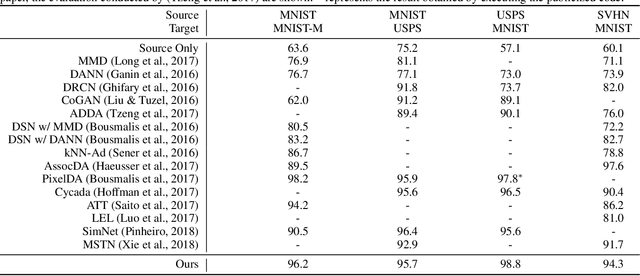
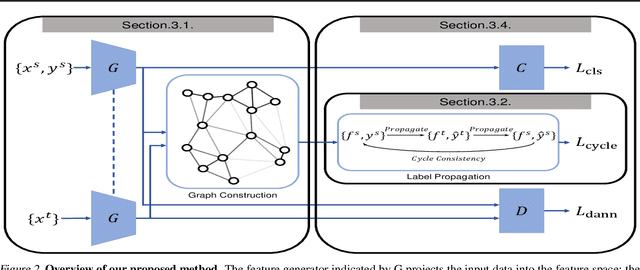
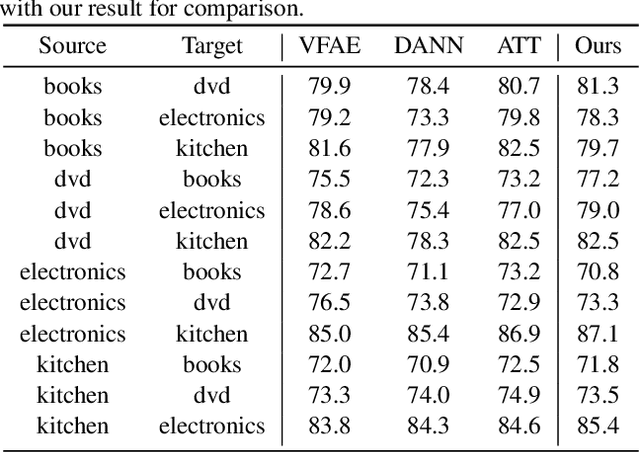
Unsupervised domain adaptation aiming to learn a specific task for one domain using another domain data has emerged to address the labeling issue in supervised learning, especially because it is difficult to obtain massive amounts of labeled data in practice. The existing methods have succeeded by reducing the difference between the embedded features of both domains, but the performance is still unsatisfactory compared to the supervised learning scheme. This is attributable to the embedded features that lay around each other but do not align perfectly and establish clearly separable clusters. We propose a novel domain adaptation method based on label propagation and cycle consistency to let the clusters of the features from the two domains overlap exactly and become clear for high accuracy. Specifically, we introduce cycle consistency to enforce the relationship between each cluster and exploit label propagation to achieve the association between the data from the perspective of the manifold structure instead of a one-to-one relation. Hence, we successfully formed aligned and discriminative clusters. We present the empirical results of our method for various domain adaptation scenarios and visualize the embedded features to prove that our method is critical for better domain adaptation.